原生参考指南
本指南是对《构建原生可执行文件》、《使用 SSL 连接原生镜像》和《编写原生应用程序》指南的补充。它探讨了有助于用户诊断问题、提高可靠性和改善原生可执行文件运行时性能的高级主题。本指南包含以下主要章节:
原生内存管理
Quarkus 原生可执行文件的内存管理由 GraalVM 的 SubstrateVM 运行时系统提供支持。
有关 GraalVM 中内存管理组件的详细说明,请参阅 GraalVM 内存管理指南。
本指南补充了 GraalVM 网站上的信息,并提供了与 Quarkus 应用程序特别相关的更多观察结果。
垃圾回收器
目前 Quarkus 用户可用的垃圾回收器是 Serial GC 和 Epsilon GC。
Serial GC
Serial GC 是 GraalVM 和 Quarkus 中的默认选项,它是一种单线程非并发 GC,类似于 HotSpot 的 Serial GC。但 GraalVM 中的实现与 HotSpot 的实现不同,运行时行为可能存在显著差异。
HotSpot 的 Serial GC 和 GraalVM 的 Serial GC 之间的主要区别之一是它们执行完整 GC 周期的方式。在 HotSpot 中,使用的算法是标记-清除-压缩,而在 GraalVM 中,它是标记-复制。两者都需要遍历所有活动对象,但在标记-复制中,此遍历还用于将活动对象复制到辅助空间或半空间。当对象从一个半空间复制到另一个半空间时,它们也会被压缩。在标记-清除-压缩中,压缩需要对活动对象进行第二次遍历。这使得标记-复制中的完整 GC 比标记-清除-压缩更节省时间(就每次 GC 周期花费的时间而言)。标记-复制为缩短单个完整 GC 周期所做的权衡是空间。半空间的使用意味着,为了使应用程序保持与标记-清除相同的 GC 性能(就每秒分配的 MB 而言),它需要两倍的内存。
GC 收集策略
GraalVM 的 Serial GC 实现提供了两种不同的收集策略供选择,“自适应”是默认策略,另一种是“空间/时间”策略。
“自适应”收集策略基于 HotSpot 的 ParallelGC 自适应大小策略。与 HotSpot 的主要区别在于 GraalVM 对内存占用的关注。这意味着 GraalVM 的自适应 GC 策略会尝试积极触发 GC 以降低内存消耗。
直到 2.13 版本,Quarkus 默认使用“空间/时间”GC 收集策略,但从 2.14 版本开始,它切换为使用“自适应”策略。Quarkus 最初选择使用“空间/时间”的原因是,当时它在性能上比“自适应”有显著的提升。然而,最近的性能测试表明,“空间/时间”策略相比“自适应”策略,在开箱即用的体验上可能更差,同时它过去提供的优势在对“自适应”策略进行改进后已大大减弱。因此,“自适应”策略似乎是绝大多数(如果不是全部)Quarkus 应用程序的最佳选择。有关此更改的完整详细信息,请参阅此 issue。
仍然可以通过 GraalVM 的 -H:InitialCollectionPolicy 标志更改 GC 收集策略。通过命令行传递以下参数可以切换到“空间/时间”策略
-Dquarkus.native.additional-build-args=-H:InitialCollectionPolicy=com.oracle.svm.core.genscavenge.CollectionPolicy\$BySpaceAndTime或者将其添加到 application.properties 文件中
quarkus.native.additional-build-args=-H:InitialCollectionPolicy=com.oracle.svm.core.genscavenge.CollectionPolicy$BySpaceAndTime|
如果要通过 Bash 命令行传递,则需要转义 |
内存管理选项
有关控制最大堆大小、年轻代空间和其他 JVM 中常见用例的选项,请参阅 GraalVM 内存管理指南。通常建议设置最大堆大小,无论是按百分比还是按固定值。
GC 日志记录
有多种选项可以打印有关垃圾回收周期的信息,具体取决于所需的详细程度。-XX:+PrintGC 提供最少的详细信息,它会为发生的每个 GC 周期打印一条消息
$ quarkus-project-0.1-SNAPSHOT-runner -XX:+PrintGC -Xmx64m
...
[Incremental GC (CollectOnAllocation) 20480K->11264K, 0.0003223 secs]
[Full GC (CollectOnAllocation) 19456K->5120K, 0.0031067 secs]将此选项与 -XX:+VerboseGC 结合使用时,仍然会为每个 GC 周期获得一条消息,但它包含额外信息。此外,添加此选项会显示 GC 算法在启动时进行的内存大小调整决策
$ quarkus-project-0.1-SNAPSHOT-runner -XX:+PrintGC -XX:+VerboseGC -Xmx64m
[Heap policy parameters:
YoungGenerationSize: 25165824
MaximumHeapSize: 67108864
MinimumHeapSize: 33554432
AlignedChunkSize: 1048576
LargeArrayThreshold: 131072]
...
