使用 Apache Kafka Streams
本指南演示了您的 Quarkus 应用程序如何利用 Apache Kafka Streams API 来实现基于 Apache Kafka 的流处理应用程序。
先决条件
要完成本指南,您需要
-
大约 30 分钟
-
一个 IDE
-
已安装 JDK 17+ 并正确配置了
JAVA_HOME -
Apache Maven 3.9.9
-
Docker 和 Docker Compose 或 Podman,以及 Docker Compose
-
如果您想使用它,可以选择 Quarkus CLI
-
如果您想构建本机可执行文件(或者如果您使用本机容器构建,则为 Docker),可以选择安装 Mandrel 或 GraalVM 并进行适当的配置
建议您先阅读 Kafka 快速入门。
|
Kafka Streams 的 Quarkus 扩展通过支持 Quarkus Dev Mode(例如,通过 推荐的开发设置是拥有一些生产者,它们以固定的间隔(例如每秒)在已处理的主题上创建测试消息,并使用诸如 为了获得最佳的开发体验,我们建议将以下配置设置应用于您的 Kafka 代理 还在您的 Quarkus 这些设置共同确保应用程序在开发模式下重新启动后可以非常快速地重新连接到代理。 |
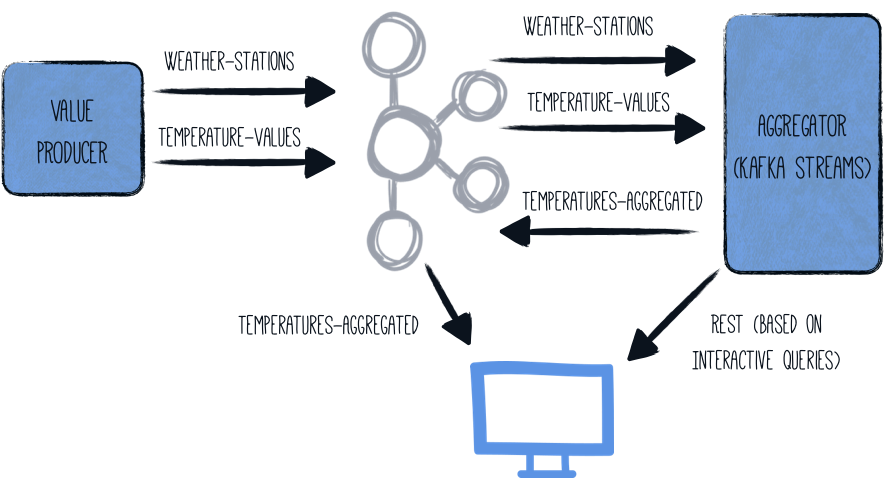
架构
在本指南中,我们将在一个组件(名为 generator)中生成(随机)温度值。 这些值与给定的气象站相关联,并写入 Kafka 主题 (temperature-values)。 另一个主题 (weather-stations) 仅包含有关气象站本身的主要数据(ID 和名称)。
第二个组件 (aggregator) 从两个 Kafka 主题读取数据,并在流式管道中处理它们
-
两个主题在气象站 ID 上连接
-
确定每个气象站的最低、最高和平均温度
-
此聚合数据将写入第三个主题 (
temperatures-aggregated)
可以通过检查输出主题来检查数据。 通过公开 Kafka Streams 交互式查询,也可以通过简单的 REST 查询获得每个气象站的最新结果。
总体架构如下所示
解决方案
我们建议您按照以下章节中的说明,逐步创建应用程序。但是,您可以直接转到完整的示例。
克隆 Git 存储库:git clone https://github.com/quarkusio/quarkus-quickstarts.git,或下载 归档。
解决方案位于 kafka-streams-quickstart 目录中。
创建生产者 Maven 项目
首先,我们需要一个带有温度值生产者的新项目。 使用以下命令创建一个新项目
对于 Windows 用户
-
如果使用 cmd,(不要使用反斜杠
\并将所有内容放在同一行上) -
如果使用 Powershell,请将
-D参数括在双引号中,例如"-DprojectArtifactId=kafka-streams-quickstart-producer"
此命令生成一个 Maven 项目,导入 Reactive Messaging 和 Kafka 连接器扩展。
如果您已经配置了 Quarkus 项目,则可以通过在项目基本目录中运行以下命令将 messaging-kafka 扩展添加到您的项目中
quarkus extension add quarkus-messaging-kafka./mvnw quarkus:add-extension -Dextensions='quarkus-messaging-kafka'./gradlew addExtension --extensions='quarkus-messaging-kafka'这会将以下内容添加到您的构建文件中
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-messaging-kafka</artifactId>
</dependency>implementation("io.quarkus:quarkus-messaging-kafka")温度值生产者
创建 producer/src/main/java/org/acme/kafka/streams/producer/generator/ValuesGenerator.java 文件,内容如下
package org.acme.kafka.streams.producer.generator;
import java.math.BigDecimal;
import java.math.RoundingMode;
import java.time.Duration;
import java.time.Instant;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
import java.util.Random;
import jakarta.enterprise.context.ApplicationScoped;
import io.smallrye.mutiny.Multi;
import io.smallrye.reactive.messaging.kafka.Record;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
import org.jboss.logging.Logger;
/**
* A bean producing random temperature data every second.
* The values are written to a Kafka topic (temperature-values).
* Another topic contains the name of weather stations (weather-stations).
* The Kafka configuration is specified in the application configuration.
