Apache Kafka 参考指南
本参考指南演示了您的 Quarkus 应用程序如何利用 Quarkus Messaging 与 Apache Kafka 进行交互。
1. 简介
Apache Kafka 是一个流行的开源分布式事件流平台。它常用于高性能数据管道、流分析、数据集成和关键任务应用程序。类似于消息队列或企业消息平台,它允许您
-
发布(写入)和订阅(读取)事件流,称为记录。
-
持久且可靠地存储记录流在主题中。
-
处理发生的事件流或回顾性事件流。
所有这些功能都以分布式、高度可伸缩、弹性、容错和安全的方式提供。
2. Quarkus Apache Kafka 扩展
Quarkus 通过 SmallRye Reactive Messaging 框架为 Apache Kafka 提供支持。它基于 Eclipse MicroProfile Reactive Messaging 规范 2.0,提供了一个灵活的编程模型,连接 CDI 和事件驱动。
|
本指南将深入介绍 Apache Kafka 和 SmallRye Reactive Messaging 框架。如需快速入门,请参阅 Quarkus Messaging 与 Apache Kafka 入门。 |
您可以通过在项目根目录下运行以下命令,将 messaging-kafka 扩展添加到您的项目中
quarkus extension add messaging-kafka./mvnw quarkus:add-extension -Dextensions='messaging-kafka'./gradlew addExtension --extensions='messaging-kafka'这会将以下内容添加到您的构建文件中
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-messaging-kafka</artifactId>
</dependency>implementation("io.quarkus:quarkus-messaging-kafka")|
该扩展包含 |
3. 配置 SmallRye Kafka 连接器
由于 SmallRye Reactive Messaging 框架支持 Apache Kafka、AMQP、Apache Camel、JMS、MQTT 等不同的消息后端,因此它采用通用词汇。
-
应用程序发送和接收消息。消息包含一个载荷,并且可以添加元数据。对于 Kafka 连接器,消息对应于 Kafka记录。
-
消息在通道上传输。应用程序组件连接到通道以发布和消耗消息。Kafka 连接器将通道映射到 Kafka主题。
-
通道使用连接器连接到消息后端。连接器配置为将传入消息映射到特定通道(由应用程序消耗),并收集发送到特定通道的传出消息。每个连接器都致力于一种特定的消息传递技术。例如,处理 Kafka 的连接器名为
smallrye-kafka。
以下是带有传入通道的 Kafka 连接器的最小配置
%prod.kafka.bootstrap.servers=kafka:9092 (1)
mp.messaging.incoming.prices.connector=smallrye-kafka (2)| 1 | 为生产环境配置代理位置。您可以在全局配置或使用 mp.messaging.incoming.$channel.bootstrap.servers 属性按通道配置。在开发模式和测试运行时,Kafka 的开发服务会自动启动一个 Kafka 代理。如果未提供,此属性默认为 localhost:9092。 |
| 2 | 将连接器配置为管理价格通道。默认情况下,主题名称与通道名称相同。您可以配置 topic 属性来覆盖它。 |
%prod 前缀表示该属性仅在应用程序以生产模式运行时使用(因此在开发或测试模式下不使用)。有关更多详细信息,请参阅配置文件文档。 |
|
连接器自动附加
如果类路径中只有一个连接器,您可以省略 可以使用以下方式禁用此自动附加功能 |
4. 从 Kafka 接收消息
从前面的最小配置继续,您的 Quarkus 应用程序可以直接接收消息载荷
import org.eclipse.microprofile.reactive.messaging.Incoming;
import jakarta.enterprise.context.ApplicationScoped;
@ApplicationScoped
public class PriceConsumer {
@Incoming("prices")
public void consume(double price) {
// process your price.
}
}您的应用程序还可以通过其他几种方式消耗传入消息
@Incoming("prices")
public CompletionStage<Void> consume(Message<Double> msg) {
// access record metadata
var metadata = msg.getMetadata(IncomingKafkaRecordMetadata.class).orElseThrow();
// process the message payload.
double price = msg.getPayload();
// Acknowledge the incoming message (commit the offset)
return msg.ack();
}Message 类型允许消费方法访问传入消息的元数据并手动处理确认。我们将在提交策略中探讨不同的确认策略。
如果您想直接访问 Kafka 记录对象,请使用
@Incoming("prices")
public void consume(ConsumerRecord<String, Double> record) {
String key = record.key(); // Can be `null` if the incoming record has no key
String value = record.value(); // Can be `null` if the incoming record has no value
String topic = record.topic();
int partition = record.partition();
// ...
}ConsumerRecord 由底层的 Kafka 客户端提供,可以直接注入到消费方法中。另一种更简单的方法是使用 Record
@Incoming("prices")
public void consume(Record<String, Double> record) {
String key = record.key(); // Can be `null` if the incoming record has no key
String value = record.value(); // Can be `null` if the incoming record has no value
}Record 是传入 Kafka 记录的键和载荷的简单包装器。
或者,您的应用程序可以将 Multi 注入到您的 bean 中,并订阅其事件,如下面的示例所示
import io.smallrye.mutiny.Multi;
import org.eclipse.microprofile.reactive.messaging.Channel;
import jakarta.inject.Inject;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import org.jboss.resteasy.reactive.RestStreamElementType;
@Path("/prices")
public class PriceResource {
@Inject
@Channel("prices")
Multi<Double> prices;
@GET
@Path("/prices")
@RestStreamElementType(MediaType.TEXT_PLAIN)
public Multi<Double> stream() {
return prices;
}
}这是将 Kafka 消费者与另一个下游集成的好例子,在本例中将其公开为服务器发送事件 (Server-Sent Events) 端点。
|
使用 |
以下类型可以作为通道注入
@Inject @Channel("prices") Multi<Double> streamOfPayloads;
@Inject @Channel("prices") Multi<Message<Double>> streamOfMessages;
@Inject @Channel("prices") Publisher<Double> publisherOfPayloads;
@Inject @Channel("prices") Publisher<Message<Double>> publisherOfMessages;与之前的 Message 示例一样,如果注入的通道接收载荷 (Multi<T>),它会自动确认消息,并支持多个订阅者。如果您注入的通道接收 Message (Multi<Message<T>>),您将负责确认和广播。我们将在将消息广播到多个消费者中探讨发送广播消息。
|
注入 |
4.1. 阻塞处理
Reactive Messaging 在 I/O 线程上调用您的方法。有关此主题的更多详细信息,请参阅Quarkus 反应式架构文档。但是,您通常需要将 Reactive Messaging 与阻塞处理(如数据库交互)结合使用。为此,您需要使用 @Blocking 注释,指示处理是阻塞的,并且不应在调用线程上运行。
例如,以下代码说明了如何使用带有 Panache 的 Hibernate 将传入的有效负载存储到数据库中
import io.smallrye.reactive.messaging.annotations.Blocking;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.transaction.Transactional;
@ApplicationScoped
public class PriceStorage {
@Incoming("prices")
@Transactional
public void store(int priceInUsd) {
Price price = new Price();
price.value = priceInUsd;
price.persist();
}
}完整的示例可在 kafka-panache-quickstart 目录中找到。
|
有 2 个
它们具有相同的效果。因此,您可以同时使用它们。第一个提供了更细粒度的调优,例如要使用的工作池以及是否保持顺序。第二个也与 Quarkus 的其他反应式功能一起使用,使用默认工作池并保持顺序。 有关 |
|
@RunOnVirtualThread
有关在 Java 虚拟线程上运行阻塞处理的信息,请参见 Quarkus 虚拟线程支持与响应式消息传递文档。 |
|
@Transactional
如果您的方法使用 |
4.2. 确认策略
消费者接收的所有消息都必须被确认。如果没有确认,则认为处理有错误。如果消费方法接收到 Record 或载荷,消息将在方法返回时被确认,也称为 Strategy.POST_PROCESSING。如果消费方法返回另一个反应式流或 CompletionStage,消息将在下游消息被确认时被确认。您可以覆盖默认行为,在到达时(Strategy.PRE_PROCESSING)确认消息,或者在消费方法中根本不确认消息(Strategy.NONE),如下面的示例所示。
@Incoming("prices")
@Acknowledgment(Acknowledgment.Strategy.PRE_PROCESSING)
public void process(double price) {
// process price
}如果消费方法接收到 Message,则确认策略为 Strategy.MANUAL,消费方法负责确认/拒绝消息。
@Incoming("prices")
public CompletionStage<Void> process(Message<Double> msg) {
// process price
return msg.ack();
}如上所述,方法还可以将确认策略覆盖为 PRE_PROCESSING 或 NONE。
4.3. 提交策略
当从 Kafka 记录生成的消息被确认时,连接器会调用提交策略。这些策略决定何时提交特定主题/分区的消费者偏移量。提交偏移量表示所有之前的记录都已处理。它也是应用程序在崩溃恢复或重新启动后重新开始处理的位置。
提交每个偏移量都会带来性能损失,因为 Kafka 偏移量管理可能很慢。但是,如果不经常提交偏移量,如果应用程序在两次提交之间崩溃,可能会导致消息重复。
Kafka 连接器支持三种策略:
-
throttled跟踪接收的消息,并按顺序提交最新已确认消息的偏移量(意味着,所有之前的消息也已确认)。此策略保证至少一次传递,即使通道执行异步处理。连接器跟踪接收到的记录,并定期(由auto.commit.interval.ms指定的周期,默认为 5000 毫秒)提交最高连续偏移量。如果与记录关联的消息未在throttled.unprocessed-record-max-age.ms(默认为 60000 毫秒)内得到确认,则连接器将被标记为不健康。事实上,此策略无法在单个记录处理失败后立即提交偏移量。如果throttled.unprocessed-record-max-age.ms设置为小于或等于0,则它不执行任何健康检查。 such setting might lead to running out of memory if there are "poison pill" messages (that are never acked).此策略是默认策略,除非enable.auto.commit被显式设置为 true。 -
checkpoint允许将消费者偏移量持久化到状态存储,而不是提交回 Kafka 代理。使用CheckpointMetadataAPI,消费代码可以持久化处理状态与记录偏移量一起,以标记消费者的进度。当处理从先前持久化的偏移量继续时,它会将 Kafka 消费者定位到该偏移量,并恢复持久化的状态,从而从上次中断的地方继续有状态的处理。检查点策略在本地保存与最新偏移量关联的处理状态,并定期将其持久化到状态存储(由auto.commit.interval.ms指定的周期(默认为 5000))。如果未在checkpoint.unsynced-state-max-age.ms(默认为 10000)内将任何处理状态持久化到状态存储,则连接器将被标记为不健康。如果checkpoint.unsynced-state-max-age.ms设置为小于或等于 0,则它不执行任何健康检查。有关更多信息,请参阅使用检查点进行有状态处理。 -
