Quarkus Native 采用自适应 GC 策略

从 Quarkus 2.13.6.Final 开始,原生运行时垃圾回收策略进行了切换,以提供更一致和可预测的运行时性能。这篇博文讲述了这次切换的故事。
2022年,在进行一些原生运行时性能基准测试时,我们发现,在恒定负载的纯文本基准测试中,内存消耗会持续增长,直到达到大约 500MB,然后才会下降。内存消耗的图表大致如下所示。
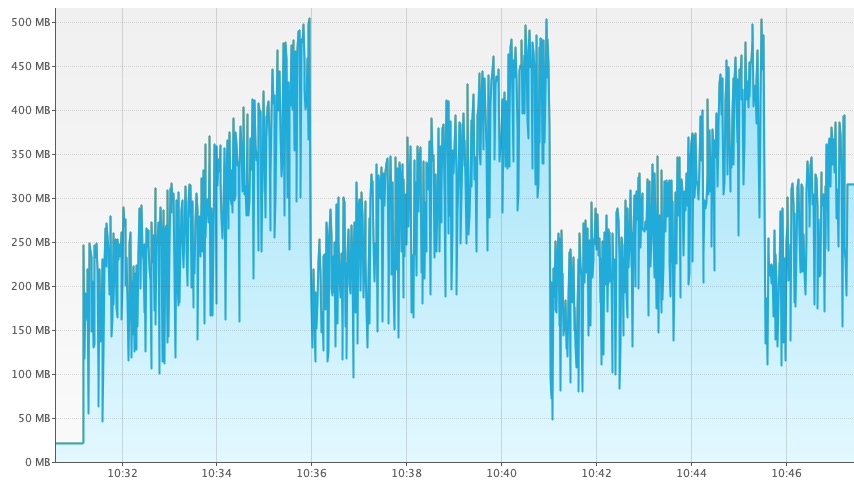
| 上图是使用 VisualVM 获取的。此功能自 22.3.0 版本起仅在 GraalVM 社区版中提供。有关更多详细信息,请参见此处。 |
这张图看起来很可疑。乍一看,小的垃圾回收在规律地发生,但这些回收无法完全清除所有的垃圾。这些未被回收的垃圾会持续增长,直到大约 500MB,此时会发生完全的垃圾回收,并清除不断增长的内存泄漏。
我们首先想知道,这个大约 500MB 的限制是什么,以及它来自哪里。为此,我们启用了 GC 日志记录,看看是否能找到一些线索。
$ quarkus-project/target/quarkus-project-1.0.0-SNAPSHOT-runner -XX:+PrintGC -XX:+VerboseGC
2023-01-09 13:29:32,155 INFO [io.quarkus] (main) quarkus-project 1.0.0-SNAPSHOT native (powered by Quarkus 2.15.2.Final) started in 0.017s. Listening on: http://0.0.0.0:8080
...
[Heap policy parameters:
YoungGenerationSize: 268435456
MaximumHeapSize: 27487790640
MinimumHeapSize: 536870912 <--
AlignedChunkSize: 1048576
LargeArrayThreshold: 131072]我们发现这个数字实际上是 512MB,这是 GraalVM 在最大堆大小超过约 3GB 物理内存时配置的默认最小堆大小。
下一个问题是,为什么最小堆大小和发生完全 GC 时的内存消耗之间存在关联?从上面的输出看,在我们的系统上,默认最大堆大小为 25.6GB。如果未传递特定的配置,GraalVM 会将最大堆大小默认为物理内存的 80%,而 25.6GB 确实是 32GB 的 80%。考虑到我们的系统分配了远大于 512MB 的最大堆大小,在只消耗了 512MB 时就进行完全 GC 似乎有些奇怪。答案在于 Quarkus 明确配置的 GC 策略。
默认情况下,GraalVM 使用名为“adaptive”的 GC 策略,但 Quarkus 却指示 GraalVM 使用另一种名为“by space and time”的 GC 策略。关于 Quarkus 使用不同 GC 策略的完整故事可以在此处找到,但总而言之,这个决定是在 2018 年做出的,当时“by space and time”似乎产生的完全 GC 更少,并提供了显著更好的吞吐量。
“by space and time”GC 策略实现了一个 shouldCollectCompletely 方法,该方法决定是进行完全(full)还是增量(minimal)回收。以下是“by space and time”GC 策略的相关代码:
return estimateUsedHeapAtNextIncrementalCollection().aboveThan(getMaximumHeapSize()) // (1)
|| GCImpl.getChunkBytes().aboveThan(getMinimumHeapSize()) && enoughTimeSpentOnIncrementalGCs(); // (2)进行完全 GC 的一个选项 (1) 是当它估计已用堆将超过最大堆大小时,但我们的情况并非如此。另一个选项 (2) 是,如果发生了足够的最小回收并且已用堆超过了最小堆大小时。后者正是这里发生的情况。