*/
@ApplicationScoped
public class ValuesGenerator {
private static final Logger LOG = Logger.getLogger(ValuesGenerator.class);
private Random random = new Random();
private List<WeatherStation> stations = List.of(
new WeatherStation(1, "Hamburg", 13),
new WeatherStation(2, "Snowdonia", 5),
new WeatherStation(3, "Boston", 11),
new WeatherStation(4, "Tokio", 16),
new WeatherStation(5, "Cusco", 12),
new WeatherStation(6, "Svalbard", -7),
new WeatherStation(7, "Porthsmouth", 11),
new WeatherStation(8, "Oslo", 7),
new WeatherStation(9, "Marrakesh", 20));
@Outgoing("temperature-values") (1)
public Multi<Record<Integer, String>> generate() {
return Multi.createFrom().ticks().every(Duration.ofMillis(500)) (2)
.onOverflow().drop()
.map(tick -> {
WeatherStation station = stations.get(random.nextInt(stations.size()));
double temperature = BigDecimal.valueOf(random.nextGaussian() * 15 + station.averageTemperature)
.setScale(1, RoundingMode.HALF_UP)
.doubleValue();
LOG.infov("station: {0}, temperature: {1}", station.name, temperature);
return Record.of(station.id, Instant.now() + ";" + temperature);
});
}
@Outgoing("weather-stations") (3)
public Multi<Record<Integer, String>> weatherStations() {
return Multi.createFrom().items(stations.stream()
.map(s -> Record.of(
s.id,
"{ \"id\" : " + s.id +
", \"name\" : \"" + s.name + "\" }"))
);
}
private static class WeatherStation {
int id;
String name;
int averageTemperature;
public WeatherStation(int id, String name, int averageTemperature) {
this.id = id;
this.name = name;
this.averageTemperature = averageTemperature;
}
}
}| 1 | 指示 Reactive Messaging 将返回的 Multi 中的项目分派到 temperature-values。 |
| 2 | 该方法返回一个 Mutiny *stream* (Multi),每 0.5 秒发出一个随机温度值。 |
| 3 | 指示 Reactive Messaging 将返回的 Multi(气象站的静态列表)中的项目分派到 weather-stations。 |
这两种方法都返回一个*reactive stream*,其项目分别发送到名为 temperature-values 和 weather-stations 的流。
主题配置
两个通道都使用 Quarkus 配置文件 application.properties 映射到 Kafka 主题。 为此,将以下内容添加到文件 producer/src/main/resources/application.properties
# Configure the Kafka broker location
kafka.bootstrap.servers=localhost:9092
mp.messaging.outgoing.temperature-values.connector=smallrye-kafka
mp.messaging.outgoing.temperature-values.key.serializer=org.apache.kafka.common.serialization.IntegerSerializer
mp.messaging.outgoing.temperature-values.value.serializer=org.apache.kafka.common.serialization.StringSerializer
mp.messaging.outgoing.weather-stations.connector=smallrye-kafka
mp.messaging.outgoing.weather-stations.key.serializer=org.apache.kafka.common.serialization.IntegerSerializer
mp.messaging.outgoing.weather-stations.value.serializer=org.apache.kafka.common.serialization.StringSerializer创建聚合器 Maven 项目
完成生产者应用程序后,就该实现实际的聚合器应用程序了,该应用程序将运行 Kafka Streams 管道。 像这样创建另一个项目
对于 Windows 用户
-
如果使用 cmd,(不要使用反斜杠
\并将所有内容放在同一行上) -
如果使用 Powershell,请将
-D参数括在双引号中,例如"-DprojectArtifactId=kafka-streams-quickstart-aggregator"
这将创建带有 Kafka Streams 的 Quarkus 扩展和 Quarkus REST(以前称为 RESTEasy Reactive)的 Jackson 支持的 aggregator 项目。
如果您已经配置了 Quarkus 项目,则可以通过在项目基本目录中运行以下命令将 kafka-streams 扩展添加到您的项目中
quarkus extension add kafka-streams./mvnw quarkus:add-extension -Dextensions='kafka-streams'./gradlew addExtension --extensions='kafka-streams'这会将以下内容添加到您的 pom.xml 中
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-kafka-streams</artifactId>
</dependency>implementation("io.quarkus:quarkus-kafka-streams")管道实现
让我们开始实现流处理应用程序,方法是创建一些值对象,用于表示温度测量值、气象站和跟踪聚合值。
首先,创建文件 aggregator/src/main/java/org/acme/kafka/streams/aggregator/model/WeatherStation.java,表示气象站,内容如下
package org.acme.kafka.streams.aggregator.model;
import io.quarkus.runtime.annotations.RegisterForReflection;
@RegisterForReflection (1)
public class WeatherStation {
public int id;
public String name;
}| 1 | @RegisterForReflection 注释指示 Quarkus 在本机编译期间保留类及其成员。 有关 @RegisterForReflection 注释的更多详细信息,请参见 本机应用程序提示 页面。 |
然后创建文件 aggregator/src/main/java/org/acme/kafka/streams/aggregator/model/TemperatureMeasurement.java,表示给定站的温度测量值
package org.acme.kafka.streams.aggregator.model;
import java.time.Instant;