latest在消息被确认后立即提交 Kafka 消费者接收到的记录偏移量(如果偏移量高于先前提交的偏移量)。此策略提供至少一次传递,前提是通道在不执行任何异步处理的情况下处理消息。具体来说,即使旧消息尚未处理完成,也会始终提交最新已确认消息的偏移量。如果发生事故(如崩溃),处理将从上次提交后重新开始,导致旧消息永远无法成功且完全处理,这会表现为消息丢失。此策略不应在高负载环境中使用,因为偏移量提交成本很高。但是,它减少了重复的可能性。 -
ignore不执行任何提交。当消费者显式配置为enable.auto.commit为 true 时,此策略是默认策略。它将偏移量提交委托给底层的 Kafka 客户端。当enable.auto.commit为true时,此策略不保证至少一次传递。SmallRye Reactive Messaging 异步处理记录,因此可能会提交已轮询但尚未处理的记录的偏移量。发生故障时,只会重新处理尚未提交的记录。
|
当未显式启用 Kafka 自动提交时,Kafka 连接器会禁用 Kafka 自动提交。此行为与传统的 Kafka 消费者不同。如果高吞吐量对您很重要,并且您不受下游的限制,我们建议要么
|
SmallRye Reactive Messaging 支持实现自定义提交策略。有关更多信息,请参阅SmallRye Reactive Messaging 文档。
4.4. 错误处理策略
如果从 Kafka 记录生成的消息被拒绝,则会应用失败策略。Kafka 连接器支持三种策略:
-
fail:使应用程序失败,不再处理记录(默认策略)。未正确处理的记录的偏移量不会被提交。 -
ignore:记录失败,但处理继续。未正确处理的记录的偏移量将被提交。 -
dead-letter-queue:未正确处理的记录的偏移量将被提交,但记录将被写入 Kafka 死信队列主题。
该策略使用 failure-strategy 属性选择。
对于 dead-letter-queue,您可以配置以下属性:
-
dead-letter-queue.topic:用于写入未正确处理的记录的主题,默认为dead-letter-topic-$channel,其中$channel是通道的名称。 -
dead-letter-queue.key.serializer:用于将记录键写入死信队列的序列化器。默认情况下,它从反序列化器推断序列化器。 -
dead-letter-queue.value.serializer:用于将记录值写入死信队列的序列化器。默认情况下,它从反序列化器推断序列化器。
写入死信队列的记录包含关于原始记录的一组附加标头:
-
dead-letter-reason:失败的原因
-
dead-letter-cause:失败的原因(如果有)
-
dead-letter-topic:记录的原始主题
-
dead-letter-partition:记录的原始分区(整数映射到字符串)
-
dead-letter-offset:记录的原始偏移量(长整型映射到字符串)
SmallRye Reactive Messaging 支持实现自定义失败策略。有关更多信息,请参阅SmallRye Reactive Messaging 文档。
4.4.1. 重试处理
您可以将 Reactive Messaging 与 SmallRye Fault Tolerance 结合使用,并在失败后重试处理。
@Incoming("kafka")
@Retry(delay = 10, maxRetries = 5)
public void consume(String v) {
// ... retry if this method throws an exception
}您可以配置延迟、重试次数、抖动等。
如果您的方法返回 Uni 或 CompletionStage,您需要添加 @NonBlocking 注释。
@Incoming("kafka")
@Retry(delay = 10, maxRetries = 5)
@NonBlocking
public Uni<String> consume(String v) {
// ... retry if this method throws an exception or the returned Uni produce a failure
}@NonBlocking 注释仅在 SmallRye Fault Tolerance 5.1.0 及更早版本中需要。从 SmallRye Fault Tolerance 5.2.0(自 Quarkus 2.1.0.Final 起可用)开始,它不再是必需的。有关更多信息,请参阅SmallRye Fault Tolerance 文档。 |
入站消息仅在处理成功完成后才会被确认。因此,它会在成功处理后提交偏移量。如果处理仍然失败,即使在所有重试之后,消息也会被拒绝,并应用失败策略。
4.4.2. 处理反序列化失败
当发生反序列化失败时,您可以拦截它并提供失败策略。要实现这一点,您需要创建一个实现 DeserializationFailureHandler<T> 接口的 bean。
@ApplicationScoped
@Identifier("failure-retry") // Set the name of the failure handler
public class MyDeserializationFailureHandler
implements DeserializationFailureHandler<JsonObject> { // Specify the expected type
@Override
public JsonObject decorateDeserialization(Uni<JsonObject> deserialization, String topic, boolean isKey,
String deserializer, byte[] data, Headers headers) {
return deserialization
.onFailure().retry().atMost(3)
.await().atMost(Duration.ofMillis(200));
}
}要使用此失败处理程序,必须使用 @Identifier 限定符暴露 bean,并且连接器配置必须指定 mp.messaging.incoming.$channel.[key|value]-deserialization-failure-handler 属性(用于键或值反序列化器)。
该处理程序会接收反序列化详细信息,包括表示为 Uni<T> 的操作。对于反序列化 Uni,可以实现重试、提供备用值或应用超时等失败策略。
如果您不配置反序列化失败处理程序并且发生反序列化失败,应用程序将被标记为不健康。您也可以忽略失败,这将记录异常并生成 null 值。要启用此行为,请将 mp.messaging.incoming.$channel.fail-on-deserialization-failure 属性设置为 false。
如果 fail-on-deserialization-failure 属性设置为 false 并且 failure-strategy 属性为 dead-letter-queue,则失败的记录将被发送到相应的死信队列主题。
4.5. 消费者组
在 Kafka 中,消费者组是一组协调消费主题数据的消费者。主题被划分为一组分区。主题的分区在组内的消费者之间分配,从而有效地提高了消费吞吐量。请注意,每个分区只分配给组中的一个消费者。但是,如果分区的数量大于组中的消费者数量,一个消费者可以被分配多个分区。
让我们简要探讨不同的生产者/消费者模式以及如何使用 Quarkus 实现它们。
-
消费者组内的单个消费者线程
这是订阅 Kafka 主题的应用程序的默认行为:每个 Kafka 连接器将创建一个单个消费者线程并将其置于单个消费者组中。消费者组 ID 默认为
quarkus.application.name配置属性设置的应用程序名称。它也可以使用kafka.group.id属性设置。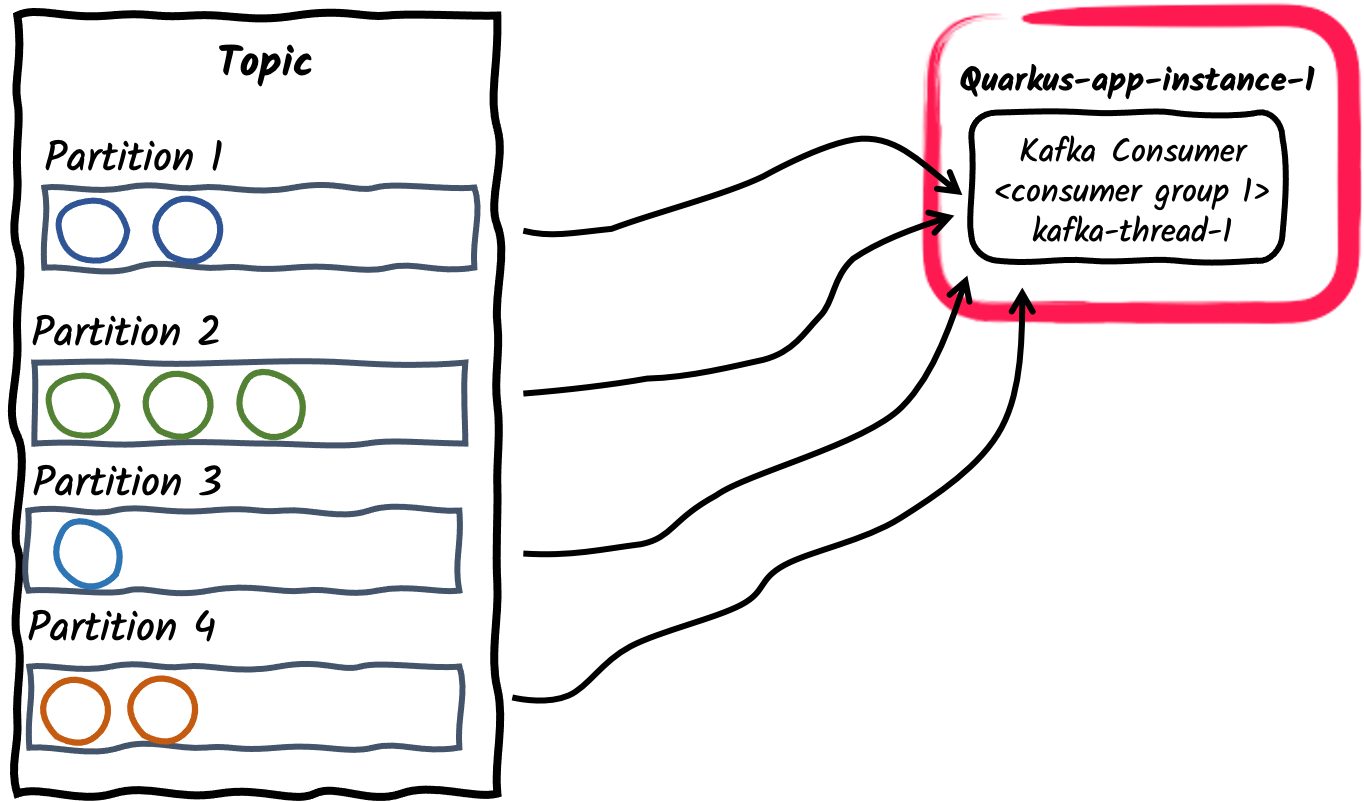
-
消费者组内的多个消费者线程
对于给定的应用程序实例,可以使用
mp.messaging.incoming.$channel.concurrency属性配置消费者组内的消费者数量。订阅主题的分区将在消费者线程之间划分。请注意,如果concurrency值超过主题的分区数,某些消费者线程将不会被分配任何分区。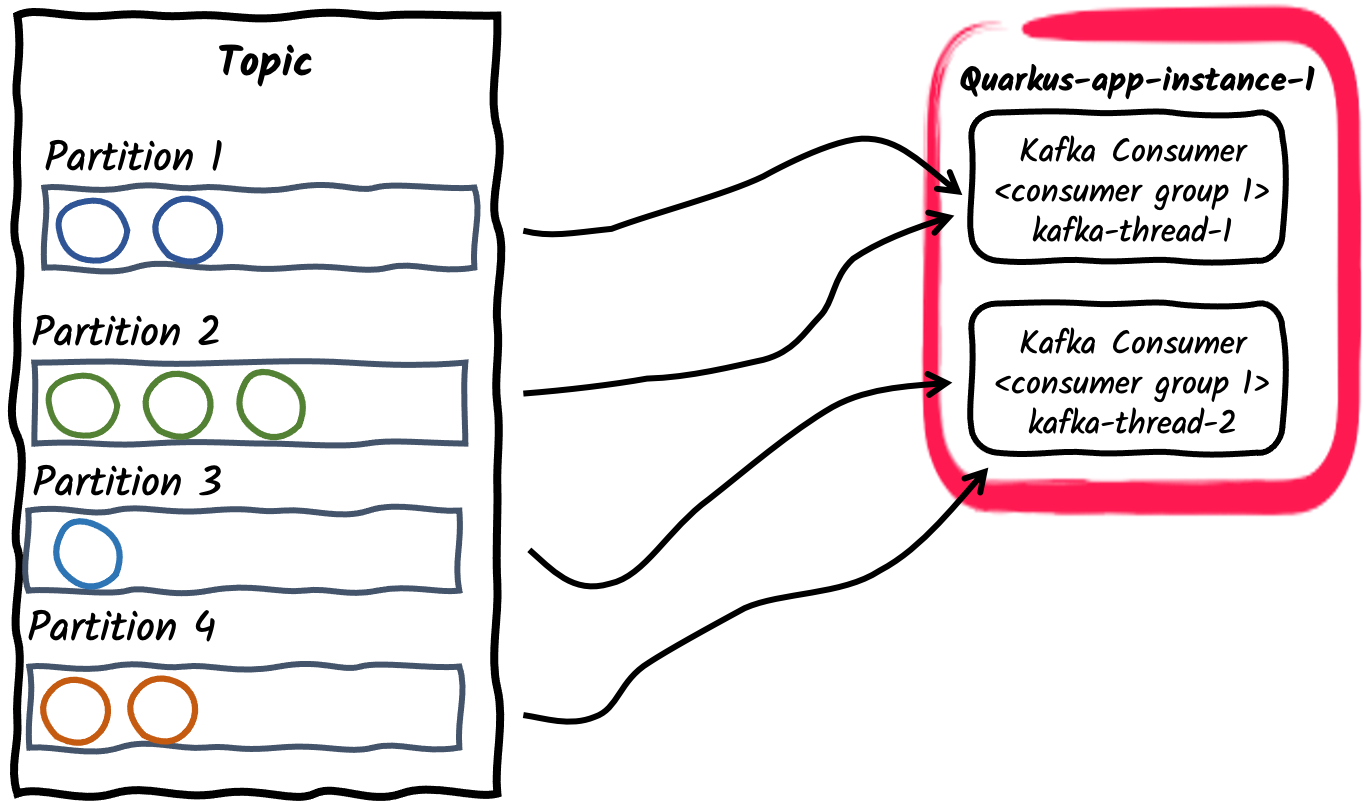 弃用
弃用concurrency属性提供了一种与连接器无关的方式来实现非阻塞并发通道,并取代了 Kafka 连接器特定的partitions属性。因此,partitions属性已被弃用,将在未来的版本中删除。 -
消费者组内的多个消费者应用程序
与前面的示例类似,应用程序的多个实例可以订阅单个消费者组,通过
mp.messaging.incoming.$channel.group.id属性配置,或者保留为应用程序名称的默认值。这反过来会将主题的分区分配给应用程序实例。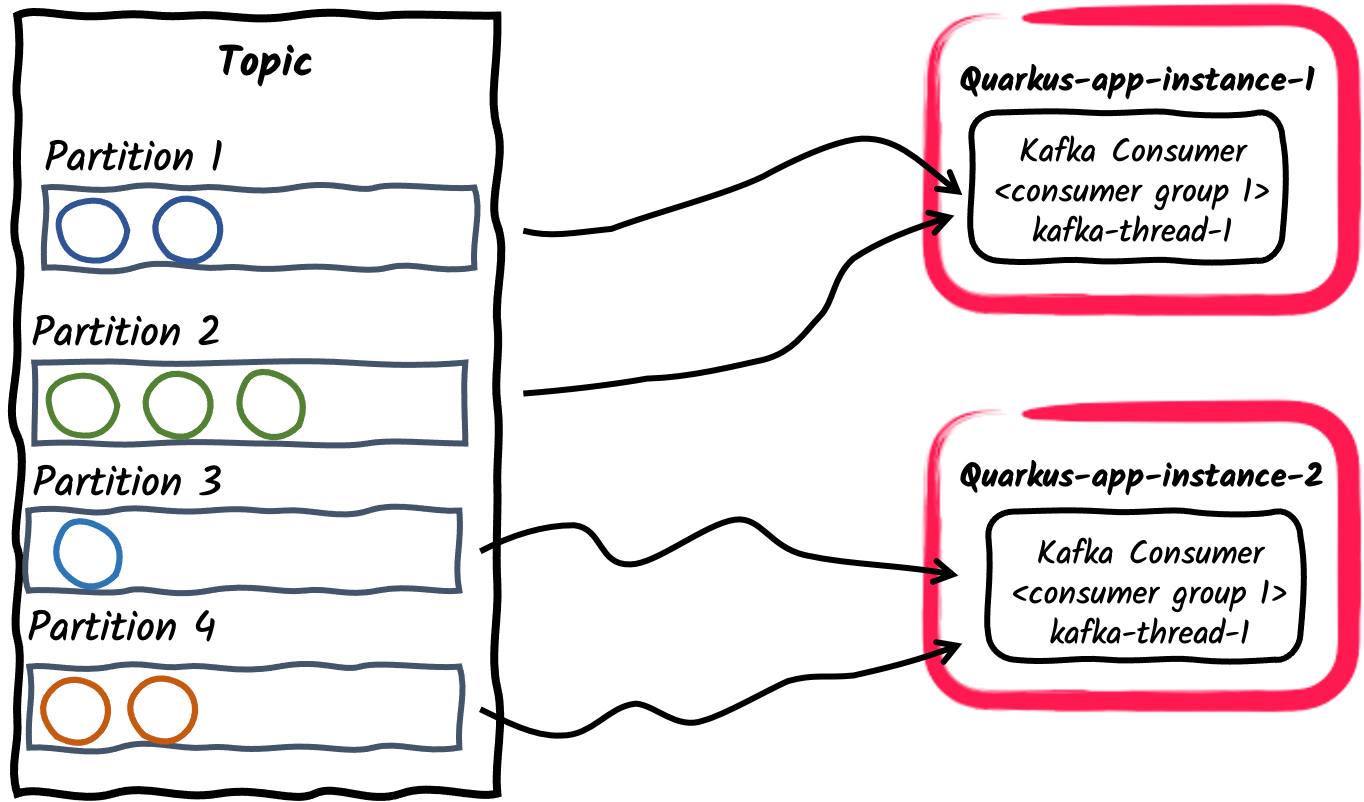
-
发布/订阅:多个消费者组订阅主题
最后,不同的应用程序可以使用不同的消费者组 ID 独立订阅相同的主题。例如,发布到名为orders的主题的消息可以被两个消费者应用程序独立消费,一个使用
mp.messaging.incoming.orders.group.id=invoicing,第二个使用mp.messaging.incoming.orders.group.id=shipping。因此,不同的消费者组可以根据消息消费需求独立扩展。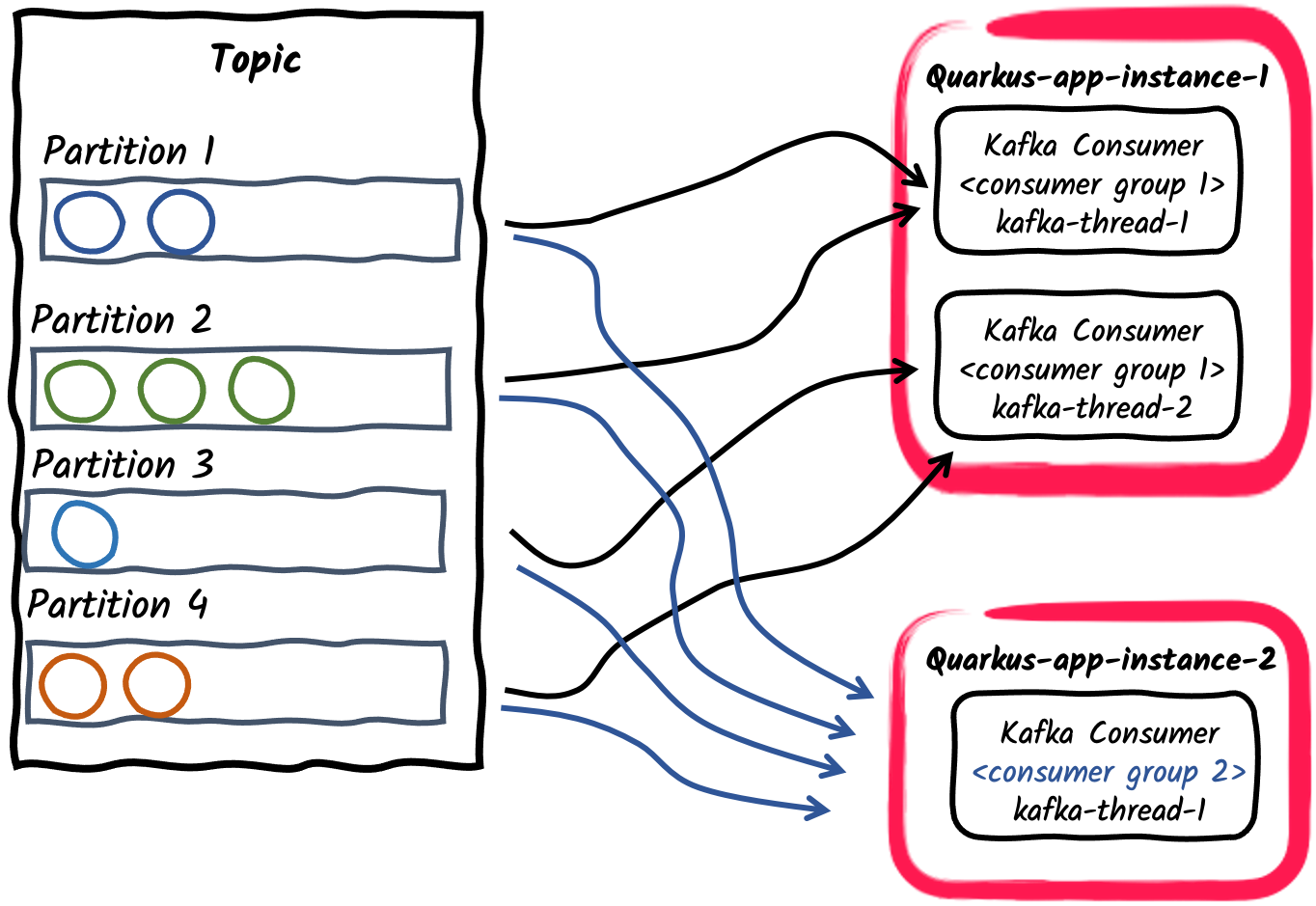
|
一个常见的业务需求是按顺序消费和处理 Kafka 记录。Kafka 代理保留分区内的记录顺序,而不是主题内的记录顺序。因此,考虑记录如何在主题内分区很重要。默认分区器使用记录键的哈希值来计算记录的分区,或者在未定义键时,为每个批次或记录随机选择一个分区。 在正常操作期间,Kafka 消费者会保持其分配的每个分区内记录的顺序。SmallRye Reactive Messaging 会保留此顺序进行处理,除非使用了 请注意,由于消费者重新平衡,Kafka 消费者仅保证单个记录的至少一次处理,这意味着未提交的记录可能被消费者再次处理。 |
4.5.1. 消费者重平衡监听器
在消费者组内,随着新成员的加入和旧成员的离开,分区会被重新分配,以便每个成员获得与其成比例的份额。这称为组的重新平衡。要自行处理偏移量提交和分配的分区,您可以提供一个消费者重平衡监听器。要实现这一点,请实现 io.smallrye.reactive.messaging.kafka.KafkaConsumerRebalanceListener 接口,并使用 @Idenfier 限定符将其暴露为 CDI bean。一个常见的用例是将偏移量存储在单独的数据存储中,以实现精确一次语义,或从特定偏移量开始处理。
每次消费者主题/分区分配更改时都会调用监听器。例如,应用程序启动时,它会调用 partitionsAssigned 回调,其中包含与消费者关联的主题/分区的初始集。如果之后此集发生更改,它会再次调用 partitionsRevoked 和 partitionsAssigned 回调,以便您可以实现自定义逻辑。
请注意,重平衡监听器方法是从 Kafka 轮询线程调用的,并且会阻塞调用线程直到完成。这是因为重平衡协议具有同步屏障,而在重平衡监听器中使用异步代码可能会在同步屏障之后执行。
当主题/分区分配或撤销给消费者时,它会暂停消息传递,并在重平衡完成后恢复。
如果重平衡监听器代表用户处理偏移量提交(使用 NONE 提交策略),则重平衡监听器必须在 partitionsRevoked 回调中同步提交偏移量。我们也建议在应用程序停止时应用相同的逻辑。
与 Apache Kafka 的 ConsumerRebalanceListener 不同,io.smallrye.reactive.messaging.kafka.KafkaConsumerRebalanceListener 方法传递 Kafka Consumer 和主题/分区的集合。
在下面的示例中,我们设置了一个消费者,该消费者始终从最多 10 分钟前(或偏移量 0)的消息开始。首先,我们需要提供一个实现 io.smallrye.reactive.messaging.kafka.KafkaConsumerRebalanceListener 并使用 io.smallrye.common.annotation.Identifier 注释的 bean。然后,我们必须配置我们的入站连接器以使用此 bean。
package inbound;
import io.smallrye.common.annotation.Identifier;
import io.smallrye.reactive.messaging.kafka.KafkaConsumerRebalanceListener;
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.OffsetAndTimestamp;
import org.apache.kafka.clients.consumer.TopicPartition;
import jakarta.enterprise.context.ApplicationScoped;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.logging.Logger;
@ApplicationScoped
@Identifier("rebalanced-example.rebalancer")
public class KafkaRebalancedConsumerRebalanceListener implements KafkaConsumerRebalanceListener {
private static final Logger LOGGER = Logger.getLogger(KafkaRebalancedConsumerRebalanceListener.class.getName());
/**
* When receiving a list of partitions, will search for the earliest offset within 10 minutes
* and seek the consumer to it.