这时我们想,对于 2022 年,默认 GC 策略的假设是否仍然适用?因此,我们删除了 GC 策略配置的调整,重复了测试,并观察到了以下内存消耗:
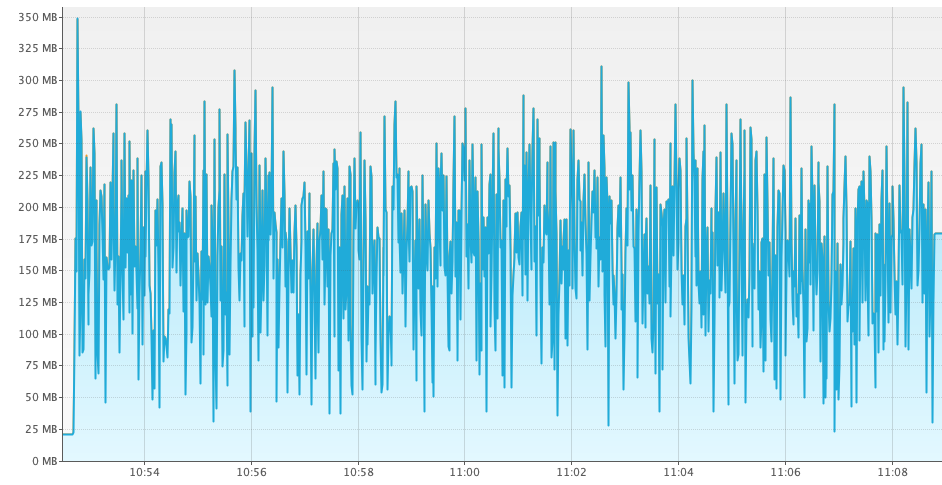
对于相同的负载,“adaptive”策略比“by space and time”策略消耗的堆内存少近 50%。但请注意,仅凭这些图表不足以做出切换决定,因为“adaptive”使用较少内存可能是因为总体吞吐量较低。因此,让我们看看生成上述图表的基准测试,看看我们能获得什么样的吞吐量数据。使用 Hyperfoil,在我们的环境中,“by space and time”策略报告了这些数字:
[hyperfoil@in-vm]$ wrk -t 128 -c 512 -H 'accept: text/plain' -d 16m http://<host>:8080/hello
PHASE METRIC THROUGHPUT REQUESTS ... TIMEOUTS ERRORS BLOCKED 2xx
test request 93.79k req/s 90036541 ... 0 0 0 ns 90036094以下是“adaptive”策略的数字:
[hyperfoil@in-vm]$ wrk -t 128 -c 512 -H 'accept: text/plain' -d 16m http://<host>:8080/hello
PHASE METRIC THROUGHPUT REQUESTS ... TIMEOUTS ERRORS BLOCKED 2xx
test request 93.05k req/s 89329151 ... 0 0 0 ns 89328711结果是使用 wrk 获得的,众所周知,wrk 在延迟数字方面存在一些问题(有关更多详细信息,请参阅这篇博文),因此在本文的上下文中我们可以忽略这些数字,而专注于吞吐量数字。 |
对于相同的负载,“adaptive”策略获得的吞吐量与“by space and time”策略获得的吞吐量相差在 1% 以内。因此,使用“adaptive”策略获得与“by space and time”几乎相同的吞吐量,同时内存消耗减少近 50%,这为切换到“adaptive”GC 策略作为 Quarkus 的默认策略提供了非常有说服力的论据,因为这已经是其他 GraalVM 的默认设置了。
| 内存消耗的优势并非在所有堆大小上都均匀适用。本博文中发布的数字适用于最大堆大小等于或大于 3GB 的情况,此时默认最小堆大小设置为约 512MB,除非另行配置。对于较小的最大堆大小,内存消耗的改进可能较小或不存在。 |
我们经常看到在没有配置 -Xmx 的情况下运行的测试或基准测试,在这种情况下,如上所述,最大堆大小被设置为可用物理内存的 80%,在现代硬件上,这个堆大小很容易超过 3GB。这些用户将通过“adaptive”GC 策略获得更好的开箱即用体验。
因此,从 Quarkus 2.13.6.Final 开始,Quarkus 原生应用程序的 GC 策略已与 GraalVM 的默认策略“adaptive”保持一致。如果您在特定情况下希望使用“by space and time”策略,仍然可以将其设置回此策略。如果您在自己的 Quarkus 应用程序中遇到了此 GC 策略更改引起的回归,进行此操作可能会很有用。要做到这一点,请传递:
-Dquarkus.native.additional-build-args=-H:InitialCollectionPolicy=com.oracle.svm.core.genscavenge.CollectionPolicy\$BySpaceAndTime如果通过命令行传递,则必须转义 $ 符号。 |
有关进行的调查的更多详细信息,请参阅原始 GitHub 问题。作为这项工作的结果,我们还增强了 Quarkus Native 参考指南,添加了原生内存管理部分。新部分应有助于 Quarkus Native 用户理解内存管理的工作原理以及如何充分利用它。