public class TemperatureMeasurement {
public int stationId;
public String stationName;
public Instant timestamp;
public double value;
public TemperatureMeasurement(int stationId, String stationName, Instant timestamp,
double value) {
this.stationId = stationId;
this.stationName = stationName;
this.timestamp = timestamp;
this.value = value;
}
}最后创建 aggregator/src/main/java/org/acme/kafka/streams/aggregator/model/Aggregation.java,它将用于在事件在流式管道中处理时跟踪聚合值
package org.acme.kafka.streams.aggregator.model;
import java.math.BigDecimal;
import java.math.RoundingMode;
import io.quarkus.runtime.annotations.RegisterForReflection;
@RegisterForReflection
public class Aggregation {
public int stationId;
public String stationName;
public double min = Double.MAX_VALUE;
public double max = Double.MIN_VALUE;
public int count;
public double sum;
public double avg;
public Aggregation updateFrom(TemperatureMeasurement measurement) {
stationId = measurement.stationId;
stationName = measurement.stationName;
count++;
sum += measurement.value;
avg = BigDecimal.valueOf(sum / count)
.setScale(1, RoundingMode.HALF_UP).doubleValue();
min = Math.min(min, measurement.value);
max = Math.max(max, measurement.value);
return this;
}
}接下来,让我们在 aggregator/src/main/java/org/acme/kafka/streams/aggregator/streams/TopologyProducer.java 文件中创建实际的流式查询实现本身。 我们需要做的就是声明一个 CDI 生产者方法,该方法返回 Kafka Streams Topology; Quarkus 扩展将负责配置、启动和停止实际的 Kafka Streams 引擎。
package org.acme.kafka.streams.aggregator.streams;
import java.time.Instant;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.enterprise.inject.Produces;
import org.acme.kafka.streams.aggregator.model.Aggregation;
import org.acme.kafka.streams.aggregator.model.TemperatureMeasurement;
import org.acme.kafka.streams.aggregator.model.WeatherStation;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.Topology;
import org.apache.kafka.streams.kstream.Consumed;
import org.apache.kafka.streams.kstream.GlobalKTable;
import org.apache.kafka.streams.kstream.Materialized;
import org.apache.kafka.streams.kstream.Produced;
import org.apache.kafka.streams.state.KeyValueBytesStoreSupplier;
import org.apache.kafka.streams.state.Stores;
import io.quarkus.kafka.client.serialization.ObjectMapperSerde;
@ApplicationScoped
public class TopologyProducer {
static final String WEATHER_STATIONS_STORE = "weather-stations-store";
private static final String WEATHER_STATIONS_TOPIC = "weather-stations";
private static final String TEMPERATURE_VALUES_TOPIC = "temperature-values";
private static final String TEMPERATURES_AGGREGATED_TOPIC = "temperatures-aggregated";
@Produces
public Topology buildTopology() {
StreamsBuilder builder = new StreamsBuilder();
ObjectMapperSerde<WeatherStation> weatherStationSerde = new ObjectMapperSerde<>(
WeatherStation.class);
ObjectMapperSerde<Aggregation> aggregationSerde = new ObjectMapperSerde<>(Aggregation.class);
KeyValueBytesStoreSupplier storeSupplier = Stores.persistentKeyValueStore(
WEATHER_STATIONS_STORE);
GlobalKTable<Integer, WeatherStation> stations = builder.globalTable( (1)
WEATHER_STATIONS_TOPIC,
Consumed.with(Serdes.Integer(), weatherStationSerde));
builder.stream( (2)
TEMPERATURE_VALUES_TOPIC,
Consumed.with(Serdes.Integer(), Serdes.String())
)
.join( (3)
stations,
(stationId, timestampAndValue) -> stationId,
(timestampAndValue, station) -> {
String[] parts = timestampAndValue.split(";");
return new TemperatureMeasurement(station.id, station.name,
Instant.parse(parts[0]), Double.valueOf(parts[1]));
}
)
.groupByKey() (4)
.aggregate( (5)
Aggregation::new,
(stationId, value, aggregation) -> aggregation.updateFrom(value),
Materialized.<Integer, Aggregation> as(storeSupplier)
.withKeySerde(Serdes.Integer())
.withValueSerde(aggregationSerde)
)
.toStream()
.to( (6)
TEMPERATURES_AGGREGATED_TOPIC,
Produced.with(Serdes.Integer(), aggregationSerde)
);
return builder.build();
}
}| 1 | weather-stations 表被读入 GlobalKTable,表示每个气象站的当前状态 |
| 2 | temperature-values 主题被读入 KStream; 每当新消息到达该主题时,将为此测量处理管道 |