*
* @param consumer underlying consumer
* @param partitions set of assigned topic partitions
*/
@Override
public void onPartitionsAssigned(Consumer<?, ?> consumer, Collection<TopicPartition> partitions) {
long now = System.currentTimeMillis();
long shouldStartAt = now - 600_000L; //10 minute ago
Map<TopicPartition, Long> request = new HashMap<>();
for (TopicPartition partition : partitions) {
LOGGER.info("Assigned " + partition);
request.put(partition, shouldStartAt);
}
Map<TopicPartition, OffsetAndTimestamp> offsets = consumer.offsetsForTimes(request);
for (Map.Entry<TopicPartition, OffsetAndTimestamp> position : offsets.entrySet()) {
long target = position.getValue() == null ? 0L : position.getValue().offset();
LOGGER.info("Seeking position " + target + " for " + position.getKey());
consumer.seek(position.getKey(), target);
}
}
}package inbound;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.eclipse.microprofile.reactive.messaging.Acknowledgment;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Message;
import jakarta.enterprise.context.ApplicationScoped;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.CompletionStage;
@ApplicationScoped
public class KafkaRebalancedConsumer {
@Incoming("rebalanced-example")
@Acknowledgment(Acknowledgment.Strategy.NONE)
public CompletionStage<Void> consume(Message<ConsumerRecord<Integer, String>> message) {
// We don't need to ACK messages because in this example,
// we set offset during consumer rebalance
return CompletableFuture.completedFuture(null);
}
}要配置入站连接器以使用提供的监听器,我们可以设置消费者重平衡监听器的标识符:mp.messaging.incoming.rebalanced-example.consumer-rebalance-listener.name=rebalanced-example.rebalancer
或者让监听器的名称与组 ID 相同:
mp.messaging.incoming.rebalanced-example.group.id=rebalanced-example.rebalancer
设置消费者重平衡监听器的名称优先于使用组 ID。
4.5.2. 使用唯一消费者组
如果您想处理主题中的所有记录(从头开始),您需要
-
设置
auto.offset.reset = earliest -
将您的消费者分配给任何其他应用程序未使用过的消费者组。
Quarkus 会生成一个 UUID,该 UUID 在两次执行之间会发生变化(包括在开发模式下)。因此,您确信没有其他消费者使用它,并且每次应用程序启动时都会获得一个新的唯一组 ID。
您可以使用生成的 UUID 作为消费者组,如下所示:
mp.messaging.incoming.your-channel.auto.offset.reset=earliest
mp.messaging.incoming.your-channel.group.id=${quarkus.uuid}如果未设置 group.id 属性,它将默认为 quarkus.application.name 配置属性。 |
4.5.3. 手动主题-分区分配
assign-seek 通道属性允许手动将主题-分区分配给 Kafka 入站通道,并可以选择性地定位到指定偏移量的分区以开始消费记录。如果使用 assign-seek,消费者将不会动态订阅主题,而是静态分配描述的分区。在手动主题-分区重新平衡时不会发生,因此永远不会调用重平衡监听器。
该属性接受一个由逗号分隔的三元组列表:<topic>:<partition>:<offset>。
例如,配置:
mp.messaging.incoming.data.assign-seek=topic1:0:10, topic2:1:20将消费者分配给:
-
主题 'topic1' 的分区 0,将初始位置设置为偏移量 10。
-
主题 'topic2' 的分区 1,将初始位置设置为偏移量 20。
每个三元组中的主题、分区和偏移量可以有以下变化:
-
如果省略主题,则使用配置的主题。
-
如果省略偏移量,分区将被分配给消费者,但不会定位到偏移量。
-
如果偏移量为 0,则定位到主题-分区的开头。
-
如果偏移量为 -1,则定位到主题-分区的末尾。
4.6. 批量接收 Kafka 记录
默认情况下,入站方法单独接收每个 Kafka 记录。在底层,Kafka 消费者客户端会不断轮询代理,并以批次形式接收记录,这些记录包含在 ConsumerRecords 容器中。
在批处理模式下,您的应用程序可以一次性接收消费者轮询返回的所有记录。
要实现这一点,您需要指定一个兼容的容器类型来接收所有数据。
@Incoming("prices")
public void consume(List<Double> prices) {
for (double price : prices) {
// process price
}
}入站方法还可以接收 Message<List<Payload>>、Message<ConsumerRecords<Key, Payload>> 和 ConsumerRecords<Key, Payload> 类型。它们可以访问记录的详细信息,如偏移量或时间戳。
@Incoming("prices")
public CompletionStage<Void> consumeMessage(Message<ConsumerRecords<String, Double>> records) {
for (ConsumerRecord<String, Double> record : records.getPayload()) {
String payload = record.getPayload();
String topic = record.getTopic();
// process messages
}
// ack will commit the latest offsets (per partition) of the batch.
return records.ack();
}请注意,成功处理入站记录批次将提交批次中接收到的每个分区的最新偏移量。配置的提交策略将仅适用于这些记录。
相反,如果处理引发异常,所有消息都将被拒绝,并对批次中的所有记录应用失败策略。
|
Quarkus 会自动检测入站通道的批次类型并自动设置批次配置。您可以使用 |
4.7. 使用检查点进行有状态处理
|
|
SmallRye Reactive Messaging checkpoint 提交策略允许消费者应用程序以有状态的方式处理消息,同时尊重 Kafka 消费者的可伸缩性。具有 checkpoint 提交策略的入站通道将消费者偏移量持久化到外部状态存储,例如关系数据库或键值存储。在处理消费记录后,消费者应用程序可以为分配给 Kafka 消费者的每个主题-分区累积内部状态。此本地状态将定期持久化到状态存储,并与产生它的记录的偏移量相关联。
此策略不会将任何偏移量提交到 Kafka 代理,因此当新分区分配给消费者时(例如,消费者重启或消费者组实例扩展),消费者将从最新的检查点偏移量及其保存的状态恢复处理。
@Incoming 通道消费代码可以通过 CheckpointMetadata API 操作处理状态。例如,计算 Kafka 主题上接收的价格移动平均值的消费者如下所示:
package org.acme;
import java.util.concurrent.CompletionStage;
import jakarta.enterprise.context.ApplicationScoped;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Message;
import io.smallrye.reactive.messaging.kafka.KafkaRecord;
import io.smallrye.reactive.messaging.kafka.commit.CheckpointMetadata;
@ApplicationScoped
public class MeanCheckpointConsumer {
@Incoming("prices")
public CompletionStage<Void> consume(Message<Double> record) {
// Get the `CheckpointMetadata` from the incoming message
CheckpointMetadata<AveragePrice> checkpoint = CheckpointMetadata.fromMessage(record);
// `CheckpointMetadata` allows transforming the processing state
// Applies the given function, starting from the value `0.0` when no previous state exists
checkpoint.transform(new AveragePrice(), average -> average.update(record.getPayload()), /* persistOnAck */ true);
// `persistOnAck` flag set to true, ack will persist the processing state
// associated with the latest offset (per partition).
return record.ack();
}
static class AveragePrice {
long count;
double mean;
AveragePrice update(double newPrice) {
mean += ((newPrice - mean) / ++count);
return this;
}
}
}transform 方法将转换函数应用于当前状态,生成已更改的状态并本地注册以进行检查点。默认情况下,本地状态会定期持久化到状态存储,周期由 auto.commit.interval.ms 指定(默认为 5000)。如果提供了 persistOnAck 标志,则最新状态会在消息确认时主动持久化到状态存储。setNext 方法类似地直接设置最新状态。
检查点提交策略跟踪每个主题-分区的处理状态最后一次持久化的时间。如果在 checkpoint.unsynced-state-max-age.ms(默认为 10000)内无法持久化挂起的更改,则通道将被标记为不健康。
4.7.1. 状态存储
状态存储实现决定了处理状态的持久化位置和方式。这由 mp.messaging.incoming.[channel-name].checkpoint.state-store 属性配置。状态对象的序列化取决于状态存储实现。为了指示状态存储进行序列化,可能需要使用 mp.messaging.incoming.[channel-name].checkpoint.state-type 属性配置状态对象的类名。
Quarkus 提供以下状态存储实现:
-
quarkus-redis:使用quarkus-redis-client扩展持久化处理状态。Jackson 用于将处理状态序列化为 Json。对于复杂对象,需要使用checkpoint.state-type属性配置对象的类名。默认情况下,状态存储使用默认的 redis 客户端,但如果使用命名客户端,可以使用mp.messaging.incoming.[channel-name].checkpoint.quarkus-redis.client-name属性指定客户端名称。处理状态将使用键命名方案[consumer-group-id]:[topic]:[partition]存储在 Redis 中。
例如,前面代码的配置如下:
mp.messaging.incoming.prices.group.id=prices-checkpoint
# ...
mp.messaging.incoming.prices.commit-strategy=checkpoint
mp.messaging.incoming.prices.checkpoint.state-store=quarkus-redis
mp.messaging.incoming.prices.checkpoint.state-type=org.acme.MeanCheckpointConsumer.AveragePrice
# ...
# if using a named redis client
mp.messaging.incoming.prices.checkpoint.quarkus-redis.client-name=my-redis
quarkus.redis.my-redis.hosts=redis://:7000
quarkus.redis.my-redis.password=<redis-pwd>-
quarkus-hibernate-reactive:使用quarkus-hibernate-reactive扩展持久化处理状态。处理状态对象必须是 Jakarta Persistence 实体并扩展CheckpointEntity类,该类处理由消费者组 ID、主题和分区组成的复合对象标识符。因此,需要使用checkpoint.state-type属性配置实体的类名。
例如,前面代码的配置如下:
mp.messaging.incoming.prices.group.id=prices-checkpoint
# ...
mp.messaging.incoming.prices.commit-strategy=checkpoint
mp.messaging.incoming.prices.checkpoint.state-store=quarkus-hibernate-reactive
mp.messaging.incoming.prices.checkpoint.state-type=org.acme.AveragePriceEntity其中 AveragePriceEntity 是扩展了 CheckpointEntity 的 Jakarta Persistence 实体。
package org.acme;
import jakarta.persistence.Entity;
import io.quarkus.smallrye.reactivemessaging.kafka.CheckpointEntity;
@Entity
public class AveragePriceEntity extends CheckpointEntity {
public long count;
public double mean;
public AveragePriceEntity update(double newPrice) {
mean += ((newPrice - mean) / ++count);
return this;
}
}-
quarkus-hibernate-orm:使用quarkus-hibernate-orm扩展持久化处理状态。它与前面的状态存储类似,但它使用 Hibernate ORM 而不是 Hibernate Reactive。
配置后,它可以为检查点状态存储使用命名的 persistence-unit。
mp.messaging.incoming.prices.commit-strategy=checkpoint
mp.messaging.incoming.prices.checkpoint.state-store=quarkus-hibernate-orm
mp.messaging.incoming.prices.checkpoint.state-type=org.acme.AveragePriceEntity
mp.messaging.incoming.prices.checkpoint.quarkus-hibernate-orm.persistence-unit=prices
# ... Setup "prices" persistence unit
quarkus.datasource."prices".db-kind=postgresql
quarkus.datasource."prices".username=<your username>
quarkus.datasource."prices".password=<your password>
quarkus.datasource."prices".jdbc.url=jdbc:postgresql://:5432/hibernate_orm_test
quarkus.hibernate-orm."prices".datasource=prices
quarkus.hibernate-orm."prices".packages=org.acme有关如何实现自定义状态存储的说明,请参阅实现状态存储。
5. 发送消息到 Kafka
Kafka 连接器出站通道的配置与入站通道类似。
%prod.kafka.bootstrap.servers=kafka:9092 (1)
mp.messaging.outgoing.prices-out.connector=smallrye-kafka (2)
mp.messaging.outgoing.prices-out.topic=prices (3)| 1 | 为生产环境配置代理位置。您可以在全局配置或使用 mp.messaging.outgoing.$channel.bootstrap.servers 属性按通道配置。在开发模式和测试运行时,Kafka 的开发服务会自动启动一个 Kafka 代理。如果未提供,此属性默认为 localhost:9092。 |
| 2 | 将连接器配置为管理 prices-out 通道。 |
| 3 | 默认情况下,主题名称与通道名称相同。您可以配置 topic 属性来覆盖它。 |
|
在应用程序配置中,通道名称是唯一的。因此,如果您想在同一个主题上配置入站和出站通道,您需要为通道命名不同的名称(如本指南示例中的 |
然后,您的应用程序可以生成消息并将它们发布到 prices-out 通道。它可以使用 double 载荷,如下面的代码片段所示。
import io.smallrye.mutiny.Multi;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
import jakarta.enterprise.context.ApplicationScoped;
import java.time.Duration;
import java.util.Random;
@ApplicationScoped
public class KafkaPriceProducer {
private final Random random = new Random();
@Outgoing("prices-out")
public Multi<Double> generate() {
// Build an infinite stream of random prices
// It emits a price every second
return Multi.createFrom().ticks().every(Duration.ofSeconds(1))
.map(x -> random.nextDouble());
}
}|
您不应从代码中直接调用用 |
请注意,generate 方法返回一个 Multi<Double>,它实现了 Reactive Streams Publisher 接口。此发布者将由框架用于生成消息并将其发送到配置的 Kafka 主题。
与其返回载荷,不如返回 io.smallrye.reactive.messaging.kafka.Record 以发送键/值对。
@Outgoing("out")
public Multi<Record<String, Double>> generate() {
return Multi.createFrom().ticks().every(Duration.ofSeconds(1))
.map(x -> Record.of("my-key", random.nextDouble()));
}载荷可以封装在 org.eclipse.microprofile.reactive.messaging.Message 中,以便更好地控制写入的记录。
@Outgoing("generated-price")
public Multi<Message<Double>> generate() {
return Multi.createFrom().ticks().every(Duration.ofSeconds(1))
.map(x -> Message.of(random.nextDouble())
.addMetadata(OutgoingKafkaRecordMetadata.<String>builder()
.withKey("my-key")
.withTopic("my-key-prices")
.withHeaders(new RecordHeaders().add("my-header", "value".getBytes()))
.build()));
}OutgoingKafkaRecordMetadata 允许设置 Kafka 记录的元数据属性,例如 key、topic、partition 或 timestamp。一种用例是动态选择消息的目标主题。在这种情况下,您不需要在应用程序配置文件中配置主题,而是需要使用出站元数据来设置主题名称。
除了返回 Reactive Stream Publisher 的方法签名(Multi 是 Publisher 的实现)之外,出站方法还可以返回单个消息。在这种情况下,生产者将使用此方法作为生成器来创建无限流。
@Outgoing("prices-out") T generate(); // T excluding void
@Outgoing("prices-out") Message<T> generate();
@Outgoing("prices-out") Uni<T> generate();
@Outgoing("prices-out") Uni<Message<T>> generate();
@Outgoing("prices-out") CompletionStage<T> generate();
@Outgoing("prices-out") CompletionStage<Message<T>> generate();5.1. 使用 Emitter 发送消息
有时,您需要一种命令式发送消息的方式。
例如,如果您需要在接收到 REST 端点中的 POST 请求时将消息发送到流。在这种情况下,您不能使用 @Outgoing,因为您的方法有参数。
为此,您可以使用 Emitter。
import org.eclipse.microprofile.reactive.messaging.Channel;
import org.eclipse.microprofile.reactive.messaging.Emitter;
import jakarta.inject.Inject;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.core.MediaType;
@Path("/prices")
public class PriceResource {
@Inject
@Channel("price-create")
Emitter<Double> priceEmitter;
@POST
@Consumes(MediaType.TEXT_PLAIN)
public void addPrice(Double price) {
CompletionStage<Void> ack = priceEmitter.send(price);
}
}发送载荷会返回一个 CompletionStage,在消息被确认时完成。如果消息传输失败,CompletionStage 将以 nack 的原因异常完成。
|
|
|
使用 |
通过 Emitter API,您还可以将出站载荷封装在 Message<T> 中。与之前的示例一样,Message 允许您以不同的方式处理 ack/nack 情况。
import java.util.concurrent.CompletableFuture;
import org.eclipse.microprofile.reactive.messaging.Channel;
import org.eclipse.microprofile.reactive.messaging.Emitter;
import jakarta.inject.Inject;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.core.MediaType;
@Path("/prices")
public class PriceResource {
@Inject @Channel("price-create") Emitter<Double> priceEmitter;
@POST
@Consumes(MediaType.TEXT_PLAIN)
public void addPrice(Double price) {
priceEmitter.send(Message.of(price)
.withAck(() -> {
// Called when the message is acked
return CompletableFuture.completedFuture(null);
})
.withNack(throwable -> {
// Called when the message is nacked
return CompletableFuture.completedFuture(null);
}));
}
}如果您更喜欢使用 Reactive Stream API,可以使用 MutinyEmitter,它将从 send 方法返回 Uni<Void>。因此,您可以使用 Mutiny API 来处理下游消息和错误。
import org.eclipse.microprofile.reactive.messaging.Channel;
import jakarta.inject.Inject;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.core.MediaType;
import io.smallrye.reactive.messaging.MutinyEmitter;
@Path("/prices")
public class PriceResource {
@Inject
@Channel("price-create")
MutinyEmitter<Double> priceEmitter;
@POST
@Consumes(MediaType.TEXT_PLAIN)
public Uni<String> addPrice(Double price) {
return quoteRequestEmitter.send(price)
.map(x -> "ok")
.onFailure().recoverWithItem("ko");
}
}您也可以使用 sendAndAwait 方法阻塞发送事件到 emitter。它将等到事件被接收方确认或拒绝后才从方法返回。
|
弃用
新的 |
|
弃用
|
有关如何使用 Emitter 的更多信息,请参阅SmallRye Reactive Messaging – Emitters and Channels。
5.2. 写入确认
当 Kafka 代理收到记录时,其确认可能需要一些时间,具体取决于配置。此外,它还会将无法写入的记录存储在内存中。
默认情况下,连接器会等待 Kafka 确认记录后才继续处理(确认接收到的 Message)。您可以通过将 waitForWriteCompletion 属性设置为 false 来禁用此行为。
请注意,acks 属性对记录确认有巨大影响。
如果记录无法写入,则该消息将被拒绝。
5.3. 背压
Kafka 出站连接器处理背压,监控等待写入 Kafka 代理的已发送消息的数量。已发送消息的数量通过 max-inflight-messages 属性配置,默认为 1024。
连接器只并发发送该数量的消息。在至少一条已发送消息被代理确认之前,不会发送其他消息。然后,当代理的已发送消息之一被确认时,连接器将新消息写入 Kafka。请确保相应地配置 Kafka 的 batch.size 和 linger.ms。
您也可以通过将 max-inflight-messages 设置为 0 来删除已发送消息的限制。但是,请注意,如果请求数量达到 max.in.flight.requests.per.connection,Kafka 生产者可能会被阻塞。
5.4. 重试消息分派
当 Kafka 生产者从服务器接收到错误时,如果该错误是暂时的、可恢复的错误,客户端将重试发送消息批次。此行为受 retries 和 retry.backoff.ms 参数控制。此外,SmallRye Reactive Messaging 将根据 retries 和 delivery.timeout.ms 参数重试可恢复错误下的单个消息。
请注意,虽然在可靠系统中进行重试是最佳实践,但 max.in.flight.requests.per.connection 参数默认为 5,这意味着消息顺序不保证。如果消息顺序对您的用例是必需的,将 max.in.flight.requests.per.connection 设置为 1 将确保一次只发送一个消息批次,但这会以牺牲生产者吞吐量为代价。
有关处理错误时应用重试机制,请参阅重试处理部分。
5.5. 处理序列化失败
对于 Kafka 生产者客户端,序列化失败是不可恢复的,因此消息分派不会重试。在这些情况下,您可能需要为序列化器应用失败策略。要实现这一点,您需要创建一个实现 SerializationFailureHandler<T> 接口的 bean。
@ApplicationScoped
@Identifier("failure-fallback") // Set the name of the failure handler
public class MySerializationFailureHandler
implements SerializationFailureHandler<JsonObject> { // Specify the expected type
@Override
public byte[] decorateSerialization(Uni<byte[]> serialization, String topic, boolean isKey,
String serializer, Object data, Headers headers) {
return serialization
.onFailure().retry().atMost(3)
.await().indefinitely();
}