[[5378479783321 GC: before epoch: 8 cause: CollectOnAllocation]
[Incremental GC (CollectOnAllocation) 16384K->9216K, 0.0003847 secs]
[5378480179046 GC: after epoch: 8 cause: CollectOnAllocation policy: adaptive type: incremental
collection time: 384755 nanoSeconds]]
[[5379294042918 GC: before epoch: 9 cause: CollectOnAllocation]
[Full GC (CollectOnAllocation) 17408K->5120K, 0.0030556 secs]
[5379297109195 GC: after epoch: 9 cause: CollectOnAllocation policy: adaptive type: complete
collection time: 3055697 nanoSeconds]]除了这两个选项之外,-XX:+PrintHeapShape 和 -XX:+TraceHeapChunks 还可以在构建内存区域的基础之上提供更底层的详细信息。
通过打印可以传递给原生可执行文件的标志列表,可以获得有关 GC 日志记录标志的最新信息
$ quarkus-project-0.1-SNAPSHOT-runner -XX:PrintFlags=
...
-XX:±PrintGC Print summary GC information after each collection. Default: - (disabled).
-XX:±PrintGCSummary Print summary GC information after application main method returns. Default: - (disabled).
-XX:±PrintGCTimeStamps Print a time stamp at each collection, if +PrintGC or +VerboseGC. Default: - (disabled).
-XX:±PrintGCTimes Print the time for each of the phases of each collection, if +VerboseGC. Default: - (disabled).
-XX:±PrintHeapShape Print the shape of the heap before and after each collection, if +VerboseGC. Default: - (disabled).
...
-XX:±TraceHeapChunks Trace heap chunks during collections, if +VerboseGC and +PrintHeapShape. Default: - (disabled).
-XX:±VerboseGC Print more information about the heap before and after each collection. Default: - (disabled).常驻内存集大小 (RSS)
正如性能度量指南中所述,Quarkus 应用程序的内存占用是通过常驻内存集大小 (RSS) 来衡量的。这同样适用于原生应用程序,但在此情况下管理内存占用的运行时引擎是内置在原生可执行文件本身中,而不是 JVM。
《性能度量指南》中指定的报告技术也适用于原生应用程序,但导致 RSS 升高或降低的原因取决于生成原生可执行文件的具体工作方式。
当一个原生应用程序版本相对于另一个版本具有更高的 RSS 时,应首先进行以下检查
通常,分析、插桩或跟踪应用程序是了解其工作原理的最佳方法。对于 RSS 和原生应用程序,Brendan Gregg 在《内存泄漏(和增长)火焰图》指南中解释的技术特别有用。本节将应用该文章中的信息,展示如何使用 perf 和 bcc/eBPF 来理解导致 Quarkus 原生可执行文件启动时消耗内存的原因。
Perf
perf 在较旧的 Linux 系统上工作,而 eBPF 需要较新的 Linux 内核。perf 的开销比 eBPF 高,但它可以理解使用 DWARF 调试符号生成的堆栈跟踪,而 eBPF 无法做到。
在 GraalVM 的上下文中,DWARF 堆栈跟踪比使用帧指针生成的堆栈跟踪包含更多细节且更易于理解。作为第一步,请使用调试信息启用并添加几个额外标志来构建 Quarkus 原生可执行文件。一个标志用于禁用优化,另一个标志用于防止内联方法从堆栈跟踪中省略。已添加这两个标志以获取尽可能多的信息的堆栈跟踪。
$ mvn package -DskipTests -Dnative \
-Dquarkus.native.debug.enabled \
-Dquarkus.native.additional-build-args=-O0,-H:-OmitInlinedMethodDebugLineInfo|
禁用优化可以更容易地学习如何使用 |
让我们在此特定环境中度量 Quarkus 原生可执行文件在启动时占用的 RSS 大约是多少
$ ps -o pid,rss,command -p $(pidof code-with-quarkus-1.0.0-SNAPSHOT-runner)
PID RSS COMMAND
1915 35472 ./target/code-with-quarkus-1.0.0-SNAPSHOT-runner -Xmx128m为什么这个 Quarkus 原生可执行文件在启动时会消耗 ~35MB RSS?为了理解这个数字,本节将使用 perf 来跟踪对 syscalls:sys_enter_mmap 的调用。假设使用默认的 GraalVM Serial Garbage Collector,此系统调用对于 GraalVM native-image 生成的原生可执行文件特别有趣,因为它分配堆的方式。在 GraalVM native-image 生成的原生可执行文件中,堆使用对齐或未对齐的堆块进行分配。所有非数组对象都在线程本地对齐块中分配。每个块默认大小为 1MB。对于数组,如果它们大于对齐块大小的 1/8,它们将在未对齐的堆块中分配,其大小取决于对象本身。线程第一次分配对象或小数组时,它会请求一个对齐的堆块,直到该块用完空间为止,它将独占使用该块,届时它将请求另一个对齐的堆块。因此,通过跟踪这些系统调用,将记录导致请求新的对齐或未对齐堆块的代码路径。接下来,通过 perf record 跟踪 mmap 系统调用来运行 Quarkus 原生可执行文件
$ sudo perf record -e syscalls:sys_enter_mmap --call-graph dwarf -a -- target/code-with-quarkus-1.0.0-SNAPSHOT-runner -Xmx128m|
对齐堆块的大小可以在原生构建时更改。可以通过 |
启动完成后,停止进程并生成堆栈
$ perf script > out.stacks最后一步是生成 火焰图,其中包含生成的堆栈
$ export FG_HOME=...