| 3 | 来自 temperature-values 主题的消息使用主题的键(气象站 ID)与相应的气象站连接; 连接结果包含来自测量值和关联的气象站消息的数据 |
| 4 | 这些值按消息键(气象站 ID)分组 |
| 5 | 在每个组中,通过跟踪最小值和最大值并计算该站所有测量值的平均值(请参见 Aggregation 类型),对该站的所有测量值进行聚合 |
| 6 | 管道的结果将写入 temperatures-aggregated 主题 |
Kafka Streams 扩展通过 Quarkus 配置文件 application.properties 进行配置。 创建带有以下内容的文件 aggregator/src/main/resources/application.properties
quarkus.kafka-streams.bootstrap-servers=localhost:9092
quarkus.kafka-streams.application-server=${hostname}:8080
quarkus.kafka-streams.topics=weather-stations,temperature-values
# pass-through options
kafka-streams.cache.max.bytes.buffering=10240
kafka-streams.commit.interval.ms=1000
kafka-streams.metadata.max.age.ms=500
kafka-streams.auto.offset.reset=earliest
kafka-streams.metrics.recording.level=DEBUG带有 quarkus.kafka-streams 前缀的选项可以在应用程序启动时动态更改,例如,通过环境变量或系统属性。 bootstrap-servers 和 application-server 分别映射到 Kafka Streams 属性 bootstrap.servers 和 application.server。 topics 是 Quarkus 特有的:应用程序将等待所有给定的主题存在,然后启动 Kafka Streams 引擎。 这样做是为了优雅地等待在应用程序启动时尚不存在的主题的创建。
或者,您可以使用 kafka.bootstrap.servers 而不是 quarkus.kafka-streams.bootstrap-servers,就像在上面的 *generator* 项目中所做的那样。 |
|
准备好将应用程序推广到生产环境后,请考虑更改上述配置值。 虽然 |
kafka-streams 命名空间中的所有属性都按原样传递到 Kafka Streams 引擎。 更改它们的值需要重建应用程序。
构建和运行应用程序
我们现在可以构建 producer 和 aggregator 应用程序
./mvnw clean package -f producer/pom.xml
./mvnw clean package -f aggregator/pom.xml我们将它们打包到容器镜像中并通过 Docker Compose 启动它们,而不是使用 Quarkus 开发模式直接在主机上运行它们。 这样做是为了演示稍后将 aggregator 聚合扩展到多个节点。
Quarkus 默认创建的 Dockerfile 需要对 aggregator 应用程序进行一项调整才能运行 Kafka Streams 管道。 为此,请编辑文件 aggregator/src/main/docker/Dockerfile.jvm 并将行 FROM fabric8/java-alpine-openjdk8-jre 替换为 FROM fabric8/java-centos-openjdk8-jdk。
接下来,创建一个 Docker Compose 文件 (docker-compose.yaml) 以启动两个应用程序以及 Apache Kafka 和 ZooKeeper,如下所示
version: '3.5'
services:
zookeeper:
image: quay.io/strimzi/kafka:0.41.0-kafka-3.7.0
command: [
"sh", "-c",
"bin/zookeeper-server-start.sh config/zookeeper.properties"
]
ports:
- "2181:2181"
environment:
LOG_DIR: /tmp/logs
networks:
- kafkastreams-network
kafka:
image: quay.io/strimzi/kafka:0.41.0-kafka-3.7.0
command: [
"sh", "-c",
"bin/kafka-server-start.sh config/server.properties --override listeners=$${KAFKA_LISTENERS} --override advertised.listeners=$${KAFKA_ADVERTISED_LISTENERS} --override zookeeper.connect=$${KAFKA_ZOOKEEPER_CONNECT} --override num.partitions=$${KAFKA_NUM_PARTITIONS}"
]
depends_on:
- zookeeper
ports:
- "9092:9092"
environment:
LOG_DIR: "/tmp/logs"
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_NUM_PARTITIONS: 3
networks:
- kafkastreams-network
producer:
image: quarkus-quickstarts/kafka-streams-producer:1.0
build:
context: producer
dockerfile: src/main/docker/Dockerfile.${QUARKUS_MODE:-jvm}
environment:
KAFKA_BOOTSTRAP_SERVERS: kafka:9092
networks:
- kafkastreams-network
aggregator:
image: quarkus-quickstarts/kafka-streams-aggregator:1.0
build:
context: aggregator
dockerfile: src/main/docker/Dockerfile.${QUARKUS_MODE:-jvm}
environment:
QUARKUS_KAFKA_STREAMS_BOOTSTRAP_SERVERS: kafka:9092
networks:
- kafkastreams-network
networks:
kafkastreams-network:
name: ks要启动所有容器,构建 producer 和 aggregator 容器镜像,请运行 docker-compose up --build。
您可以改为使用 KAFKA_BOOTSTRAP_SERVERS 而不是 QUARKUS_KAFKA_STREAMS_BOOTSTRAP_SERVERS。 |
您应该会看到来自 producer 应用程序的有关消息已发送到 "temperature-values" 主题的日志语句。
现在运行一个 *debezium/tooling* 镜像实例,将其附加到所有其他容器运行所在的同一网络。 此镜像提供了几个有用的工具,例如 *kafkacat* 和 *httpie*
docker run --tty --rm -i --network ks debezium/tooling:1.1在 tooling 容器中,运行 *kafkacat* 以检查流式管道的结果
kafkacat -b kafka:9092 -C -o beginning -q -t temperatures-aggregated
{"avg":34.7,"count":4,"max":49.4,"min":16.8,"stationId":9,"stationName":"Marrakesh","sum":138.8}
{"avg":15.7,"count":1,"max":15.7,"min":15.7,"stationId":2,"stationName":"Snowdonia","sum":15.7}
{"avg":12.8,"count":7,"max":25.5,"min":-13.8,"stationId":7,"stationName":"Porthsmouth","sum":89.7}
...您应该会看到新值到达,因为生产者会继续发出温度测量值,出站主题上的每个值都显示了代表的气象站的最低、最高和平均温度值。
交互式查询
订阅 temperatures-aggregated 主题是响应任何新温度值的好方法。 但是,如果您只对给定气象站的最新聚合值感兴趣,则这有点浪费。 这正是 Kafka Streams 交互式查询的闪光点:它们允许您直接查询管道的底层状态存储,以获取与给定键关联的值。 通过公开一个查询状态存储的简单 REST 端点,可以检索最新聚合结果,而无需订阅任何 Kafka 主题。