}要使用此失败处理程序,必须使用 @Identifier 限定符暴露 bean,并且连接器配置必须指定 mp.messaging.outgoing.$channel.[key|value]-serialization-failure-handler 属性(用于键或值序列化器)。
处理程序会接收序列化详细信息,包括表示为 Uni<byte[]> 的操作。请注意,方法必须等待结果并返回序列化后的字节数组。
5.6. 内存通道
在某些用例中,使用消息模式在同一应用程序内部传输消息非常方便。当您不将通道连接到 Kafka 等消息后端时,所有操作都在内存中进行,并通过链接方法创建流。每个链仍然是一个反应式流,并强制执行背压协议。
框架会验证生产者/消费者链是否完整,这意味着如果应用程序使用内存通道写入消息(使用仅具有 @Outgoing 的方法,或使用 Emitter),它还必须在应用程序内部从内存通道中消耗消息(使用仅具有 @Incoming 的方法或使用非托管流)。
5.7. 将消息广播到多个消费者
默认情况下,一个通道可以链接到一个使用者,使用 @Incoming 方法或 @Channel 反应式流。在应用程序启动时,通道会进行验证,以形成由单个使用者和生产者组成的消费者和生产者链。您可以通过在通道上设置 mp.messaging.$channel.broadcast=true 来覆盖此行为。
对于内存通道,可以在 @Outgoing 方法上使用 @Broadcast 注释。例如:
import java.util.Random;
import jakarta.enterprise.context.ApplicationScoped;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
import io.smallrye.reactive.messaging.annotations.Broadcast;
@ApplicationScoped
public class MultipleConsumer {
private final Random random = new Random();
@Outgoing("in-memory-channel")
@Broadcast
double generate() {
return random.nextDouble();
}
@Incoming("in-memory-channel")
void consumeAndLog(double price) {
System.out.println(price);
}
@Incoming("in-memory-channel")
@Outgoing("prices2")
double consumeAndSend(double price) {
return price;
}
}|
反之,可以通过设置 |
在出站或处理方法上重复使用 @Outgoing 注释是分派消息到多个出站通道的另一种方式。
import java.util.Random;
import jakarta.enterprise.context.ApplicationScoped;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
@ApplicationScoped
public class MultipleProducers {
private final Random random = new Random();
@Outgoing("generated")
@Outgoing("generated-2")
double priceBroadcast() {
return random.nextDouble();
}
}在前面的示例中,生成的价格将被广播到两个出站通道。下面的示例使用 Targeted 容器对象选择性地将消息发送到多个出站通道,其中键是通道名称,值是消息载荷。
import jakarta.enterprise.context.ApplicationScoped;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
import io.smallrye.reactive.messaging.Targeted;
@ApplicationScoped
public class TargetedProducers {
@Incoming("in")
@Outgoing("out1")
@Outgoing("out2")
@Outgoing("out3")
public Targeted process(double price) {
Targeted targeted = Targeted.of("out1", "Price: " + price,
"out2", "Quote: " + price);
if (price > 90.0) {
return targeted.with("out3", price);
}
return targeted;
}
}请注意,Kafka 序列化器的自动检测不适用于使用 Targeted 的签名。
有关使用多个出站通道的更多详细信息,请参阅SmallRye Reactive Messaging 文档。
5.8. Kafka 事务
Kafka 事务支持对多个 Kafka 主题和分区进行原子写入。Kafka 连接器提供了 KafkaTransactions 自定义 emitter,用于在事务中写入 Kafka 记录。它可以作为常规 emitter @Channel 注入。
import jakarta.enterprise.context.ApplicationScoped;
import org.eclipse.microprofile.reactive.messaging.Channel;
import io.smallrye.mutiny.Uni;
import io.smallrye.reactive.messaging.kafka.KafkaRecord;
import io.smallrye.reactive.messaging.kafka.transactions.KafkaTransactions;
@ApplicationScoped
public class KafkaTransactionalProducer {
@Channel("tx-out-example")
KafkaTransactions<String> txProducer;
public Uni<Void> emitInTransaction() {
return txProducer.withTransaction(emitter -> {
emitter.send(KafkaRecord.of(1, "a"));
emitter.send(KafkaRecord.of(2, "b"));
emitter.send(KafkaRecord.of(3, "c"));
return Uni.createFrom().voidItem();
});
}
}提供给 withTransaction 方法的函数接收一个 TransactionalEmitter 用于生成记录,并返回一个提供事务结果的 Uni。
-
如果处理成功完成,则会刷新生产者并提交事务。
-
如果处理引发异常、返回失败的
Uni或将TransactionalEmitter标记为中止,则会中止事务。
Kafka 事务性生产者需要配置 acks=all 客户端属性,以及 transactional.id 的唯一 ID,这意味着 enable.idempotence=true。当 Quarkus 检测到出站通道使用了 KafkaTransactions 时,它会在通道上配置这些属性,为 transactional.id 属性提供默认值 "${quarkus.application.name}-${channelName}"。
请注意,对于生产使用,transactional.id 在所有应用程序实例之间必须是唯一的。
|
虽然普通消息 emitter 支持并发调用 请注意,在 Reactive Messaging 中,处理方法的执行已经是串行化的,除非使用了 可以在将 Kafka 事务与 Hibernate Reactive 事务链接中找到使用示例。 |
6. Kafka 请求-回复
Kafka 请求-回复模式允许将请求记录发布到 Kafka 主题,然后等待响应初始请求的回复记录。Kafka 连接器提供了 KafkaRequestReply 自定义 emitter,它实现了 Kafka 出站通道的请求-回复模式的请求方(或客户端)。
它可以作为常规 emitter @Channel 注入。
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import org.eclipse.microprofile.reactive.messaging.Channel;
import io.smallrye.mutiny.Uni;
import io.smallrye.reactive.messaging.kafka.reply.KafkaRequestReply;
@ApplicationScoped
@Path("/kafka")
public class KafkaRequestReplyEmitter {
@Channel("request-reply")
KafkaRequestReply<Integer, String> requestReply;
@POST
@Path("/req-rep")
@Produces(MediaType.TEXT_PLAIN)
public Uni<String> post(Integer request) {
return requestReply.request(request);
}
}请求方法将记录发布到出站通道配置的目标主题,并轮询回复主题(默认情况下,目标主题加上 -replies 后缀)以获取回复记录。收到回复后,返回的 Uni 将以记录值完成。请求发送操作会生成一个相关 ID 并设置一个标头(默认为 REPLY_CORRELATION_ID),它期望该标头在回复记录中发回。
回复方可以使用反应式消息处理器来实现(请参阅处理消息)。
有关 Kafka 请求回复功能和高级配置选项的更多信息,请参阅SmallRye Reactive Messaging 文档。
7. 处理消息
流式数据应用程序通常需要从主题消费某些事件,处理它们,并将结果发布到另一个主题。处理器方法可以使用 @Incoming 和 @Outgoing 注释简单地实现。
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
import jakarta.enterprise.context.ApplicationScoped;
@ApplicationScoped
public class PriceProcessor {
private static final double CONVERSION_RATE = 0.88;
@Incoming("price-in")
@Outgoing("price-out")
public double process(double price) {
return price * CONVERSION_RATE;
}
}process 方法的参数是入站消息载荷,而返回值将用作出站消息载荷。先前提到的参数和返回类型的签名也受支持,例如 Message<T>、Record<K, V> 等。
您可以通过消费和返回反应式流 Multi<T> 类型来应用异步流处理。
import jakarta.enterprise.context.ApplicationScoped;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
import io.smallrye.mutiny.Multi;
@ApplicationScoped
public class PriceProcessor {
private static final double CONVERSION_RATE = 0.88;
@Incoming("price-in")
@Outgoing("price-out")
public Multi<Double> process(Multi<Integer> prices) {
return prices.filter(p -> p > 100).map(p -> p * CONVERSION_RATE);
}
}7.1. 传播记录键
在处理消息时,您可以将入站记录键传播到出站记录。
通过 mp.messaging.outgoing.$channel.propagate-record-key=true 配置启用,记录键传播会使用与入站记录相同的键生成出站记录。
如果出站记录已包含键,则它不会被覆盖入站记录键。如果入站记录确实有一个null 键,则使用 mp.messaging.outgoing.$channel.key 属性。
7.2. 精确一次处理
Kafka 事务允许在事务中管理消费者偏移量以及生成的 P 消息。这使得在消费-转换-生产模式(也称为精确一次处理)中将消费者与事务性生产者耦合成为可能。
KafkaTransactions 自定义 emitter 提供了一种在事务中将精确一次处理应用于入站 Kafka 消息的方法。
以下示例在事务中包含了一批 Kafka 记录。
import jakarta.enterprise.context.ApplicationScoped;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.eclipse.microprofile.reactive.messaging.Channel;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Message;
import org.eclipse.microprofile.reactive.messaging.OnOverflow;
import io.smallrye.mutiny.Uni;
import io.smallrye.reactive.messaging.kafka.KafkaRecord;
import io.smallrye.reactive.messaging.kafka.transactions.KafkaTransactions;
@ApplicationScoped
public class KafkaExactlyOnceProcessor {
@Channel("prices-out")
@OnOverflow(value = OnOverflow.Strategy.BUFFER, bufferSize = 500) (3)
KafkaTransactions<Integer> txProducer;
@Incoming("prices-in")
public Uni<Void> emitInTransaction(Message<ConsumerRecords<String, Integer>> batch) { (1)
return txProducer.withTransactionAndAck(batch, emitter -> { (2)
for (ConsumerRecord<String, Integer> record : batch.getPayload()) {
emitter.send(KafkaRecord.of(record.key(), record.value() + 1)); (3)
}
return Uni.createFrom().voidItem();
});
}
}| 1 | 建议将精确一次处理与批处理模式一起使用。虽然可以与单个 Kafka 消息一起使用,但性能会受到很大影响。 |
| 2 | 消费的消息被传递到 KafkaTransactions#withTransactionAndAck 以处理偏移量提交和消息确认。 |
| 3 | send 方法在事务中将记录写入 Kafka,而无需等待代理的发送回执。待写入 Kafka 的消息将被缓冲,并在提交事务之前刷新。因此,建议配置 @OnOverflow bufferSize 以适应足够的消息,例如 max.poll.records,即批次中返回的最大记录数。
|
使用精确一次处理时,消费的消息偏移量提交由事务处理,因此应用程序不应通过其他方式提交偏移量。消费者应将 enable.auto.commit 设置为 false(默认值),并显式设置 commit-strategy=ignore。
mp.messaging.incoming.prices-in.commit-strategy=ignore
mp.messaging.incoming.prices-in.failure-strategy=ignore7.2.1. 精确一次处理的错误处理
从 KafkaTransactions#withTransaction 返回的 Uni 如果事务失败并被中止,将会产生一个失败。应用程序可以选择处理错误情况,但如果从 @Incoming 方法返回一个失败的 Uni,入站通道将有效地失败并停止反应式流。
KafkaTransactions#withTransactionAndAck 方法会确认和拒绝消息,但不会返回失败的 Uni。拒绝的消息将由入站通道的失败策略处理(请参阅错误处理策略)。将 failure-strategy=ignore 配置为简单地将 Kafka 消费者重置为最后提交的偏移量并从中恢复消费。
8. 直接访问 Kafka 客户端
在极少数情况下,您可能需要访问底层的 Kafka 客户端。KafkaClientService 提供对 Producer 和 Consumer 的线程安全访问。
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.enterprise.event.Observes;
import jakarta.inject.Inject;
import org.apache.kafka.clients.producer.ProducerRecord;
import io.quarkus.runtime.StartupEvent;
import io.smallrye.reactive.messaging.kafka.KafkaClientService;
import io.smallrye.reactive.messaging.kafka.KafkaConsumer;
import io.smallrye.reactive.messaging.kafka.KafkaProducer;
@ApplicationScoped
public class PriceSender {
@Inject
KafkaClientService clientService;
void onStartup(@Observes StartupEvent startupEvent) {
KafkaProducer<String, Double> producer = clientService.getProducer("generated-price");
producer.runOnSendingThread(client -> client.send(new ProducerRecord<>("prices", 2.4)))
.await().indefinitely();
}
}|
|
您还可以获取注入到应用程序中的 Kafka 配置,并直接创建 Kafka 生产者、消费者和管理客户端。
import io.smallrye.common.annotation.Identifier;
import org.apache.kafka.clients.admin.AdminClient;
import org.apache.kafka.clients.admin.AdminClientConfig;
import org.apache.kafka.clients.admin.KafkaAdminClient;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.enterprise.inject.Produces;
import jakarta.inject.Inject;
import java.util.HashMap;
import java.util.Map;
@ApplicationScoped
public class KafkaClients {
@Inject
@Identifier("default-kafka-broker")
Map<String, Object> config;
@Produces
AdminClient getAdmin() {
Map<String, Object> copy = new HashMap<>();
for (Map.Entry<String, Object> entry : config.entrySet()) {
if (AdminClientConfig.configNames().contains(entry.getKey())) {
copy.put(entry.getKey(), entry.getValue());
}
}
return KafkaAdminClient.create(copy);
}
}default-kafka-broker 配置映射包含所有以 kafka. 或 KAFKA_ 为前缀的应用程序属性。有关更多配置选项,请查看Kafka 配置解析。
9. JSON 序列化
Quarkus 具有处理 JSON Kafka 消息的内置功能。
假设我们有一个 Fruit 数据类如下:
public class Fruit {
public String name;
public int price;
public Fruit() {
}
public Fruit(String name, int price) {
this.name = name;
this.price = price;
}
}我们想用它来从 Kafka 接收消息,进行一些价格转换,然后将消息发送回 Kafka。
import io.smallrye.reactive.messaging.annotations.Broadcast;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
import jakarta.enterprise.context.ApplicationScoped;
/**
* A bean consuming data from the "fruit-in" channel and applying some price conversion.
* The result is pushed to the "fruit-out" channel.
*/
@ApplicationScoped
public class FruitProcessor {
private static final double CONVERSION_RATE = 0.88;
@Incoming("fruit-in")
@Outgoing("fruit-out")
@Broadcast
public Fruit process(Fruit fruit) {
fruit.price = fruit.price * CONVERSION_RATE;
return fruit;
}
}要做到这一点,我们需要设置带有 Jackson 或 JSON-B 的 JSON 序列化。
配置好 JSON 序列化后,您还可以使用 Publisher<Fruit> 和 Emitter<Fruit>。 |
9.1. 通过 Jackson 序列化
Quarkus 具有基于 Jackson 的 JSON 序列化和反序列化内置支持。它还将生成序列化器和反序列化器,因此您无需配置任何内容。当禁用生成时,您可以按如下方式使用提供的 ObjectMapperSerializer 和 ObjectMapperDeserializer。
存在一个现有的 ObjectMapperSerializer,可用于通过 Jackson 序列化所有数据对象。如果您想使用序列化器/反序列化器自动检测,您可以创建一个空的子类。
默认情况下,ObjectMapperSerializer 将 null 序列化为 "null" 字符串,可以通过设置 Kafka 配置属性 json.serialize.null-as-null=true 来自定义,这将把 null 序列化为 null。这在使用压缩主题时非常有用,因为 null 用作墓碑,用于在压缩阶段知道要删除哪些消息。 |
相应的反序列化器类需要被子类化。因此,让我们创建一个扩展 ObjectMapperDeserializer 的 FruitDeserializer。
package com.acme.fruit.jackson;
import io.quarkus.kafka.client.serialization.ObjectMapperDeserializer;
public class FruitDeserializer extends ObjectMapperDeserializer<Fruit> {
public FruitDeserializer() {
super(Fruit.class);
}
}最后,配置您的通道以使用 Jackson 序列化器和反序列化器。
# Configure the Kafka source (we read from it)
mp.messaging.incoming.fruit-in.topic=fruit-in
mp.messaging.incoming.fruit-in.value.deserializer=com.acme.fruit.jackson.FruitDeserializer
# Configure the Kafka sink (we write to it)
mp.messaging.outgoing.fruit-out.topic=fruit-out
mp.messaging.outgoing.fruit-out.value.serializer=io.quarkus.kafka.client.serialization.ObjectMapperSerializer现在,您的 Kafka 消息将包含 Fruit 数据对象的 Jackson 序列化表示。在这种情况下,不需要 deserializer 配置,因为序列化器/反序列化器自动检测默认已启用。
如果您想反序列化水果列表,您需要创建一个带有 Jackson TypeReference 的反序列化器来表示使用的泛型集合。
package com.acme.fruit.jackson;
import java.util.List;
import com.fasterxml.jackson.core.type.TypeReference;
import io.quarkus.kafka.client.serialization.ObjectMapperDeserializer;
public class ListOfFruitDeserializer extends ObjectMapperDeserializer<List<Fruit>> {
public ListOfFruitDeserializer() {
super(new TypeReference<List<Fruit>>() {});
}
}9.2. 通过 JSON-B 序列化
首先,您需要包含 quarkus-jsonb 扩展。
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-jsonb</artifactId>
</dependency>implementation("io.quarkus:quarkus-jsonb")存在一个现有的 JsonbSerializer,可用于通过 JSON-B 序列化所有数据对象。如果您想使用序列化器/反序列化器自动检测,您可以创建一个空的子类。
默认情况下,JsonbSerializer 将 null 序列化为 "null" 字符串,可以通过设置 Kafka 配置属性 json.serialize.null-as-null=true 来自定义,这将把 null 序列化为 null。这在使用压缩主题时非常有用,因为 null 用作墓碑,用于在压缩阶段知道要删除哪些消息。 |
相应的反序列化器类需要被子类化。因此,让我们创建一个扩展通用 JsonbDeserializer 的 FruitDeserializer。
package com.acme.fruit.jsonb;
import io.quarkus.kafka.client.serialization.JsonbDeserializer;
public class FruitDeserializer extends JsonbDeserializer<Fruit> {
public FruitDeserializer() {
super(Fruit.class);
}
}最后,配置您的通道以使用 JSON-B 序列化器和反序列化器。
# Configure the Kafka source (we read from it)
mp.messaging.incoming.fruit-in.connector=smallrye-kafka
mp.messaging.incoming.fruit-in.topic=fruit-in
mp.messaging.incoming.fruit-in.value.deserializer=com.acme.fruit.jsonb.FruitDeserializer
# Configure the Kafka sink (we write to it)
mp.messaging.outgoing.fruit-out.connector=smallrye-kafka
mp.messaging.outgoing.fruit-out.topic=fruit-out
mp.messaging.outgoing.fruit-out.value.serializer=io.quarkus.kafka.client.serialization.JsonbSerializer现在,您的 Kafka 消息将包含 Fruit 数据对象的 JSON-B 序列化表示。
如果您想反序列化水果列表,您需要创建一个带有 Type 的反序列化器来表示使用的泛型集合。
package com.acme.fruit.jsonb;
import java.lang.reflect.Type;
import java.util.ArrayList;
import java.util.List;
import io.quarkus.kafka.client.serialization.JsonbDeserializer;
public class ListOfFruitDeserializer extends JsonbDeserializer<List<Fruit>> {
public ListOfFruitDeserializer() {
super(new ArrayList<MyEntity>() {}.getClass().getGenericSuperclass());
}
}如果您不想为每个数据对象创建反序列化器,您可以使用通用的 io.vertx.kafka.client.serialization.JsonObjectDeserializer,它将反序列化为 io.vertx.core.json.JsonObject。也可以使用相应的序列化器:io.vertx.kafka.client.serialization.JsonObjectSerializer。 |
10. Avro 序列化
这在专门的指南中有描述:将 Apache Kafka 与 Schema Registry 和 Avro 结合使用。
11. JSON Schema 序列化
这在专门的指南中有描述:将 Apache Kafka 与 Schema Registry 和 JSON Schema 结合使用。
12. 序列化器/反序列化器自动检测
当使用 Quarkus Messaging 与 Kafka(io.quarkus:quarkus-messaging-kafka)时,Quarkus 通常可以自动检测正确的序列化器和反序列化器类。此自动检测基于 @Incoming 和 @Outgoing 方法的声明,以及注入的 @Channel。
例如,如果您声明:
@Outgoing("generated-price")
public Multi<Integer> generate() {
...
}并且您的配置表明 generated-price 通道使用 smallrye-kafka 连接器,那么 Quarkus 将自动将 value.serializer 设置为 Kafka 内置的 IntegerSerializer。
同样,如果您声明:
@Incoming("my-kafka-records")
public void consume(Record<Long, byte[]> record) {
...
}并且您的配置表明 my-kafka-records 通道使用 smallrye-kafka 连接器,那么 Quarkus 将自动将 key.deserializer 设置为 Kafka 内置的 LongDeserializer,并将 value.deserializer 设置为 ByteArrayDeserializer。
最后,如果您声明:
@Inject
@Channel("price-create")
Emitter<Double> priceEmitter;并且您的配置表明 price-create 通道使用 smallrye-kafka 连接器,那么 Quarkus 将自动将 value.serializer 设置为 Kafka 内置的 DoubleSerializer。
序列化器/反序列化器自动检测支持的完整类型集是:
-
short和java.lang.Short -
int和java.lang.Integer -
long和java.lang.Long -
float和java.lang.Float -
double和java.lang.Double -
byte[] -
java.lang.String -
java.util.UUID -
java.nio.ByteBuffer -
org.apache.kafka.common.utils.Bytes -
io.vertx.core.buffer.Buffer -
io.vertx.core.json.JsonObject -
io.vertx.core.json.JsonArray -
存在
org.apache.kafka.common.serialization.Serializer<T>/org.apache.kafka.common.serialization.Deserializer<T>直接实现的类。-
实现需要指定类型参数
T作为(反)序列化类型。
-
-
从 Avro Schema 生成的类,以及 Avro
GenericRecord,如果存在 Confluent 或 Apicurio Registry serde。-
如果存在多个 Avro serde,则必须为 Avro 生成的类手动配置序列化器/反序列化器,因为无法自动检测。
-
有关使用 Confluent 或 Apicurio Registry 库的信息,请参阅将 Apache Kafka 与 Schema Registry 和 Avro 结合使用。
-
-
存在
ObjectMapperSerializer/ObjectMapperDeserializer的子类的类,如通过 Jackson 序列化中所述。-
技术上不需要子类化
ObjectMapperSerializer,但在这种情况下,无法自动检测。
-
-
存在
JsonbSerializer/JsonbDeserializer的子类的类,如通过 JSON-B 序列化中所述。-
技术上不需要子类化
JsonbSerializer,但在这种情况下,无法自动检测。
-
如果通过配置设置了序列化器/反序列化器,则自动检测不会替换它。
如果您在序列化器自动检测方面遇到任何问题,可以通过设置 quarkus.messaging.kafka.serializer-autodetection.enabled=false 来完全关闭它。如果您发现需要这样做,请在 Quarkus 问题跟踪器 中提交一个 bug,以便我们能解决您遇到的任何问题。
13. JSON 序列化器/反序列化器生成
Quarkus 会自动为以下情况生成序列化器和反序列化器:
-
未配置序列化器/反序列化器
-
自动检测未找到匹配的序列化器/反序列化器
它底层使用 Jackson。
可以使用以下方式禁用此生成:
quarkus.messaging.kafka.serializer-generation.enabled=false生成不支持集合,例如 List<Fruit>。请参阅 通过 Jackson 进行序列化 来为这种情况编写您自己的序列化器/反序列化器。 |
14. 使用 Schema Registry
这在 Avro 的专用指南中进行了介绍:将 Apache Kafka 与 Schema Registry 和 Avro 结合使用。以及 JSON Schema 的另一份指南:将 Apache Kafka 与 Schema Registry 和 JSON Schema 结合使用。
15. 健康检查
Quarkus 为 Kafka 提供了一些健康检查。这些检查与 quarkus-smallrye-health 扩展结合使用。
15.1. Kafka Broker 就绪检查
使用 quarkus-kafka-client 扩展时,您可以通过在 application.properties 中将 quarkus.kafka.health.enabled 属性设置为 true 来启用*就绪*健康检查。此检查报告与*默认* Kafka Broker(使用 kafka.bootstrap.servers 配置)的交互状态。它需要与 Kafka Broker 的*管理连接*,并且默认情况下处于禁用状态。如果启用,当您访问应用程序的 /q/health/ready 端点时,您将获得关于连接验证状态的信息。
15.2. Kafka Reactive Messaging 健康检查
使用 Reactive Messaging 和 Kafka 连接器时,每个配置的通道(入站或出站)都提供*启动*、*活跃性*和*就绪*检查。
-
启动检查会验证与 Kafka 集群的通信是否已建立。
-
活跃性检查会捕获在与 Kafka 通信期间发生的任何不可恢复的故障。
-
就绪检查会验证 Kafka 连接器是否已准备好向配置的 Kafka 主题进行消息的消费/生产。
对于每个通道,您可以使用以下方式禁用检查:
# Disable both liveness and readiness checks with `health-enabled=false`:
# Incoming channel (receiving records form Kafka)
mp.messaging.incoming.your-channel.health-enabled=false
# Outgoing channel (writing records to Kafka)
mp.messaging.outgoing.your-channel.health-enabled=false
# Disable only the readiness check with `health-readiness-enabled=false`:
mp.messaging.incoming.your-channel.health-readiness-enabled=false
mp.messaging.outgoing.your-channel.health-readiness-enabled=false您可以使用 mp.messaging.incoming|outgoing.$channel.bootstrap.servers 属性为每个通道配置 bootstrap.servers。默认值为 kafka.bootstrap.servers。 |
Reactive Messaging 的*启动*和*就绪*检查提供了两种策略。默认策略会验证与 Broker 是否已建立活动连接。这种方法不具侵扰性,因为它基于内置的 Kafka 客户端指标。
通过使用 health-topic-verification-enabled=true 属性,*启动*探测器会使用*管理客户端*检查主题列表。而*就绪*探测器对于入站通道会检查是否至少分配了一个分区用于消费,对于出站通道会检查生产者使用的主题是否存在于 Broker 中。
请注意,要实现这一点,需要*管理连接*。您可以使用 health-topic-verification-timeout 配置来调整与 Broker 的主题验证调用的超时时间。
16. 可观察性
如果存在 OpenTelemetry 扩展,则 Kafka 连接器通道可以开箱即用地与 OpenTelemetry Tracing 集成。写入 Kafka 主题的消息会传播当前的跟踪 span。对于入站通道,如果消费的 Kafka 记录包含跟踪信息,则消息处理会继承消息 span 作为父级。
可以为每个通道显式禁用跟踪:
mp.messaging.incoming.data.tracing-enabled=false如果存在 Micrometer 扩展,则 Kafka 生产者和消费者客户端的指标会作为 Micrometer 指标暴露。
16.1. 通道指标
也可以收集每个通道的指标并将其作为 Micrometer 指标暴露。可以收集以下指标,每个通道由*通道*标签标识:
-
quarkus.messaging.message.count:生产或接收的消息数量 -
quarkus.messaging.message.acks:成功处理的消息数量 -
quarkus.messaging.message.failures:处理失败的消息数量 -
quarkus.messaging.message.duration:消息处理的持续时间。
出于向后兼容的原因,通道指标默认不启用,可以通过以下方式启用:
|
消息*观察*依赖于拦截消息,因此不支持消费具有自定义消息类型(如 消息拦截和观察仍然支持消费通用 |
smallrye.messaging.observation.enabled=true17. Kafka Streams
这在专用指南中进行了介绍:将 Apache Kafka Streams 结合使用。
18. 使用 Snappy 进行消息压缩
在*出站*通道上,可以通过将 compression.type 属性设置为 snappy 来启用 Snappy 压缩。
mp.messaging.outgoing.fruit-out.compression.type=snappy在 JVM 模式下,它可以开箱即用。但是,要将应用程序编译为本地可执行文件,您需要在 application.properties 中添加 quarkus.kafka.snappy.enabled=true。
在原生模式下,Snappy 默认是禁用的,因为使用 Snappy 需要嵌入本地库并在应用程序启动时解包。
19. 使用 OAuth 进行身份验证
如果您的 Kafka Broker 使用 OAuth 作为身份验证机制,您需要配置 Kafka 消费者来启用此身份验证过程。首先,将以下依赖项添加到您的应用程序中:
<dependency>
<groupId>io.strimzi</groupId>
<artifactId>kafka-oauth-client</artifactId>
</dependency>
<!-- if compiling to native you'd need also the following dependency -->
<dependency>
<groupId>io.strimzi</groupId>
<artifactId>kafka-oauth-common</artifactId>
</dependency>implementation("io.strimzi:kafka-oauth-client")
// if compiling to native you'd need also the following dependency
implementation("io.strimzi:kafka-oauth-common")此依赖项提供了处理 OAuth 工作流程所需的 callback handler。然后,在 application.properties 中添加:
mp.messaging.connector.smallrye-kafka.security.protocol=SASL_PLAINTEXT
mp.messaging.connector.smallrye-kafka.sasl.mechanism=OAUTHBEARER
mp.messaging.connector.smallrye-kafka.sasl.jaas.config=org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required \
oauth.client.id="team-a-client" \
oauth.client.secret="team-a-client-secret" \
oauth.token.endpoint.uri="http://keycloak:8080/auth/realms/kafka-authz/protocol/openid-connect/token" ;
mp.messaging.connector.smallrye-kafka.sasl.login.callback.handler.class=io.strimzi.kafka.oauth.client.JaasClientOauthLoginCallbackHandler
quarkus.ssl.native=true更新 oauth.client.id、oauth.client.secret 和 oauth.token.endpoint.uri 的值。
OAuth 身份验证支持 JVM 和原生模式。由于原生模式下 SSL 默认不启用,因此必须添加 quarkus.ssl.native=true 来支持 JaasClientOauthLoginCallbackHandler,因为它使用了 SSL。(有关更多详细信息,请参阅 在原生可执行文件中使用 SSL 指南。)
20. TLS 配置
Kafka 客户端扩展与 Quarkus TLS 注册表 集成以配置客户端。
要为默认 Kafka 配置 TLS,您需要在 application.properties 中提供一个命名的 TLS 配置:
quarkus.tls.your-tls-config.trust-store.pem.certs=target/certs/kafka.crt,target/certs/kafka-ca.crt
# ...
kafka.tls-configuration-name=your-tls-config
# enable ssl security protocol
kafka.security.protocol=ssl这将为 Kafka 客户端提供一个 ssl.engine.factory.class 实现。
|
还要确保使用 |
Quarkus Messaging 通道可以单独配置以使用特定的 TLS 配置:
mp.messaging.incoming.your-channel.tls-configuration-name=your-tls-config
mp.messaging.incoming.your-channel.security.protocol=ssl21. 测试 Kafka 应用程序
21.1. 无 Broker 测试
在不启动 Kafka Broker 的情况下测试应用程序可能很有用。要实现这一点,您可以将 Kafka 连接器管理的通道*切换*为*内存*模式。
| 此方法仅适用于 JVM 测试。不能用于原生测试(因为它们不支持注入)。 |
假设我们要测试以下处理器应用程序:
@ApplicationScoped
public class BeverageProcessor {
@Incoming("orders")
@Outgoing("beverages")
Beverage process(Order order) {
System.out.println("Order received " + order.getProduct());
Beverage beverage = new Beverage();
beverage.setBeverage(order.getProduct());
beverage.setCustomer(order.getCustomer());
beverage.setOrderId(order.getOrderId());
beverage.setPreparationState("RECEIVED");
return beverage;
}
}首先,将以下测试依赖项添加到您的应用程序中:
<dependency>
<groupId>io.smallrye.reactive</groupId>
<artifactId>smallrye-reactive-messaging-in-memory</artifactId>
<scope>test</scope>
</dependency>testImplementation("io.smallrye.reactive:smallrye-reactive-messaging-in-memory")然后,创建如下的 Quarkus 测试资源:
public class KafkaTestResourceLifecycleManager implements QuarkusTestResourceLifecycleManager {
@Override
public Map<String, String> start() {
Map<String, String> env = new HashMap<>();
Map<String, String> props1 = InMemoryConnector.switchIncomingChannelsToInMemory("orders"); (1)
Map<String, String> props2 = InMemoryConnector.switchOutgoingChannelsToInMemory("beverages"); (2)
env.putAll(props1);
env.putAll(props2);
return env; (3)
}
@Override
public void stop() {
InMemoryConnector.clear(); (4)
}
}| 1 | 将入站通道 orders(预期来自 Kafka 的消息)切换为内存模式。 |
| 2 | 将出站通道 beverages(向 Kafka 写入消息)切换为内存模式。 |
| 3 | 构建并返回一个 Map,其中包含配置应用程序使用内存通道所需的所有属性。 |
| 4 | 测试停止时,清除 InMemoryConnector(丢弃所有接收和发送的消息)。 |
使用上面创建的测试资源创建 Quarkus 测试:
import static org.awaitility.Awaitility.await;
@QuarkusTest
@QuarkusTestResource(KafkaTestResourceLifecycleManager.class)
class BaristaTest {
@Inject
@Connector("smallrye-in-memory")
InMemoryConnector connector; (1)
@Test
void testProcessOrder() {
InMemorySource<Order> ordersIn = connector.source("orders"); (2)
InMemorySink<Beverage> beveragesOut = connector.sink("beverages"); (3)
Order order = new Order();
order.setProduct("coffee");
order.setName("Coffee lover");
order.setOrderId("1234");
ordersIn.send(order); (4)
await().<List<? extends Message<Beverage>>>until(beveragesOut::received, t -> t.size() == 1); (5)
Beverage queuedBeverage = beveragesOut.received().get(0).getPayload();
Assertions.assertEquals(Beverage.State.READY, queuedBeverage.getPreparationState());
Assertions.assertEquals("coffee", queuedBeverage.getBeverage());
Assertions.assertEquals("Coffee lover", queuedBeverage.getCustomer());
Assertions.assertEquals("1234", queuedBeverage.getOrderId());
}
}| 1 | 将内存连接器注入您的测试类: |
| 2 | 检索入站通道(orders)- 该通道必须已在测试资源中切换为内存模式。 |
| 3 | 检索出站通道(beverages)- 该通道必须已在测试资源中切换为内存模式。 |
| 4 | 使用 send 方法向 orders 通道发送消息。应用程序将处理此消息并将消息发送到 beverages 通道。 |
| 5 | 使用 received 方法在 beverages 通道上检查应用程序产生的消息。 |
如果您的 Kafka 消费者是基于批处理的,您需要发送一批消息到通道,方法是手动创建它们。
例如
@ApplicationScoped
public class BeverageProcessor {
@Incoming("orders")
CompletionStage<Void> process(KafkaRecordBatch<String, Order> orders) {
System.out.println("Order received " + orders.getPayload().size());
return orders.ack();
}
}import static org.awaitility.Awaitility.await;
@QuarkusTest
@QuarkusTestResource(KafkaTestResourceLifecycleManager.class)
class BaristaTest {
@Inject
@Connector("smallrye-in-memory")
InMemoryConnector connector;
@Test
void testProcessOrder() {
InMemorySource<IncomingKafkaRecordBatch<String, Order>> ordersIn = connector.source("orders");
var committed = new AtomicBoolean(false); (1)
var commitHandler = new KafkaCommitHandler() {
@Override
public <K, V> Uni<Void> handle(IncomingKafkaRecord<K, V> record) {
committed.set(true); (2)
return null;
}
};
var failureHandler = new KafkaFailureHandler() {
@Override
public <K, V> Uni<Void> handle(IncomingKafkaRecord<K, V> record, Throwable reason, Metadata metadata) {
return null;
}
};
Order order = new Order();
order.setProduct("coffee");
order.setName("Coffee lover");
order.setOrderId("1234");
var record = new ConsumerRecord<>("topic", 0, 0, "key", order);
var records = new ConsumerRecords<>(Map.of(new TopicPartition("topic", 1), List.of(record)));
var batch = new IncomingKafkaRecordBatch<>(
records, "kafka", 0, commitHandler, failureHandler, false, false); (3)
ordersIn.send(batch);
await().until(committed::get); (4)
}
}| 1 | 创建一个 AtomicBoolean 来跟踪批次是否已提交。 |
| 2 | 当批次提交时更新 committed。 |
| 3 | 创建一个包含单个记录的 IncomingKafkaRecordBatch。 |
| 4 | 等待批次提交。 |
|
通过内存通道,我们能够在不启动 Kafka Broker 的情况下测试处理消息的应用程序代码。请注意,不同的内存通道是独立的,将通道连接器切换到内存模式并不会模拟配置为同一 Kafka 主题的通道之间的消息传递。 |
21.1.1. 使用 InMemoryConnector 进行上下文传播
默认情况下,内存通道在调用者线程(在单元测试中是主线程)上分发消息。
quarkus-test-vertx 依赖项提供了 @io.quarkus.test.vertx.RunOnVertxContext 注释,当在测试方法上使用时,它会在 Vert.x 上下文中执行测试。
然而,大多数其他连接器都会处理上下文传播,在单独的 Vert.x 上下文副本上分发消息。
如果您的测试依赖于上下文传播,您可以通过使用 run-on-vertx-context 属性配置内存连接器通道,在 Vert.x 上下文中分发事件,包括消息和确认。或者,您可以使用 InMemorySource#runOnVertxContext 方法切换此行为。
21.2. 使用 Kafka Broker 进行测试
如果您正在使用 Kafka 开发服务,那么在测试期间 Kafka Broker 会启动并可用,除非它在 %test 配置文件中被禁用。虽然可以通过 Kafka Clients API 连接到此 Broker,但 Kafka Companion Library 提供了一种更简单的方式来与 Kafka Broker 交互,并在测试中创建消费者、生产者和管理操作。
要在测试中使用 KafkaCompanion API,请首先添加以下依赖项:
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-test-kafka-companion</artifactId>
<scope>test</scope>
</dependency>它提供了 io.quarkus.test.kafka.KafkaCompanionResource - io.quarkus.test.common.QuarkusTestResourceLifecycleManager 的一个实现。