让我们首先在文件 aggregator/src/main/java/org/acme/kafka/streams/aggregator/streams/InteractiveQueries.java 中创建一个新类 InteractiveQueries
将一个方法添加到 KafkaStreamsPipeline 类中,该方法获取给定键的当前状态
package org.acme.kafka.streams.aggregator.streams;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.inject.Inject;
import org.acme.kafka.streams.aggregator.model.Aggregation;
import org.acme.kafka.streams.aggregator.model.WeatherStationData;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.errors.InvalidStateStoreException;
import org.apache.kafka.streams.state.QueryableStoreTypes;
import org.apache.kafka.streams.state.ReadOnlyKeyValueStore;
@ApplicationScoped
public class InteractiveQueries {
@Inject
KafkaStreams streams;
public GetWeatherStationDataResult getWeatherStationData(int id) {
Aggregation result = getWeatherStationStore().get(id);
if (result != null) {
return GetWeatherStationDataResult.found(WeatherStationData.from(result)); (1)
}
else {
return GetWeatherStationDataResult.notFound(); (2)
}
}
private ReadOnlyKeyValueStore<Integer, Aggregation> getWeatherStationStore() {
while (true) {
try {
return streams.store(TopologyProducer.WEATHER_STATIONS_STORE, QueryableStoreTypes.keyValueStore());
} catch (InvalidStateStoreException e) {
// ignore, store not ready yet
}
}
}
}| 1 | 找到了给定站 ID 的值,因此将返回该值 |
| 2 | 未找到任何值,要么是因为查询了一个不存在的站,要么是因为给定站还没有测量值 |
还在文件 aggregator/src/main/java/org/acme/kafka/streams/aggregator/streams/GetWeatherStationDataResult.java 中创建该方法的返回类型
package org.acme.kafka.streams.aggregator.streams;
import java.util.Optional;
import java.util.OptionalInt;
import org.acme.kafka.streams.aggregator.model.WeatherStationData;
public class GetWeatherStationDataResult {
private static GetWeatherStationDataResult NOT_FOUND =
new GetWeatherStationDataResult(null);
private final WeatherStationData result;
private GetWeatherStationDataResult(WeatherStationData result) {
this.result = result;
}
public static GetWeatherStationDataResult found(WeatherStationData data) {
return new GetWeatherStationDataResult(data);
}
public static GetWeatherStationDataResult notFound() {
return NOT_FOUND;
}
public Optional<WeatherStationData> getResult() {
return Optional.ofNullable(result);
}
}还创建 aggregator/src/main/java/org/acme/kafka/streams/aggregator/model/WeatherStationData.java,它表示气象站的实际聚合结果
package org.acme.kafka.streams.aggregator.model;
import io.quarkus.runtime.annotations.RegisterForReflection;
@RegisterForReflection
public class WeatherStationData {
public int stationId;
public String stationName;
public double min = Double.MAX_VALUE;
public double max = Double.MIN_VALUE;
public int count;
public double avg;
private WeatherStationData(int stationId, String stationName, double min, double max,
int count, double avg) {
this.stationId = stationId;
this.stationName = stationName;
this.min = min;
this.max = max;
this.count = count;
this.avg = avg;
}
public static WeatherStationData from(Aggregation aggregation) {
return new WeatherStationData(
aggregation.stationId,
aggregation.stationName,
aggregation.min,
aggregation.max,
aggregation.count,
aggregation.avg);
}
}我们现在可以添加一个简单的 REST 端点 (aggregator/src/main/java/org/acme/kafka/streams/aggregator/rest/WeatherStationEndpoint.java),该端点调用 getWeatherStationData() 并将数据返回给客户端
package org.acme.kafka.streams.aggregator.rest;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.List;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.inject.Inject;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.core.MediaType;
import jakarta.ws.rs.core.Response;
import jakarta.ws.rs.core.Response.Status;
import org.acme.kafka.streams.aggregator.streams.GetWeatherStationDataResult;
import org.acme.kafka.streams.aggregator.streams.KafkaStreamsPipeline;
@ApplicationScoped
@Path("/weather-stations")
public class WeatherStationEndpoint {
@Inject
InteractiveQueries interactiveQueries;
@GET
@Path("/data/{id}")
public Response getWeatherStationData(int id) {
GetWeatherStationDataResult result = interactiveQueries.getWeatherStationData(id);
if (result.getResult().isPresent()) { (1)
return Response.ok(result.getResult().get()).build();
}
else {
return Response.status(Status.NOT_FOUND.getStatusCode(),
"No data found for weather station " + id).build();
}
}
}| 1 | 根据是否获得值,返回该值或 404 响应 |
完成此代码后,就可以在 Docker Compose 中重建应用程序和 aggregator 服务
./mvnw clean package -f aggregator/pom.xml
docker-compose stop aggregator
docker-compose up --build -d这将重建 aggregator 容器并重新启动其服务。 完成后,您可以调用该服务的 REST API 以获取现有站之一的温度数据。 为此,您可以使用之前启动的 tooling 容器中的 httpie
http aggregator:8080/weather-stations/data/1
HTTP/1.1 200 OK
Connection: keep-alive
Content-Length: 85
Content-Type: application/json
Date: Tue, 18 Jun 2019 19:29:16 GMT
{
"avg": 12.9,
"count": 146,
"max": 41.0,
"min": -25.6,
"stationId": 1,
"stationName": "Hamburg"
}横向扩展
Kafka Streams 应用程序的一个非常有趣的特性是它们可以横向扩展,也就是说,负载和状态可以在运行相同管道的多个应用程序实例之间分配。 然后,每个节点将包含聚合结果的子集,但是 Kafka Streams 为您提供 一个 API,用于获取哪个节点托管给定键的信息。 然后,应用程序可以直接从另一个实例获取数据,或者只是将客户端指向该另一个节点的位置。
启动 aggregator 应用程序的多个实例将使整体架构看起来像这样
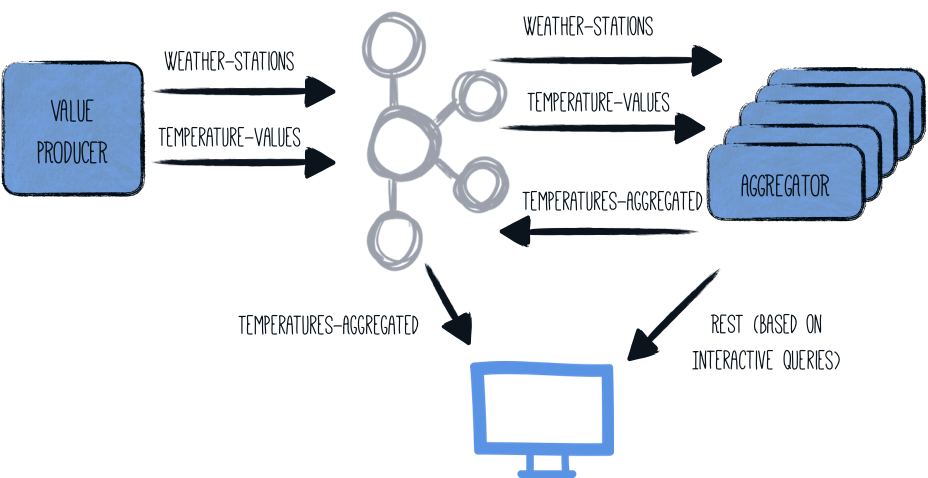
InteractiveQueries 类必须针对此分布式架构进行稍微调整
public GetWeatherStationDataResult getWeatherStationData(int id) {
StreamsMetadata metadata = streams.metadataForKey( (1)
TopologyProducer.WEATHER_STATIONS_STORE,
id,
Serdes.Integer().serializer()
);
if (metadata == null || metadata == StreamsMetadata.NOT_AVAILABLE) {
LOG.warn("Found no metadata for key {}", id);
return GetWeatherStationDataResult.notFound();
}
else if (metadata.host().equals(host)) { (2)
LOG.info("Found data for key {} locally", id);
Aggregation result = getWeatherStationStore().get(id);
if (result != null) {
return GetWeatherStationDataResult.found(WeatherStationData.from(result));
}
else {
return GetWeatherStationDataResult.notFound();
}
}
else { (3)
LOG.info(
"Found data for key {} on remote host {}:{}",
id,
metadata.host(),
metadata.port()
);
return GetWeatherStationDataResult.foundRemotely(metadata.host(), metadata.port());
}
}
public List<PipelineMetadata> getMetaData() { (4)
return streams.allMetadataForStore(TopologyProducer.WEATHER_STATIONS_STORE)
.stream()
.map(m -> new PipelineMetadata(
m.hostInfo().host() + ":" + m.hostInfo().port(),
m.topicPartitions()
.stream()
.map(TopicPartition::toString)
.collect(Collectors.toSet()))
)
.collect(Collectors.toList());
}| 1 | 获取给定气象站 ID 的流元数据 |
| 2 | 给定的键(气象站 ID)由本地应用程序节点维护,也就是说,它可以自己回答查询 |
| 3 | 给定的键由另一个应用程序节点维护; 在这种情况下,将返回有关该节点的信息(主机和端口) |
| 4 | getMetaData() 方法已添加,以向调用者提供应用程序集群中所有节点的列表。 |
必须相应地调整 GetWeatherStationDataResult 类型
package org.acme.kafka.streams.aggregator.streams;
import java.util.Optional;
import java.util.OptionalInt;
import org.acme.kafka.streams.aggregator.model.WeatherStationData;
public class GetWeatherStationDataResult {
private static GetWeatherStationDataResult NOT_FOUND =
new GetWeatherStationDataResult(null, null, null);
private final WeatherStationData result;
private final String host;
private final Integer port;
private GetWeatherStationDataResult(WeatherStationData result, String host,
Integer port) {
this.result = result;
this.host = host;
this.port = port;
}
public static GetWeatherStationDataResult found(WeatherStationData data) {
return new GetWeatherStationDataResult(data, null, null);
}
public static GetWeatherStationDataResult foundRemotely(String host, int port) {
return new GetWeatherStationDataResult(null, host, port);
}
public static GetWeatherStationDataResult notFound() {
return NOT_FOUND;
}
public Optional<WeatherStationData> getResult() {
return Optional.ofNullable(result);
}
public Optional<String> getHost() {
return Optional.ofNullable(host);
}
public OptionalInt getPort() {
return port != null ? OptionalInt.of(port) : OptionalInt.empty();
}
}此外,必须定义 getMetaData() 的返回类型 (aggregator/src/main/java/org/acme/kafka/streams/aggregator/streams/PipelineMetadata.java)
package org.acme.kafka.streams.aggregator.streams;
import java.util.Set;
public class PipelineMetadata {
public String host;