然后使用 @QuarkusTestResource 在测试中配置 Kafka Companion,例如:
import static org.junit.jupiter.api.Assertions.assertEquals;
import java.util.UUID;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.junit.jupiter.api.Test;
import io.quarkus.test.common.QuarkusTestResource;
import io.quarkus.test.junit.QuarkusTest;
import io.quarkus.test.kafka.InjectKafkaCompanion;
import io.quarkus.test.kafka.KafkaCompanionResource;
import io.smallrye.reactive.messaging.kafka.companion.ConsumerTask;
import io.smallrye.reactive.messaging.kafka.companion.KafkaCompanion;
@QuarkusTest
@QuarkusTestResource(KafkaCompanionResource.class)
public class OrderProcessorTest {
@InjectKafkaCompanion (1)
KafkaCompanion companion;
@Test
void testProcessor() {
companion.produceStrings().usingGenerator(i -> new ProducerRecord<>("orders", UUID.randomUUID().toString())); (2)
// Expect that the tested application processes orders from 'orders' topic and write to 'orders-processed' topic
ConsumerTask<String, String> orders = companion.consumeStrings().fromTopics("orders-processed", 10); (3)
orders.awaitCompletion(); (4)
assertEquals(10, orders.count());
}
}| 1 | @InjectKafkaCompanion 注入 KafkaCompanion 实例,该实例已配置为访问为测试创建的 Kafka Broker。 |
| 2 | 使用 KafkaCompanion 创建生产者任务,将 10 条记录写入 'orders' 主题。 |
| 3 | 创建消费者任务,订阅 'orders-processed' 主题并消费 10 条记录。 |
| 4 | 等待消费者任务完成。 |
|
您需要配置: 否则,您将在 <4> 中收到 |
|
如果 Kafka 开发服务在测试期间可用, 可以使用 |
21.2.1. 自定义测试资源
或者,您可以在测试资源中启动一个 Kafka Broker。以下代码片段展示了一个使用 Testcontainers 启动 Kafka Broker 的测试资源:
public class KafkaResource implements QuarkusTestResourceLifecycleManager {
private final KafkaContainer kafka = new KafkaContainer();
@Override
public Map<String, String> start() {
kafka.start();
return Collections.singletonMap("kafka.bootstrap.servers", kafka.getBootstrapServers()); (1)
}
@Override
public void stop() {
kafka.close();
}
}| 1 | 配置 Kafka 的 bootstrap 位置,以便应用程序连接到此 Broker。 |
22. Kafka 开发服务
如果存在任何 Kafka 相关扩展(例如 quarkus-messaging-kafka),Kafka 开发服务会在开发模式和测试运行时自动启动一个 Kafka Broker。因此,您无需手动启动 Broker。应用程序会自动配置。
| 由于启动 Kafka Broker 可能需要较长时间,Kafka 开发服务使用 Redpanda,一个与 Kafka 兼容的 Broker,它可以在约 1 秒内启动。 |
22.1. 启用/禁用 Kafka 开发服务
Kafka 开发服务自动启用,除非:
-
quarkus.kafka.devservices.enabled设置为false -
已配置
kafka.bootstrap.servers -
所有 Reactive Messaging Kafka 通道都已配置了
bootstrap.servers属性
Kafka 开发服务依赖 Docker 来启动 Broker。如果您的环境不支持 Docker,您需要手动启动 Broker,或连接到已运行的 Broker。您可以使用 kafka.bootstrap.servers 配置 Broker 地址。
22.2. 共享 Broker
大多数情况下,您需要共享 Broker。Kafka 开发服务实现了*服务发现*机制,供多个 Quarkus 应用程序在*开发*模式下共享单个 Broker。
Kafka 开发服务使用 quarkus-dev-service-kafka 标签启动容器,该标签用于标识容器。 |
如果您需要多个(共享)Broker,您可以配置 quarkus.kafka.devservices.service-name 属性并指定 Broker 名称。它会查找具有相同值的容器,如果找不到则启动一个新的。默认服务名称是 kafka。
共享在开发模式下默认启用,但在测试模式下禁用。您可以使用 quarkus.kafka.devservices.shared=false 来禁用共享。
22.3. 设置端口
默认情况下,Kafka 开发服务会选择一个随机端口并配置应用程序。您可以通过配置 quarkus.kafka.devservices.port 属性来设置端口。
请注意,Kafka 的广告地址会自动配置为所选端口。
22.4. 配置镜像
Kafka 开发服务支持 Redpanda、kafka-native 和 Strimzi(在 Kraft 模式下)镜像。
Redpanda 是一个与 Kafka 兼容的事件流平台。由于它提供快速的启动时间,开发服务默认使用 redpandadata/redpanda 的 Redpanda 镜像。您可以从 https://hub.docker.com/r/redpandadata/redpanda 中选择任何版本。
kafka-native 提供标准 Apache Kafka 发行版的镜像,使用 Quarkus 和 GraalVM 编译为原生二进制文件。尽管仍处于*实验*阶段,但它提供了非常快的启动时间和较小的占用空间。
镜像类型可以通过以下方式配置:
quarkus.kafka.devservices.provider=kafka-nativeStrimzi 为在 Kubernetes 上运行 Apache Kafka 提供容器镜像和 Operator。虽然 Strimzi 针对 Kubernetes 进行了优化,但这些镜像在经典的容器环境中也能完美运行。Strimzi 容器镜像在 JVM 上运行*真正的* Kafka Broker,启动速度较慢。
quarkus.kafka.devservices.provider=strimzi对于 Strimzi,您可以从 https://quay.io/repository/strimzi-test-container/test-container?tab=tags 中选择支持 Kraft 的任何 Kafka 版本镜像(2.8.1 及更高版本)。
quarkus.kafka.devservices.image-name=quay.io/strimzi-test-container/test-container:0.106.0-kafka-3.7.022.5. 配置 Kafka 主题
您可以配置 Kafka 开发服务在 Broker 启动后创建主题。主题将以给定的分区数和 1 个副本创建。
以下示例创建一个名为 test 的主题,包含 3 个分区,以及第二个名为 messages 的主题,包含 2 个分区。
quarkus.kafka.devservices.topic-partitions.test=3
quarkus.kafka.devservices.topic-partitions.messages=2如果具有给定名称的主题已存在,则会跳过创建,而不会尝试将现有主题重新分区为不同数量的分区。
您可以使用 quarkus.kafka.devservices.topic-partitions-timeout 配置 Kafka 管理客户端调用主题创建的超时时间,默认为 2 秒。
22.6. 事务性和幂等生产者支持
默认情况下,Redpanda Broker 配置为启用事务和幂等性功能。您可以使用以下方式禁用它们:
quarkus.kafka.devservices.redpanda.transaction-enabled=false| Redpanda 事务不支持精确一次处理。 |
22.7. Compose
Kafka 开发服务支持 Compose 开发服务。它依赖于 compose-devservices.yml,例如:
name: <application name>
services:
kafka:
image: apache/kafka-native:3.9.0
restart: "no"
ports:
- '9092'
labels:
io.quarkus.devservices.compose.exposed_ports: /etc/kafka/docker/ports
environment:
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: broker,controller
KAFKA_LISTENERS: PLAINTEXT://:9092,CONTROLLER://:9093
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@localhost:9093
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_NUM_PARTITIONS: 3
command: "/kafka.sh"
volumes:
- './kafka.sh:/kafka.sh'为了让 Broker 向客户端通告其外部可访问地址,它需要一个额外的文件 kafka.sh,如 将端口映射暴露给正在运行的容器 中所述。
22.8. 配置参考
构建时固定的配置属性 - 所有其他配置属性都可以在运行时覆盖
配置属性 |
类型 |
默认 |
|---|---|---|
如果 Kafka 开发服务已被明确启用或禁用。开发服务通常默认启用,除非存在现有配置。对于 Kafka,开发服务会启动一个 Broker,除非设置了 环境变量: 显示更多 |
布尔值 |
|
开发服务将侦听的可选固定端口。 如果未定义,将随机选择端口。 环境变量: 显示更多 |
整数 |
|
Kafka 开发服务容器类型。 支持 Redpanda、Strimzi 和 kafka-native 容器提供程序。默认为 redpanda。 对于 Redpanda:请参阅 https://docs.redpanda.com/current/get-started/quick-start/ 和 https://hub.docker.com/r/redpandadata/redpanda 对于 Strimzi:请参阅 https://github.com/strimzi/test-container 和 https://quay.io/repository/strimzi-test-container/test-container 对于 Kafka Native:请参阅 https://github.com/ozangunalp/kafka-native 和 https://quay.io/repository/ogunalp/kafka-native 请注意,Strimzi 和 Kafka Native 镜像以 Kraft 模式启动。 环境变量: 显示更多 |
|
|
要使用的 Kafka 容器镜像。 取决于提供程序。 环境变量: 显示更多 |
字符串 |
|
指示 Quarkus 开发服务管理的 Kafka Broker 是否共享。当共享时,Quarkus 会使用基于标签的服务发现来查找正在运行的容器。如果找到匹配的容器,则会使用它,因此不会启动第二个容器。否则,开发服务会启动一个新容器。 发现使用 容器共享仅在开发模式下使用。 环境变量: 显示更多 |
布尔值 |
|
附加到已启动容器的 当您需要多个共享 Kafka 代理时,将使用此属性。 环境变量: 显示更多 |
字符串 |
|
在开发服务 Kafka Broker 中创建的主题-分区对。Broker 启动后,将创建给定主题和分区,跳过已存在的主题。例如, 主题创建不会尝试重新分区具有不同分区数的现有主题。 环境变量: 显示更多 |
Map<String,Integer> |
|
用于主题创建的管理客户端调用的超时。 默认为 2 秒。 环境变量: 显示更多 |
|
|
传递给容器的环境变量。 环境变量: 显示更多 |
Map<String,String> |
|
启用事务支持。同时也启用生产者幂等性。在 https://vectorized.io/blog/fast-transactions/ 上查找有关 Redpanda 事务支持的更多信息。请注意,KIP-447(生产者可扩展性以实现精确一次语义) 和 KIP-360(提高幂等/事务性生产者的可靠性)*不支持*。 环境变量: 显示更多 |
布尔值 |
|
用于访问 Redpanda HTTP 代理 (pandaproxy) 的端口。 如果未定义,将随机选择端口。 环境变量: 显示更多 |
整数 |
|
关于 Duration 格式
要写入持续时间值,请使用标准的 您还可以使用简化的格式,以数字开头
在其他情况下,简化格式将被转换为
|
23. Kafka 开发 UI
如果存在任何 Kafka 相关扩展(例如 quarkus-messaging-kafka),Quarkus 开发 UI 将会扩展一个 Kafka Broker 管理 UI。它会自动连接到为应用程序配置的 Kafka Broker。
使用 **Kafka 开发 UI**,您可以直接管理您的 Kafka 集群并执行任务,例如:
-
列出和创建主题
-
可视化记录
-
发布新记录
-
检查消费者组列表及其消费滞后情况
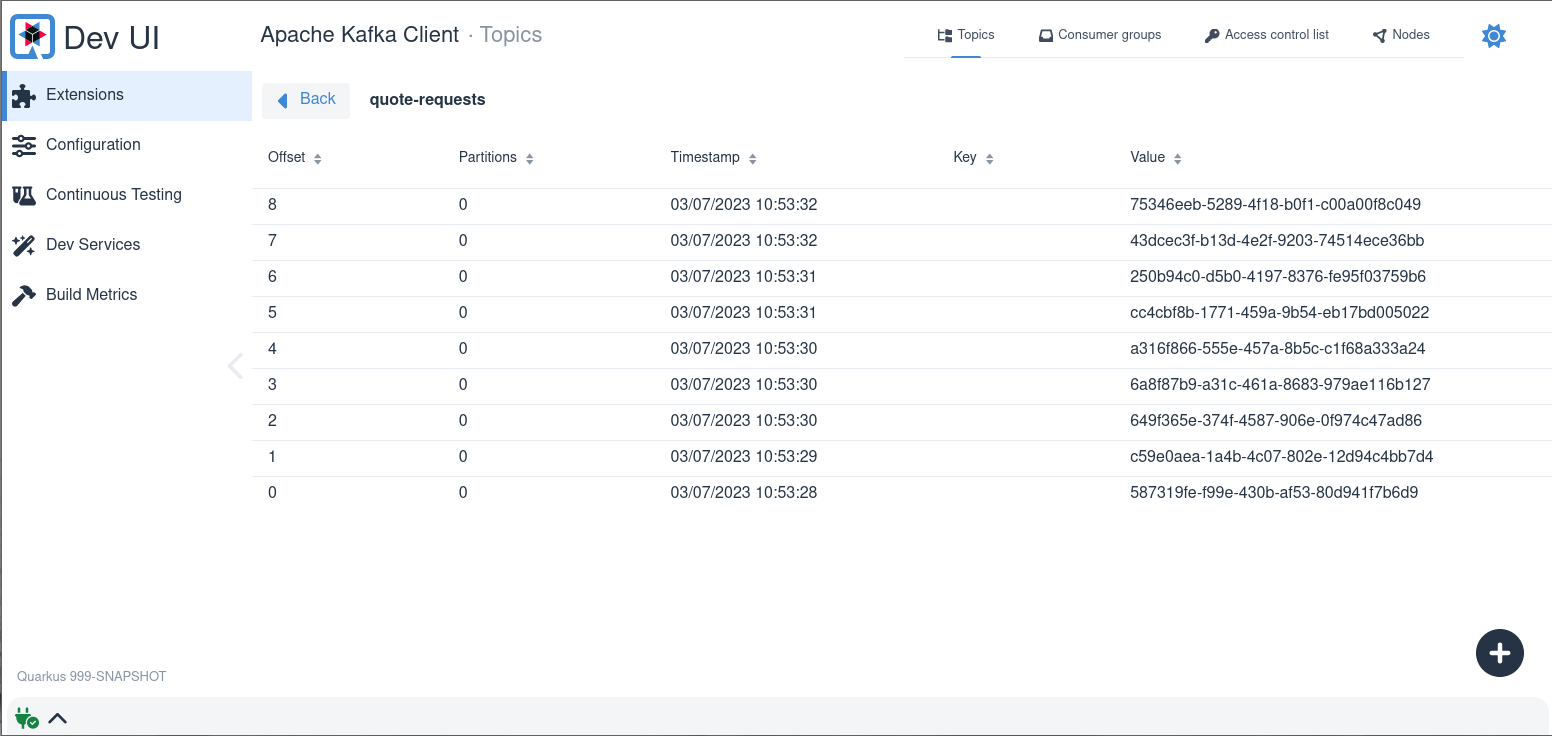
| Kafka 开发 UI 是 Quarkus 开发 UI 的一部分,仅在开发模式下可用。 |
24. Kubernetes 服务绑定
Quarkus Kafka 扩展支持 Kubernetes 服务绑定规范。您可以通过将 quarkus-kubernetes-service-binding 扩展添加到您的应用程序来启用此功能。
在适当配置的 Kubernetes 集群中运行时,Kafka 扩展将从集群内的可用服务绑定中拉取其 Kafka Broker 连接配置,而无需用户进行配置。
25. 执行模型
Reactive Messaging 在 I/O 线程上调用用户的方法。因此,默认情况下,方法不能阻塞。如 阻塞处理 中所述,如果该方法会阻塞调用线程,您需要为该方法添加 @Blocking 注释。
有关此主题的更多详细信息,请参阅 Quarkus Reactive Architecture 文档。
26. 通道装饰器
SmallRye Reactive Messaging 支持装饰入站和出站通道,用于实现跨领域关注点,如监控、跟踪或消息拦截。有关实现装饰器和消息拦截器的更多信息,请参阅 SmallRye Reactive Messaging 文档。
27. 配置参考
有关 SmallRye Reactive Messaging 配置的更多详细信息,请参阅 SmallRye Reactive Messaging - Kafka 连接器文档。
|
每个通道都可以通过配置禁用,使用: |
最重要的属性列在下表中:
27.1. 入站通道配置(轮询 Kafka)
以下属性使用以下方式配置:
mp.messaging.incoming.your-channel-name.attribute=value某些属性具有可以全局配置的别名。
kafka.bootstrap.servers=...您还可以传递底层 Kafka 消费者 支持的任何属性。
例如,要配置 max.poll.records 属性,请使用:
mp.messaging.incoming.[channel].max.poll.records=1000一些消费者客户端属性已配置为合理的默认值:
如果未设置,reconnect.backoff.max.ms 设置为 10000 以避免断开连接时的高负载。
如果未设置,key.deserializer 设置为 org.apache.kafka.common.serialization.StringDeserializer。
消费者 client.id 根据要创建的客户端数量使用 mp.messaging.incoming.[channel].partitions 属性进行配置。
-
如果提供了
client.id,则按原样使用,或者根据partitions属性添加客户端索引后缀。 -
如果未提供
client.id,则生成为[client-id-prefix][channel-name][-index]。
| 属性 (别名) | 描述 | 强制 | 默认 |
|---|---|---|---|
bootstrap.servers (kafka.bootstrap.servers) |
用于建立与 Kafka 集群的初始连接的主机:端口的逗号分隔列表。 类型:字符串 |
false |
|
topic |
消耗/填充的 Kafka 主题。如果未设置此属性或 类型:字符串 |
false |
|
health-enabled |
是否启用(默认)或禁用健康报告。 类型:布尔值 |
false |
|
health-readiness-enabled |
是否启用(默认)或禁用就绪健康报告。 类型:布尔值 |
false |
|
health-readiness-topic-verification |
*已弃用* - 就绪检查是否应验证主题是否存在于 Broker 中。默认为 false。启用它需要管理连接。已弃用:请改用 'health-topic-verification-enabled'。 类型:布尔值 |
false |
|
health-readiness-timeout |
*已弃用* - 在就绪健康检查期间,连接器连接到 Broker 并检索主题列表。此属性指定检索的最大持续时间(以毫秒为单位)。如果超过该时间,则通道被视为未就绪。已弃用:请改用 'health-topic-verification-timeout'。 类型:长整型 |
false |
|
health-topic-verification-enabled |
启动和就绪检查是否应验证主题是否存在于 Broker 中。默认为 false。启用它需要管理客户端连接。 类型:布尔值 |
false |
|
health-topic-verification-timeout |
在启动和就绪健康检查期间,连接器连接到 Broker 并检索主题列表。此属性指定检索的最大持续时间(以毫秒为单位)。如果超过该时间,则通道被视为未就绪。 类型:长整型 |
false |
|
已启用跟踪 |
是否启用(默认)或禁用跟踪 类型:布尔值 |
false |
|
client-id-prefix |
Kafka 客户端 类型:字符串 |
false |
|
checkpoint.state-store |
在使用 类型:字符串 |
false |
|
checkpoint.state-type |
在使用 类型:字符串 |
false |
|
checkpoint.unsynced-state-max-age.ms |
在使用 类型:整数 |
false |
|
cloud-events |
启用(默认)或禁用 Cloud Event 支持。如果在*入站*通道上启用,连接器会分析入站记录并尝试创建 Cloud Event 元数据。如果在*出站*通道上启用,如果消息包含 Cloud Event 元数据,连接器会将出站消息作为 Cloud Event 发送。 类型:布尔值 |
false |
|
kafka-configuration |
为该通道提供默认 Kafka 消费者/生产者配置的 CDI Bean 的标识符。通道配置仍然可以覆盖任何属性。Bean 的类型必须是 Map<String, Object>,并且必须使用 @io.smallrye.common.annotation.Identifier 限定符来设置标识符。 类型:字符串 |
false |
|
topics |
要消耗的主题的逗号分隔列表。不能与 类型:字符串 |
false |
|
pattern |
指示 类型:布尔值 |
false |
|
key.deserializer |
用于反序列化记录键的反序列化器类名。 类型:字符串 |
false |
|
lazy-client |
Kafka 客户端是延迟创建还是立即创建。 类型:布尔值 |
false |
|
value.deserializer |
用于反序列化记录值的反序列化器类名。 类型:字符串 |
true |
|
fetch.min.bytes |
服务器应为 fetch 请求返回的最小数据量。默认设置 1 字节意味着 fetch 请求在收到一个字节数据或 fetch 请求等待数据到达超时后即可得到响应。 类型:整数 |
false |
|
group.id |
一个唯一字符串,用于标识应用程序所属的消费者组。 如果未设置,则默认为由 如果该属性也未设置,则使用一个唯一生成的 ID。 建议始终定义 类型:字符串 |
false |
|
enable.auto.commit |
如果启用,则基础 Kafka 客户端会在后台定期提交消费者的 offset,而忽略记录的实际处理结果。建议*不要*启用此设置,让 Reactive Messaging 处理提交。 类型:布尔值 |
false |
|
retry |
是否在发生故障时重新尝试连接到 Broker。 类型:布尔值 |
false |
|
retry-attempts |
重新连接前的最大次数。-1 表示无限重试。 类型:整数 |
false |
|
retry-max-wait |
两次重连之间的最大延迟(以秒为单位)。 类型:整数 |
false |
|
广播 |
Kafka 记录是否应分发给多个消费者。 类型:布尔值 |
false |
|
auto.offset.reset |
在 Kafka 中没有初始 offset 时该做什么。可接受的值是 earliest、latest 和 none。 类型:字符串 |
false |
|
失败策略 |
指定当从记录生成的已生成消息被否定确认(nack)时要应用的失败策略。值可以是 类型:字符串 |
false |
|
commit-strategy |
指定当从记录生成的已生成消息被确认时要应用的提交策略。值可以是 类型:字符串 |
false |
|
throttled.unprocessed-record-max-age.ms |
在使用 类型:整数 |
false |
|
dead-letter-queue.topic |
当 类型:字符串 |
false |
|
dead-letter-queue.key.serializer |
当 类型:字符串 |
false |
|
dead-letter-queue.value.serializer |
当 类型:字符串 |
false |
|
partitions |
并发消费的分区数。连接器创建指定数量的 Kafka 消费者。它应该与目标主题的分区数匹配。 类型:整数 |
false |
|
requests |
当 类型:整数 |
false |
|
consumer-rebalance-listener.name |
在实现 类型:字符串 |
false |
|
key-deserialization-failure-handler |
在实现 类型:字符串 |
false |
|
value-deserialization-failure-handler |
在实现 类型:字符串 |
false |
|
fail-on-deserialization-failure |
如果没有设置反序列化失败处理程序,并且发生反序列化失败,则报告失败并将应用程序标记为不健康。如果设置为 类型:布尔值 |
false |
|
graceful-shutdown |
应用程序终止时是否应尝试优雅关机。 类型:布尔值 |
false |
|
poll-timeout |
轮询超时时间(以毫秒为单位)。轮询记录时,轮询最多等待该持续时间后才会返回记录。默认为 1000ms。 类型:整数 |
false |
|
pause-if-no-requests |
当应用程序不请求项目时是否应暂停轮询,并在请求时恢复。这允许实现基于应用程序容量的反压。请注意,轮询不会停止,但在暂停时不会检索任何记录。 类型:布尔值 |
false |
|
batch |
Kafka 记录是否以批处理方式消费。通道注入点必须消耗兼容的类型,例如 类型:布尔值 |
false |
|
max-queue-size-factor |
用于确定排队处理的记录的最大数量的乘数因子,使用 类型:整数 |
false |
|
27.2. 出站通道配置(写入 Kafka)
以下属性使用以下方式配置:
mp.messaging.outgoing.your-channel-name.attribute=value某些属性具有可以全局配置的别名。
kafka.bootstrap.servers=...您还可以传递底层 Kafka 生产者 支持的任何属性。
例如,要配置 max.block.ms 属性,请使用:
mp.messaging.incoming.[channel].max.block.ms=10000一些生产者客户端属性已配置为合理的默认值:
如果未设置,reconnect.backoff.max.ms 设置为 10000 以避免断开连接时的高负载。
如果未设置,key.serializer 设置为 org.apache.kafka.common.serialization.StringSerializer。
如果未设置,生产者 client.id 将生成为 [client-id-prefix][channel-name]。
| 属性 (别名) | 描述 | 强制 | 默认 |
|---|---|---|---|
acks |
生产者要求 leader 接收之前才能将请求视为完成的确认数。这控制着发送记录的持久性。可接受的值是:0、1、all。 类型:字符串 |
false |
|
bootstrap.servers (kafka.bootstrap.servers) |
用于建立与 Kafka 集群的初始连接的主机:端口的逗号分隔列表。 类型:字符串 |
false |
|
client-id-prefix |
Kafka 客户端 类型:字符串 |
false |
|
buffer.memory |
生产者可用于缓冲等待发送到服务器的记录的总字节数。 类型:长整型 |
false |
|
close-timeout |
等待 Kafka 生产者优雅关闭的毫秒数。 类型:整数 |
false |
|
cloud-events |
启用(默认)或禁用 Cloud Event 支持。如果在*入站*通道上启用,连接器会分析入站记录并尝试创建 Cloud Event 元数据。如果在*出站*通道上启用,如果消息包含 Cloud Event 元数据,连接器会将出站消息作为 Cloud Event 发送。 类型:布尔值 |
false |
|
cloud-events-data-content-type (cloud-events-default-data-content-type) |
配置出站 Cloud Event 的默认 类型:字符串 |
false |
|
cloud-events-data-schema (cloud-events-default-data-schema) |
配置出站 Cloud Event 的默认 类型:字符串 |
false |
|
cloud-events-insert-timestamp (cloud-events-default-timestamp) |
连接器是否应自动插入出站 Cloud Event 的 类型:布尔值 |
false |
|
cloud-events-mode |
Cloud Event 模式( 类型:字符串 |
false |
|
cloud-events-source (cloud-events-default-source) |
配置出站 Cloud Event 的默认 类型:字符串 |
false |
|
cloud-events-subject (cloud-events-default-subject) |
配置出站 Cloud Event 的默认 类型:字符串 |
false |
|
cloud-events-type (cloud-events-default-type) |
配置出站 Cloud Event 的默认 类型:字符串 |
false |
|
health-enabled |
是否启用(默认)或禁用健康报告。 类型:布尔值 |
false |
|
health-readiness-enabled |
是否启用(默认)或禁用就绪健康报告。 类型:布尔值 |
false |
|
health-readiness-timeout |
*已弃用* - 在就绪健康检查期间,连接器连接到 Broker 并检索主题列表。此属性指定检索的最大持续时间(以毫秒为单位)。如果超过该时间,则通道被视为未就绪。已弃用:请改用 'health-topic-verification-timeout'。 类型:长整型 |
false |
|
health-readiness-topic-verification |
*已弃用* - 就绪检查是否应验证主题是否存在于 Broker 中。默认为 false。启用它需要管理连接。已弃用:请改用 'health-topic-verification-enabled'。 类型:布尔值 |
false |
|
health-topic-verification-enabled |
启动和就绪检查是否应验证主题是否存在于 Broker 中。默认为 false。启用它需要管理客户端连接。 类型:布尔值 |
false |
|
health-topic-verification-timeout |
在启动和就绪健康检查期间,连接器连接到 Broker 并检索主题列表。此属性指定检索的最大持续时间(以毫秒为单位)。如果超过该时间,则通道被视为未就绪。 类型:长整型 |
false |
|
kafka-configuration |
为该通道提供默认 Kafka 消费者/生产者配置的 CDI Bean 的标识符。通道配置仍然可以覆盖任何属性。Bean 的类型必须是 Map<String, Object>,并且必须使用 @io.smallrye.common.annotation.Identifier 限定符来设置标识符。 类型:字符串 |
false |
|
key |
写入记录时使用的键。 类型:字符串 |
false |
|
key-serialization-failure-handler |
在实现 类型:字符串 |
false |
|
key.serializer |
用于序列化记录键的序列化器类名。 类型:字符串 |
false |
|
lazy-client |
Kafka 客户端是延迟创建还是立即创建。 类型:布尔值 |
false |
|
max-inflight-messages |
要并发写入 Kafka 的最大消息数。它限制了等待写入并由 Broker 确认的消息数量。您可以将此属性设置为 类型:长整型 |
false |
|
merge |
连接器是否允许多个上游。 类型:布尔值 |
false |
|
partition |
目标分区 ID。-1 表示让客户端确定分区。 类型:整数 |
false |
|
propagate-headers |
要传播到出站记录的入站记录头的逗号分隔列表。 类型:字符串 |
false |
|
propagate-record-key |
将入站记录的键传播到出站记录。 类型:布尔值 |
false |
|
retries |
如果设置为正数,连接器将尝试重新发送任何未成功传递的消息(可能出现瞬时错误),直到达到重试次数。如果设置为 0,则禁用重试。如果未设置,连接器将尝试在 类型:长整型 |
false |
|
topic |
消耗/填充的 Kafka 主题。如果未设置此属性或 类型:字符串 |
false |
|
已启用跟踪 |
是否启用(默认)或禁用跟踪 类型:布尔值 |
false |
|
value-serialization-failure-handler |
在实现 类型:字符串 |
false |
|
value.serializer |
用于序列化有效载荷的序列化器类名。 类型:字符串 |
true |
|
waitForWriteCompletion |
在确认消息之前,客户端是否等待 Kafka 确认写入的记录。 类型:布尔值 |
false |
|
27.3. Kafka 配置解析
Quarkus 将所有 Kafka 相关的应用程序属性(以 kafka. 或 KAFKA_ 开头的属性)暴露在一个名为 default-kafka-broker 的配置映射中。此配置用于建立与 Kafka Broker 的连接。
除了此默认配置外,您还可以通过 kafka-configuration 属性配置生产者 Map 的名称:
mp.messaging.incoming.my-channel.connector=smallrye-kafka
mp.messaging.incoming.my-channel.kafka-configuration=my-configuration在这种情况下,连接器会查找与 my-configuration 名称关联的 Map。如果未设置 kafka-configuration,则会查找以通道名称(上例中为 my-channel)公开的 Map。
@Produces
@ApplicationScoped
@Identifier("my-configuration")
Map<String, Object> outgoing() {
return Map.ofEntries(
Map.entry("value.serializer", ObjectMapperSerializer.class.getName())
);
}如果设置了 kafka-configuration 但找不到 Map,则部署将失败。 |
属性值解析如下:
-
该属性直接在通道配置中设置(
mp.messaging.incoming.my-channel.attribute=value), -
如果未设置,连接器会查找具有通道名称或已配置的
kafka-configuration(如果已设置)的Map,并从中检索值。 -
如果解析的
Map不包含该值,则使用默认的Map(以default-kafka-broker名称公开)。
27.4. 条件性配置通道
您可以使用特定的配置文件来配置通道。因此,只有在启用了指定配置文件时,通道才会被配置(并添加到应用程序中)。
要实现这一点,您需要:
-
在
mp.messaging.[incoming|outgoing].$channel条目前加上%my-profile前缀,例如%my-profile.mp.messaging.[incoming|outgoing].$channel.key=value。 -
在包含
@Incoming(channel)和@Outgoing(channel)注释的 CDI Bean 上使用@IfBuildProfile("my-profile"),这些 Bean 仅在启用了配置文件时才需要启用。
请注意,Reactive Messaging 会验证图的完整性。因此,在使用这种条件性配置时,请确保应用程序在启用和不启用配置文件时都能正常工作。
请注意,此方法也可用于根据配置文件更改通道配置。
28. 集成 Kafka - 常见模式
28.1. 从 HTTP 端点写入 Kafka
要从 HTTP 端点发送消息到 Kafka,请在您的端点中注入一个 Emitter(或 MutinyEmitter)。
package org.acme;
import java.util.concurrent.CompletionStage;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import org.eclipse.microprofile.reactive.messaging.Channel;
import org.eclipse.microprofile.reactive.messaging.Emitter;
@Path("/")
public class ResourceSendingToKafka {
@Channel("kafka") Emitter<String> emitter; (1)
@POST
@Produces(MediaType.TEXT_PLAIN)
public CompletionStage<Void> send(String payload) { (2)
return emitter.send(payload); (3)
}
}| 1 | 注入一个 Emitter<String>。 |
| 2 | HTTP 方法接收有效载荷并返回一个 CompletionStage,在消息写入 Kafka 时完成。 |
| 3 | 将消息发送到 Kafka,send 方法返回一个 CompletionStage。 |
该端点将传入的有效载荷(来自 POST HTTP 请求)发送到发射器。发射器的通道在 application.properties 文件中映射到 Kafka 主题。
mp.messaging.outgoing.kafka.connector=smallrye-kafka
mp.messaging.outgoing.kafka.topic=my-topic该端点返回一个 CompletionStage,表示方法的异步性质。emitter.send 方法返回一个 CompletionStage<Void>。当消息写入 Kafka 后,返回的 Future 会完成。如果写入失败,返回的 CompletionStage 会以异常形式完成。
如果端点不返回 CompletionStage,HTTP 响应可能会在消息发送到 Kafka 之前写入,因此失败不会报告给用户。
如果您需要发送 Kafka 记录,请使用:
package org.acme;
import java.util.concurrent.CompletionStage;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import org.eclipse.microprofile.reactive.messaging.Channel;
import org.eclipse.microprofile.reactive.messaging.Emitter;
import io.smallrye.reactive.messaging.kafka.Record;
@Path("/")
public class ResourceSendingToKafka {
@Channel("kafka") Emitter<Record<String,String>> emitter; (1)
@POST
@Produces(MediaType.TEXT_PLAIN)
public CompletionStage<Void> send(String payload) {
return emitter.send(Record.of("my-key", payload)); (2)
}
}| 1 | 注意 Emitter<Record<K, V>> 的使用。 |
| 2 | 使用 Record.of(k, v) 创建记录。 |
28.2. 使用 Hibernate with Panache 持久化 Kafka 消息
要将从 Kafka 接收的对象持久化到数据库,您可以使用 Hibernate with Panache。
| 如果您使用 Hibernate Reactive,请参阅 使用 Hibernate Reactive 持久化 Kafka 消息。 |
假设您接收 Fruit 对象。为简单起见,我们的 Fruit 类非常简单:
package org.acme;
import jakarta.persistence.Entity;
import io.quarkus.hibernate.orm.panache.PanacheEntity;
@Entity
public class Fruit extends PanacheEntity {
public String name;
}要消费存储在 Kafka 主题上的 Fruit 实例并将它们持久化到数据库,您可以使用以下方法:
package org.acme;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.transaction.Transactional;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import io.smallrye.common.annotation.Blocking;
@ApplicationScoped
public class FruitConsumer {
@Incoming("fruits") (1)
@Transactional (2)
public void persistFruits(Fruit fruit) { (3)
fruit.persist(); (4)
}
}| 1 | 配置入站通道。此通道从 Kafka 读取。 |
| 2 | 由于我们正在写入数据库,因此我们必须在事务中进行。此注释会启动一个新事务并在方法返回时提交它。Quarkus 会自动将方法视为*阻塞*。确实,使用经典 Hibernate 写入数据库是阻塞的。因此,Quarkus 会在您可以阻塞的工作线程(而不是 I/O 线程)上调用该方法。 |
| 3 | 该方法接收每个 Fruit。请注意,您需要一个反序列化器来从 Kafka 记录中重建 Fruit 实例。 |
| 4 | 持久化接收到的 fruit 对象。 |
如 <4> 中所述,您需要一个反序列化器,它可以根据记录创建 Fruit。这可以通过 Jackson 反序列化器来完成:
package org.acme;
import io.quarkus.kafka.client.serialization.ObjectMapperDeserializer;
public class FruitDeserializer extends ObjectMapperDeserializer<Fruit> {
public FruitDeserializer() {
super(Fruit.class);
}
}相关的配置将是:
mp.messaging.incoming.fruits.connector=smallrye-kafka
mp.messaging.incoming.fruits.value.deserializer=org.acme.FruitDeserializer有关 Jackson 与 Kafka 用法的更多详细信息,请查看 通过 Jackson 进行序列化。您也可以使用 Avro。
28.3. 使用 Hibernate Reactive 持久化 Kafka 消息
要将从 Kafka 接收的对象持久化到数据库,您可以使用 Hibernate Reactive with Panache。
假设您接收 Fruit 对象。为简单起见,我们的 Fruit 类非常简单:
package org.acme;
import jakarta.persistence.Entity;
import io.quarkus.hibernate.reactive.panache.PanacheEntity; (1)
@Entity
public class Fruit extends PanacheEntity {
public String name;
}| 1 | 确保使用响应式变体: |
要消费存储在 Kafka 主题上的 Fruit 实例并将它们持久化到数据库,您可以使用以下方法:
package org.acme;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.enterprise.context.control.ActivateRequestContext;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import io.quarkus.hibernate.reactive.panache.Panache;
import io.smallrye.mutiny.Uni;
@ApplicationScoped
public class FruitStore {
@Inject
Mutiny.Session session; (1)
@Incoming("in")
@ActivateRequestContext (2)
public Uni<Void> consume(Fruit entity) {
return session.withTransaction(t -> { (3)
return entity.persistAndFlush() (4)
.replaceWithVoid(); (5)
}).onTermination().call(() -> session.close()); (6)
}
}| 1 | 注入 Hibernate Reactive Session。 |
| 2 | Hibernate Reactive Session 和 Panache API 需要一个活动的 CDI 请求上下文。@ActivateRequestContext 注释会创建一个新的请求上下文,并在返回的方法的 Uni 完成时销毁它。如果未使用 Panache,则可以注入 Mutiny.SessionFactory 并以类似方式使用,而无需激活请求上下文或手动关闭会话。 |
| 3 | 请求一个新事务。事务在传递的操作完成时完成。 |
| 4 | 持久化实体。它返回一个 Uni<Fruit>。 |
| 5 | 切换回 Uni<Void>。 |
| 6 | 关闭会话 - 这会关闭与数据库的连接。然后可以回收该连接。 |
与*经典* Hibernate 不同,您不能使用 @Transactional。相反,我们使用 session.withTransaction 并持久化我们的实体。map 用于返回 Uni<Void> 而不是 Uni<Fruit>。
您需要一个反序列化器,它可以根据记录创建 Fruit。这可以通过 Jackson 反序列化器来完成:
package org.acme;
import io.quarkus.kafka.client.serialization.ObjectMapperDeserializer;
public class FruitDeserializer extends ObjectMapperDeserializer<Fruit> {
public FruitDeserializer() {
super(Fruit.class);
}
}相关的配置将是:
mp.messaging.incoming.fruits.connector=smallrye-kafka
mp.messaging.incoming.fruits.value.deserializer=org.acme.FruitDeserializer有关 Jackson 与 Kafka 用法的更多详细信息,请查看 通过 Jackson 进行序列化。您也可以使用 Avro。
28.4. 将由 Hibernate 管理的实体写入 Kafka
假设有以下过程:
-
您接收到带有有效载荷的 HTTP 请求,
-
您从该有效载荷创建一个 Hibernate 实体实例,
-
您将该实体持久化到数据库,
-
您将实体发送到 Kafka 主题。
| 如果您使用 Hibernate Reactive,请参阅 将由 Hibernate Reactive 管理的实体写入 Kafka。 |
由于我们要写入数据库,因此我们必须在事务中运行此方法。但是,将实体发送到 Kafka 是异步发生的。我们可以通过在 MutinyEmitter 上使用 .sendAndAwait() 或 .sendAndForget(),或者在 Emitter 上使用 .send().toCompletableFuture().join() 来实现此目的。
要实现此过程,您需要以下方法:
package org.acme;
import java.util.concurrent.CompletionStage;
import jakarta.transaction.Transactional;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import org.eclipse.microprofile.reactive.messaging.Channel;
import io.smallrye.reactive.messaging.MutinyEmitter;
@Path("/")
public class ResourceSendingToKafka {
@Channel("kafka") MutinyEmitter<Fruit> emitter;
@POST
@Path("/fruits")
@Transactional (1)
public void storeAndSendToKafka(Fruit fruit) { (2)
fruit.persist();
emitter.sendAndAwait(new FruitDto(fruit)); (3)
}
}| 1 | 由于我们正在写入数据库,请确保我们在事务中运行: |
| 2 | 该方法接收要持久化的 fruit 实例。 |
| 3 | 将托管实体包装在 Data Transfer Object 中并将其发送到 Kafka。这确保了托管实体不会受到 Kafka 序列化的影响。然后等待操作完成再返回。 |
在使用 @Transactional 时不应返回 CompletionStage 或 Uni,因为所有事务提交都将在单个线程上发生,这会影响性能。 |
28.5. 将由 Hibernate Reactive 管理的实体写入 Kafka
要将由 Hibernate Reactive 管理的实体发送到 Kafka,我们建议使用:
-
Quarkus REST 用于提供 HTTP 请求,
-
MutinyEmitter用于将消息发送到通道,因此可以轻松地与 Hibernate Reactive 或 Hibernate Reactive with Panache 暴露的 Mutiny API 集成。
以下示例演示了如何接收有效载荷,使用 Hibernate Reactive with Panache 将其存储在数据库中,然后将持久化的实体发送到 Kafka:
package org.acme;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import org.eclipse.microprofile.reactive.messaging.Channel;
import io.quarkus.hibernate.reactive.panache.Panache;
import io.smallrye.mutiny.Uni;
import io.smallrye.reactive.messaging.MutinyEmitter;
@Path("/")
public class ReactiveGreetingResource {
@Channel("kafka") MutinyEmitter<Fruit> emitter; (1)
@POST
@Path("/fruits")
public Uni<Void> sendToKafka(Fruit fruit) { (2)
return Panache.withTransaction(() -> (3)
fruit.<Fruit>persist()
)
.chain(f -> emitter.send(f)); (4)
}
}| 1 | 注入一个 MutinyEmitter,它暴露了一个 Mutiny API。它简化了与 Hibernate Reactive with Panache 暴露的 Mutiny API 的集成。 |
| 2 | 接收有效载荷的 HTTP 方法返回一个 Uni<Void>。在操作完成时(实体已持久化并写入 Kafka)会写入 HTTP 响应。 |
| 3 | 我们需要在事务中将实体写入数据库。 |