public Set<String> partitions;
public PipelineMetadata(String host, Set<String> partitions) {
this.host = host;
this.partitions = partitions;
}
}最后,必须更新 REST 端点类
package org.acme.kafka.streams.aggregator.rest;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.List;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.inject.Inject;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import jakarta.ws.rs.core.Response;
import jakarta.ws.rs.core.Response.Status;
import org.acme.kafka.streams.aggregator.streams.GetWeatherStationDataResult;
import org.acme.kafka.streams.aggregator.streams.KafkaStreamsPipeline;
import org.acme.kafka.streams.aggregator.streams.PipelineMetadata;
@ApplicationScoped
@Path("/weather-stations")
public class WeatherStationEndpoint {
@Inject
InteractiveQueries interactiveQueries;
@GET
@Path("/data/{id}")
@Consumes(MediaType.APPLICATION_JSON)
@Produces(MediaType.APPLICATION_JSON)
public Response getWeatherStationData(int id) {
GetWeatherStationDataResult result = interactiveQueries.getWeatherStationData(id);
if (result.getResult().isPresent()) { (1)
return Response.ok(result.getResult().get()).build();
}
else if (result.getHost().isPresent()) { (2)
URI otherUri = getOtherUri(result.getHost().get(), result.getPort().getAsInt(),
id);
return Response.seeOther(otherUri).build();
}
else { (3)
return Response.status(Status.NOT_FOUND.getStatusCode(),
"No data found for weather station " + id).build();
}
}
@GET
@Path("/meta-data")
@Produces(MediaType.APPLICATION_JSON)
public List<PipelineMetadata> getMetaData() { (4)
return interactiveQueries.getMetaData();
}
private URI getOtherUri(String host, int port, int id) {
try {
return new URI("http://" + host + ":" + port + "/weather-stations/data/" + id);
}
catch (URISyntaxException e) {
throw new RuntimeException(e);
}
}
}| 1 | 在本地找到了数据,因此将其返回 |
| 2 | 数据由另一个节点维护,因此如果给定键的数据存储在其他节点之一上,则回复重定向(HTTP 状态代码 303)。 |
| 3 | 未找到给定气象站 ID 的数据 |
| 4 | 公开有关形成应用程序集群的所有主机的信息 |
现在再次停止 aggregator 服务并重建它。 然后让我们启动它的三个实例
./mvnw clean package -f aggregator/pom.xml
docker-compose stop aggregator
docker-compose up --build -d --scale aggregator=3在三个实例中的任何一个上调用 REST API 时,请求的气象站 ID 的聚合可能存储在接收查询的节点本地,或者可能存储在其他两个节点之一上。
由于 Docker Compose 的负载均衡器将以轮询方式将请求分发到 aggregator 服务,因此我们将直接调用实际节点。 应用程序通过 REST 公开有关所有主机名的信息
http aggregator:8080/weather-stations/meta-data
HTTP/1.1 200 OK
Connection: keep-alive
Content-Length: 202
Content-Type: application/json
Date: Tue, 18 Jun 2019 20:00:23 GMT
[
{
"host": "2af13fe516a9:8080",
"partitions": [
"temperature-values-2"
]
},
{
"host": "32cc8309611b:8080",
"partitions": [
"temperature-values-1"
]
},
{
"host": "1eb39af8d587:8080",
"partitions": [
"temperature-values-0"
]
}
]从响应中显示的三个主机之一检索数据(您的实际主机名将有所不同)
http 2af13fe516a9:8080/weather-stations/data/1如果该节点保存了键 "1" 的数据,您将收到如下响应
HTTP/1.1 200 OK
Connection: keep-alive
Content-Length: 74
Content-Type: application/json
Date: Tue, 11 Jun 2019 19:16:31 GMT
{
"avg": 11.9,
"count": 259,
"max": 50.0,
"min": -30.1,
"stationId": 1,
"stationName": "Hamburg"
}否则,该服务将发送重定向
HTTP/1.1 303 See Other
Connection: keep-alive
Content-Length: 0
Date: Tue, 18 Jun 2019 20:01:03 GMT
Location: http://1eb39af8d587:8080/weather-stations/data/1您还可以让 *httpie* 通过传递 --follow option 自动遵循重定向
http --follow 2af13fe516a9:8080/weather-stations/data/1以本机方式运行
Kafka Streams 的 Quarkus 扩展允许通过 GraalVM 以本机方式执行流处理应用程序,而无需进一步配置。
要以本机模式运行 producer 和 aggregator 应用程序,可以使用 -Dnative 执行 Maven 构建
./mvnw clean package -f producer/pom.xml -Dnative -Dnative-image.container-runtime=docker
./mvnw clean package -f aggregator/pom.xml -Dnative -Dnative-image.container-runtime=docker现在创建一个名为 QUARKUS_MODE 的环境变量,并将值设置为 "native"
export QUARKUS_MODE=nativeDocker Compose 文件使用它来构建 producer 和 aggregator 镜像时使用正确的 Dockerfile。 Kafka Streams 应用程序可以在本机模式下使用少于 50 MB 的 RSS。 为此,请将 Xmx 选项添加到 aggregator/src/main/docker/Dockerfile.native 中的程序调用
CMD ["./application", "-Dquarkus.http.host=0.0.0.0", "-Xmx32m"]现在按照上述说明启动 Docker Compose(不要忘记重建容器镜像)。
Kafka Streams 健康检查