| 4 | 一旦持久化操作完成,我们将实体发送到 Kafka。send 方法返回一个 Uni<Void>。 |
28.6. 将 Kafka 主题作为 Server-Sent Events 流式传输
将 Kafka 主题作为 Server-Sent Events (SSE) 流式传输非常简单:
-
您在 HTTP 端点中注入代表 Kafka 主题的通道。
-
您将该通道作为
Publisher或Multi从 HTTP 方法返回。
以下代码提供了一个示例:
@Channel("fruits")
Multi<Fruit> fruits;
@GET
@Produces(MediaType.SERVER_SENT_EVENTS)
public Multi<Fruit> stream() {
return fruits;
}某些环境会在活动不足时断开 SSE 连接。解决方法是定期发送*ping*消息(或空对象)。
@Channel("fruits")
Multi<Fruit> fruits;
@Inject
ObjectMapper mapper;
@GET
@Produces(MediaType.SERVER_SENT_EVENTS)
public Multi<String> stream() {
return Multi.createBy().merging()
.streams(
fruits.map(this::toJson),
emitAPeriodicPing()
);
}
Multi<String> emitAPeriodicPing() {
return Multi.createFrom().ticks().every(Duration.ofSeconds(10))
.onItem().transform(x -> "{}");
}
private String toJson(Fruit f) {
try {
return mapper.writeValueAsString(f);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}解决方法稍微复杂一些,因为除了发送来自 Kafka 的 fruit 之外,还需要定期发送 ping。为实现此目的,我们将来自 Kafka 的流与每 10 秒发出 {} 的周期性流合并。
28.7. 将 Kafka 事务与 Hibernate Reactive 事务链接
通过将 Kafka 事务与 Hibernate Reactive 事务链接,您可以将记录发送到 Kafka 事务,执行数据库更新,并且仅当数据库事务成功时才提交 Kafka 事务。
以下示例演示了:
-
通过 Quarkus REST 使用 HTTP 请求接收有效载荷,
-
使用 SmallRye Fault Tolerance 限制该 HTTP 端点的并发性,
-
启动 Kafka 事务并将有效载荷发送到 Kafka 记录,
-
使用 Hibernate Reactive with Panache 将有效载荷存储在数据库中,
-
仅当实体成功持久化时才提交 Kafka 事务。
package org.acme;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.core.MediaType;
import org.eclipse.microprofile.faulttolerance.Bulkhead;
import org.eclipse.microprofile.reactive.messaging.Channel;
import org.hibernate.reactive.mutiny.Mutiny;
import io.quarkus.hibernate.reactive.panache.Panache;
import io.smallrye.mutiny.Uni;
import io.smallrye.reactive.messaging.kafka.transactions.KafkaTransactions;
@Path("/")
public class FruitProducer {
@Channel("kafka") KafkaTransactions<Fruit> kafkaTx; (1)
@POST
@Path("/fruits")
@Consumes(MediaType.APPLICATION_JSON)
@Bulkhead(1) (2)
public Uni<Void> post(Fruit fruit) { (3)
return kafkaTx.withTransaction(emitter -> { (4)
emitter.send(fruit); (5)
return Panache.withTransaction(() -> { (6)
return fruit.<Fruit>persist(); (7)
});
}).replaceWithVoid();
}
}| 1 | 注入 KafkaTransactions,它公开了一个 Mutiny API。它允许与 Hibernate Reactive with Panache 暴露的 Mutiny API 集成。 |
| 2 | 将 HTTP 端点的并发限制为 "1",防止同时启动多个事务。 |
| 3 | 接收有效载荷的 HTTP 方法返回一个 Uni<Void>。在操作完成时(实体已持久化且 Kafka 事务已提交)会写入 HTTP 响应。 |
| 4 | 开始一个 Kafka 事务。 |
| 5 | 在 Kafka 事务中将有效载荷发送到 Kafka。 |
| 6 | 在 Hibernate Reactive 事务中将实体持久化到数据库。 |
| 7 | 一旦持久化操作完成且没有错误,Kafka 事务将被提交。结果将被省略并作为 HTTP 响应返回。 |
在上面的示例中,数据库事务(内部)将提交,然后是 Kafka 事务(外部)。如果您希望先提交 Kafka 事务,然后再提交数据库事务,您需要以相反的顺序嵌套它们。
下一个示例演示了这一点,使用了 Hibernate Reactive API(无 Panache):
import jakarta.inject.Inject;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.core.MediaType;
import org.eclipse.microprofile.faulttolerance.Bulkhead;
import org.eclipse.microprofile.reactive.messaging.Channel;
import org.hibernate.reactive.mutiny.Mutiny;
import io.smallrye.mutiny.Uni;
import io.smallrye.reactive.messaging.kafka.transactions.KafkaTransactions;
import io.vertx.mutiny.core.Context;
import io.vertx.mutiny.core.Vertx;
@Path("/")
public class FruitProducer {
@Channel("kafka") KafkaTransactions<Fruit> kafkaTx;
@Inject Mutiny.SessionFactory sf; (1)
@POST
@Path("/fruits")
@Consumes(MediaType.APPLICATION_JSON)
@Bulkhead(1)
public Uni<Void> post(Fruit fruit) {
return sf.withTransaction(session -> (2)
kafkaTx.withTransaction(emitter -> (3)
session.persist(fruit).invoke(() -> emitter.send(fruit)) (4)
));
}
}| 1 | 注入 Hibernate Reactive SessionFactory。 |
| 2 | 开始一个 Hibernate Reactive 事务。 |
| 3 | 开始一个 Kafka 事务。 |
| 4 | 持久化有效载荷并将实体发送到 Kafka。 |
或者,您可以使用 @WithTransaction 注释来启动一个事务并在方法返回时提交它:
import jakarta.inject.Inject;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.core.MediaType;
import org.eclipse.microprofile.faulttolerance.Bulkhead;
import org.eclipse.microprofile.reactive.messaging.Channel;
import io.quarkus.hibernate.reactive.panache.common.WithTransaction;
import io.smallrye.mutiny.Uni;
import io.smallrye.reactive.messaging.kafka.transactions.KafkaTransactions;
@Path("/")
public class FruitProducer {
@Channel("kafka") KafkaTransactions<Fruit> kafkaTx;
@POST
@Path("/fruits")
@Consumes(MediaType.APPLICATION_JSON)
@Bulkhead(1)
@WithTransaction (1)
public Uni<Void> post(Fruit fruit) {
return kafkaTx.withTransaction(emitter -> (2)
fruit.persist().invoke(() -> emitter.send(fruit)) (3)
);
}
}| 1 | 启动一个 Hibernate Reactive 事务并在方法返回时提交它。 |
| 2 | 开始一个 Kafka 事务。 |
| 3 | 持久化有效载荷并将实体发送到 Kafka。 |
28.8. 将 Kafka 事务与 Hibernate ORM 事务链接
虽然 KafkaTransactions 在 Mutiny 之上提供了响应式 API 来管理 Kafka 事务,但您仍然可以将 Kafka 事务与阻塞的 Hibernate ORM 事务链接。
import jakarta.transaction.Transactional;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import org.eclipse.microprofile.reactive.messaging.Channel;
import io.quarkus.logging.Log;
import io.smallrye.mutiny.Uni;
import io.smallrye.reactive.messaging.kafka.transactions.KafkaTransactions;
@Path("/")
public class FruitProducer {
@Channel("kafka") KafkaTransactions<Pet> emitter;
@POST
@Path("/fruits")
@Consumes(MediaType.APPLICATION_JSON)
@Bulkhead(1)
@Transactional (1)
public void post(Fruit fruit) {
emitter.withTransaction(e -> { (2)
// if id is attributed by the database, will need to flush to get it
// fruit.persistAndFlush();
fruit.persist(); (3)
Log.infov("Persisted fruit {0}", p);
e.send(p); (4)
return Uni.createFrom().voidItem();
}).await().indefinitely(); (5)
}
}| 1 | 开始一个 Hibernate ORM 事务。事务在方法返回时提交。 |
| 2 | 开始一个 Kafka 事务。 |
| 3 | 持久化有效载荷。 |
| 4 | 在 Kafka 事务中将实体发送到 Kafka。 |
| 5 | 等待返回的 Uni 以便 Kafka 事务完成。 |
29. 日志记录
为了减少 Kafka 客户端生成的日志量,Quarkus 将以下日志类别的级别设置为 WARNING:
-
org.apache.kafka.clients -
org.apache.kafka.common.utils -
org.apache.kafka.common.metrics
您可以通过在 application.properties 中添加以下行来覆盖配置:
quarkus.log.category."org.apache.kafka.clients".level=INFO
quarkus.log.category."org.apache.kafka.common.utils".level=INFO
quarkus.log.category."org.apache.kafka.common.metrics".level=INFO30. 连接到托管 Kafka 集群
本节将介绍如何连接到著名的 Kafka Cloud 服务。
30.1. Azure Event Hub
Azure Event Hub 提供了一个与 Apache Kafka 兼容的端点。
| Kafka 的 Azure Event Hubs 在*基本*层不可用。您至少需要*标准*层才能使用 Kafka。请参阅 Azure Event Hubs 定价 以查看其他选项。 |
要使用 TLS 通过 Kafka 协议连接到 Azure Event Hub,您需要以下配置:
kafka.bootstrap.servers=my-event-hub.servicebus.windows.net:9093 (1)
kafka.security.protocol=SASL_SSL
kafka.sasl.mechanism=PLAIN
kafka.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \ (2)
username="$ConnectionString" \ (3)
password="<YOUR.EVENTHUBS.CONNECTION.STRING>"; (4)| 1 | 端口是 9093。 |
| 2 | 您需要使用 JAAS PlainLoginModule。 |
| 3 | 用户名是 $ConnectionString 字符串。 |
| 4 | Azure 提供的 Event Hub 连接字符串。 |
将 <YOUR.EVENTHUBS.CONNECTION.STRING> 替换为您 Event Hubs 命名空间的连接字符串。有关获取连接字符串的说明,请参阅 获取 Event Hubs 连接字符串。结果将类似:
kafka.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \
username="$ConnectionString" \
password="Endpoint=sb://my-event-hub.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=XXXXXXXXXXXXXXXX";此配置可以是全局的(如上所示),也可以在通道配置中设置:
mp.messaging.incoming.$channel.bootstrap.servers=my-event-hub.servicebus.windows.net:9093
mp.messaging.incoming.$channel.security.protocol=SASL_SSL
mp.messaging.incoming.$channel.sasl.mechanism=PLAIN
mp.messaging.incoming.$channel.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \
username="$ConnectionString" \
password="Endpoint=sb://my-event-hub.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=...";30.2. Red Hat OpenShift Streams for Apache Kafka
Red Hat OpenShift Streams for Apache Kafka 提供托管的 Kafka Broker。首先,遵循 使用 rhoas CLI 获取 Red Hat OpenShift Streams for Apache Kafka 的入门指南 来创建您的 Kafka Broker 实例。确保您已复制了与您创建的*服务账户*关联的客户端 ID 和客户端密码。
然后,您可以如下配置 Quarkus 应用程序以连接到 Broker:
kafka.bootstrap.servers=<connection url> (1)
kafka.security.protocol=SASL_SSL
kafka.sasl.mechanism=PLAIN
kafka.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \
username="${KAFKA_USERNAME}" \ (2)
password="${KAFKA_PASSWORD}"; (3)| 1 | 连接字符串,在管理控制台上提供,例如 demo-c—bjsv-ldd-cvavkc-a.bf2.kafka.rhcloud.com:443。 |
| 2 | Kafka 用户名(来自服务账户的客户端 ID)。 |
| 3 | Kafka 密码(来自服务账户的客户端密码)。 |
通常,这些属性会使用 %prod 进行前缀,以便仅在生产模式下运行时启用它们。 |
| 如 使用 rhoas CLI 获取 Red Hat OpenShift Streams for Apache Kafka 的入门指南 所述,要使用 Red Hat OpenShift Streams for Apache Kafka,您必须提前创建主题,创建*服务账户*,并授予该服务账户读取和写入您主题的权限。身份验证数据(客户端 ID 和密码)与服务账户相关,这意味着您可以实现精细权限并限制对主题的访问。 |
在 Kubernetes 中使用时,建议将客户端 ID 和密码存储在 Kubernetes secret 中:
apiVersion: v1
kind: Secret
metadata:
name: kafka-credentials
stringData:
KAFKA_USERNAME: "..."
KAFKA_PASSWORD: "..."为了让您的 Quarkus 应用程序能够使用该 secret,请将以下行添加到 application.properties 文件中:
%prod.quarkus.openshift.env.secrets=kafka-credentials30.2.1. Red Hat OpenShift Service Registry
Red Hat OpenShift Service Registry 提供完全托管的服务注册表,用于处理 Kafka 模式。
您可以按照 Red Hat OpenShift Service Registry 入门指南 中的说明进行操作,或使用 rhoas CLI 创建新的服务注册表实例:
rhoas service-registry create --name my-schema-registry请务必记下实例的*注册表 URL*。对于身份验证,您可以使用之前创建的同一个*服务账户*。您需要确保它具有访问服务注册表的必要权限。
例如,使用 rhoas CLI,您可以为服务账户授予 MANAGER 角色:
rhoas service-registry role add --role manager --service-account [SERVICE_ACCOUNT_CLIENT_ID]然后,您可以如下配置 Quarkus 应用程序以连接到模式注册表:
mp.messaging.connector.smallrye-kafka.apicurio.registry.url=${RHOAS_SERVICE_REGISTRY_URL} (1)
mp.messaging.connector.smallrye-kafka.apicurio.auth.service.token.endpoint=${RHOAS_OAUTH_TOKEN_ENDPOINT} (2)
mp.messaging.connector.smallrye-kafka.apicurio.auth.client.id=${RHOAS_CLIENT_ID} (3)
mp.messaging.connector.smallrye-kafka.apicurio.auth.client.secret=${RHOAS_CLIENT_ID} (4)| 1 | 服务注册表 URL,在管理控制台上提供,例如 https://bu98.serviceregistry.rhcloud.com/t/0e95af2c-6e11-475e-82ee-f13bd782df24/apis/registry/v2。 |
| 2 | OAuth 令牌端点 URL,例如 https://identity.api.openshift.com/auth/realms/rhoas/protocol/openid-connect/token。 |
| 3 | 客户端 ID(来自服务账户)。 |
| 4 | 客户端密码(来自服务账户)。 |
30.2.2. 使用 Service Binding Operator 将 Red Hat OpenShift 托管服务绑定到 Quarkus 应用程序
如果您的 Quarkus 应用程序部署在已安装 Service Binding Operator 和 OpenShift Application Services Operator 的 Kubernetes 或 OpenShift 集群中,则访问 Red Hat OpenShift Streams for Apache Kafka 和 Service Registry 所需的配置可以通过 Kubernetes 服务绑定 注入到应用程序中。
为了设置服务绑定,您需要首先将 OpenShift 托管服务连接到您的集群。对于 OpenShift 集群,您可以遵循 将 Kafka 和 Service Registry 实例连接到您的 OpenShift 集群 中的说明。
一旦您将集群与 RHOAS Kafka 和 Service Registry 实例连接起来,请确保您已授予新创建的服务账户必要的权限。
然后,使用 Kubernetes 服务绑定 扩展,您可以配置 Quarkus 应用程序以生成这些服务的 ServiceBinding 资源:
quarkus.kubernetes-service-binding.detect-binding-resources=true
quarkus.kubernetes-service-binding.services.kafka.api-version=rhoas.redhat.com/v1alpha1
quarkus.kubernetes-service-binding.services.kafka.kind=KafkaConnection
quarkus.kubernetes-service-binding.services.kafka.name=my-kafka
quarkus.kubernetes-service-binding.services.serviceregistry.api-version=rhoas.redhat.com/v1alpha1
quarkus.kubernetes-service-binding.services.serviceregistry.kind=ServiceRegistryConnection
quarkus.kubernetes-service-binding.services.serviceregistry.name=my-schema-registry在此示例中,Quarkus 构建将生成以下 ServiceBinding 资源:
apiVersion: binding.operators.coreos.com/v1alpha1
kind: ServiceBinding
metadata:
name: my-app-kafka
spec:
application:
group: apps.openshift.io
name: my-app
version: v1
kind: DeploymentConfig
services:
- group: rhoas.redhat.com
version: v1alpha1
kind: KafkaConnection
name: my-kafka
detectBindingResources: true
bindAsFiles: true
---
apiVersion: binding.operators.coreos.com/v1alpha1
kind: ServiceBinding
metadata:
name: my-app-serviceregistry
spec:
application:
group: apps.openshift.io
name: my-app
version: v1
kind: DeploymentConfig
services:
- group: rhoas.redhat.com
version: v1alpha1
kind: ServiceRegistryConnection
name: my-schema-registry
detectBindingResources: true
bindAsFiles: true您可以遵循 部署到 OpenShift 来部署您的应用程序,包括生成的 ServiceBinding 资源。访问 Kafka 和 Schema Registry 实例所需的配置属性将在部署时自动注入到应用程序中。
31. 深入了解
本指南展示了如何使用 Quarkus 与 Kafka 进行交互。它利用 Quarkus Messaging 来构建数据流应用程序。
如果您想进一步了解,请查看 Quarkus 中使用的 SmallRye Reactive Messaging 的文档。