如果您使用的是 quarkus-smallrye-health 扩展,则 quarkus-kafka-streams 将自动添加
-
准备就绪健康检查,以验证是否已创建在
quarkus.kafka-streams.topics属性中声明的所有主题, -
基于 Kafka Streams 状态的活跃性健康检查。
因此,当您访问应用程序的 /q/health 端点时,您将获得有关 Kafka Streams 状态以及可用和/或缺失主题的信息。
这是状态为 DOWN 的一个示例
curl -i http://aggregator:8080/q/health
HTTP/1.1 503 Service Unavailable
content-type: application/json; charset=UTF-8
content-length: 454
{
"status": "DOWN",
"checks": [
{
"name": "Kafka Streams state health check", (1)
"status": "DOWN",
"data": {
"state": "CREATED"
}
},
{
"name": "Kafka Streams topics health check", (2)
"status": "DOWN",
"data": {
"available_topics": "weather-stations,temperature-values",
"missing_topics": "hygrometry-values"
}
}
]
}| 1 | 活跃性健康检查。 也可在 /q/health/live 端点上找到。 |
| 2 | 准备就绪健康检查。 也可在 /q/health/ready 端点上找到。 |
因此,如您所见,只要缺少 quarkus.kafka-streams.topics 之一或 Kafka Streams state 不是 RUNNING,状态就会变为 DOWN。
如果没有可用的主题,则 Kafka Streams topics health check 的 data 字段中将不存在 available_topics 键。 同样,如果没有缺失的主题,则 Kafka Streams topics health check 的 data 字段中将不存在 missing_topics 键。
您当然可以通过在 application.properties 中将 quarkus.kafka-streams.health.enabled 属性设置为 false 来禁用 quarkus-kafka-streams 扩展的健康检查。
显然,您可以基于相应的端点 /q/health/live 和 /q/health/ready 创建您的活跃性和准备就绪探针。
活跃性健康检查
这是活跃性检查的示例
curl -i http://aggregator:8080/q/health/live
HTTP/1.1 503 Service Unavailable
content-type: application/json; charset=UTF-8
content-length: 225
{
"status": "DOWN",
"checks": [
{
"name": "Kafka Streams state health check",
"status": "DOWN",
"data": {
"state": "CREATED"
}
}
]
}state 来自 KafkaStreams.State 枚举。
准备就绪健康检查
这是准备就绪检查的示例
curl -i http://aggregator:8080/q/health/ready
HTTP/1.1 503 Service Unavailable
content-type: application/json; charset=UTF-8
content-length: 265
{
"status": "DOWN",
"checks": [
{
"name": "Kafka Streams topics health check",
"status": "DOWN",
"data": {
"missing_topics": "weather-stations,temperature-values"
}
}
]
}更进一步
本指南介绍了如何使用 Quarkus 和 Kafka Streams API 在 JVM 和本机模式下构建流处理应用程序。 为了在生产环境中运行您的 KStreams 应用程序,您还可以为数据管道添加健康检查和指标。 请参阅有关 Micrometer、SmallRye Metrics 和 SmallRye Health 的 Quarkus 指南以了解更多信息。
配置参考
构建时固定的配置属性 - 所有其他配置属性都可以在运行时覆盖
配置属性 |
类型 |
默认 |
|---|---|---|
如果存在 smallrye-health 扩展,是否发布健康检查(默认为 true)。 环境变量: 显示更多 |
布尔值 |
|
此 Kafka Streams 应用程序的唯一标识符。 如果未设置,则默认为 quarkus.application.name。 环境变量: 显示更多 |
字符串 |
|
标识 Kafka 引导服务器的以逗号分隔的 host:port 对列表。 如果未设置,则回退到 环境变量: 显示更多 |
主机:端口 列表 |
|
此应用程序实例的唯一标识符,通常采用 host:port 形式。 环境变量: 显示更多 |
字符串 |
|
以逗号分隔的主题名称列表。 仅当所有这些主题都存在于 Kafka 集群中并且 环境变量: 显示更多 |
字符串列表 |
|
以逗号分隔的主题名称模式列表。 仅当所有这些主题都存在于 Kafka 集群中并且 环境变量: 显示更多 |
字符串列表 |
|
等待从管理客户端返回主题名称的超时时间。 如果设置为 0(或负数),则忽略 环境变量: 显示更多 |
|
|
架构注册表键。 不同的架构注册表库在不同的配置属性中需要注册表 URL。 对于 Apicurio Registry,请使用 环境变量: 显示更多 |
字符串 |
|
架构注册表 URL。 环境变量: 显示更多 |
字符串 |
|
要使用的安全协议请参见 https://docs.confluent.io/current/streams/developer-guide/security.html#security-example 环境变量: 显示更多 |
字符串 |
|
用于客户端连接的 SASL 机制 环境变量: 显示更多 |
字符串 |
|
SASL 连接的 JAAS 登录上下文参数,采用 JAAS 配置文件使用的格式 环境变量: 显示更多 |
字符串 |
|
SASL 客户端回调处理程序类的完全限定名称 环境变量: 显示更多 |
字符串 |
|
SASL 登录回调处理程序类的完全限定名称 环境变量: 显示更多 |
字符串 |
|
实现 Login 接口的类的完全限定名称 环境变量: 显示更多 |
字符串 |
|
Kafka 作为 Kerberos 主体名称运行 环境变量: 显示更多 |
字符串 |
|
Kerberos kinit 命令路径 环境变量: 显示更多 |
字符串 |
|
登录线程将休眠,直到上次刷新后的指定窗口因子时间 环境变量: 显示更多 |
double |
|
添加到续订时间的随机抖动百分比 环境变量: 显示更多 |
double |
|
添加到续订时间的随机抖动百分比 环境变量: 显示更多 |
long |
|
登录刷新线程将休眠,直到达到相对于凭据生命周期的指定窗口因子 环境变量: 显示更多 |
double |
|
相对于凭据生命周期的最大随机抖动量 环境变量: 显示更多 |
double |
|
登录刷新线程在刷新凭据之前要等待的所需最短持续时间 环境变量: 显示更多 |
||
刷新凭据时要维护的凭据到期之前的缓冲持续时间 环境变量: 显示更多 |
||
用于生成 SSLContext 的 SSL 协议 环境变量: 显示更多 |
字符串 |
|
字符串 |
||
字符串 |
||
SSL连接启用的协议列表 环境变量: 显示更多 |
字符串 |
|
信任存储类型 环境变量: 显示更多 |
字符串 |
|
信任存储位置 环境变量: 显示更多 |
字符串 |
|
信任存储密码 环境变量: 显示更多 |
字符串 |
|
信任存储证书 环境变量: 显示更多 |
字符串 |
|
字符串 |
||
密钥存储位置 环境变量: 显示更多 |
字符串 |
|
密钥存储密码 环境变量: 显示更多 |
字符串 |
|
字符串 |
||
密钥存储证书链 环境变量: 显示更多 |
字符串 |
|
字符串 |
||
密钥管理器工厂用于SSL连接的算法 环境变量: 显示更多 |
字符串 |
|
信任管理器工厂用于SSL连接的算法 环境变量: 显示更多 |
字符串 |
|
端点识别算法,用于使用服务器证书验证服务器主机名 环境变量: 显示更多 |
字符串 |
|
用于SSL加密操作的SecureRandom PRNG实现 环境变量: 显示更多 |
字符串 |
|
关于 Duration 格式
要写入持续时间值,请使用标准 您还可以使用简化的格式,以数字开头
在其他情况下,简化格式将被转换为
|