$ ${FG_HOME}/stackcollapse-perf.pl < out.stacks | ${FG_HOME}/flamegraph.pl \
--color=mem --title="mmap Flame Graph" --countname="calls" > out.svg火焰图应该看起来像这样

有几点值得注意
首先,包含对 com.oracle.svm.core.genscavenge.ThreadLocalAllocation 方法调用的堆栈跟踪与上面解释的对齐或未对齐堆块分配有关。如前所述,对于大多数分配,这些块默认大小为 1MB,因此它们很有趣,因为每个分配的块对 RSS 消耗都有相当大的影响。
其次,在线程分配堆栈中,start_thread 下的堆栈特别有启发性。在此环境中,考虑到传递的 -Xmx 值,Quarkus 创建了 12 个事件循环线程。除此之外,还有 6 个额外的线程。通过 ps 命令可以看到,所有这 18 个线程的名称都超过 16 个字符。
$ ps -e -T | grep $(pidof code-with-quarkus-1.0.0-SNAPSHOT-runner)
2320 2320 pts/0 00:00:00 code-with-quark
2320 2321 pts/0 00:00:00 ference Handler
2320 2322 pts/0 00:00:00 gnal Dispatcher
2320 2324 pts/0 00:00:00 ecutor-thread-0
2320 2325 pts/0 00:00:00 -thread-checker
2320 2326 pts/0 00:00:00 ntloop-thread-0
2320 2327 pts/0 00:00:00 ntloop-thread-1
2320 2328 pts/0 00:00:00 ntloop-thread-2
2320 2329 pts/0 00:00:00 ntloop-thread-3
2320 2330 pts/0 00:00:00 ntloop-thread-4
2320 2331 pts/0 00:00:00 ntloop-thread-5
2320 2332 pts/0 00:00:00 ntloop-thread-6
2320 2333 pts/0 00:00:00 ntloop-thread-7
2320 2334 pts/0 00:00:00 ntloop-thread-8
2320 2335 pts/0 00:00:00 ntloop-thread-9
2320 2336 pts/0 00:00:00 tloop-thread-10
2320 2337 pts/0 00:00:00 tloop-thread-11
2320 2338 pts/0 00:00:00 ceptor-thread-0所有这些线程进行的第一个分配是获取线程名称并进行修剪,以便它能落在内核强制执行的字符限制内。对于这些分配中的每一个,都有 2 个 mmap 调用,一个用于预留内存,另一个用于提交内存。在记录 syscalls:sys_enter_mmap 系统调用时,perf 实现跟踪对 GI_mmap64 的调用。但这个 glibc GI_mmap64 实现又会调用 GI_mmap64
(gdb) break __GI___mmap64
(gdb) set scheduler-locking step
...
Thread 2 "code-with-quark" hit Breakpoint 1, __GI___mmap64 (offset=0, fd=-1, flags=16418, prot=0, len=2097152, addr=0x0) at ../sysdeps/unix/sysv/linux/mmap64.c:58
58 return (void *) MMAP_CALL (mmap, addr, len, prot, flags, fd, offset);
(gdb) bt
#0 __GI___mmap64 (offset=0, fd=-1, flags=16418, prot=0, len=2097152, addr=0x0) at ../sysdeps/unix/sysv/linux/mmap64.c:58
#1 __GI___mmap64 (addr=0x0, len=2097152, prot=0, flags=16418, fd=-1, offset=0) at ../sysdeps/unix/sysv/linux/mmap64.c:46
#2 0x00000000004f4033 in com.oracle.svm.core.posix.headers.Mman$NoTransitions::mmap (__0=<optimized out>, __1=<optimized out>, __2=<optimized out>, __3=<optimized out>, __4=<optimized out>, __5=<optimized out>)
#3 0x00000000004f194e in com.oracle.svm.core.posix.PosixVirtualMemoryProvider::reserve (this=0x7ffff7691220, nbytes=0x100000, alignment=0x100000, executable=false) at com/oracle/svm/core/posix/PosixVirtualMemoryProvider.java:126
#4 0x00000000004ef3b3 in com.oracle.svm.core.os.AbstractCommittedMemoryProvider::allocate (this=0x7ffff7658cb0, size=0x100000, alignment=0x100000, executable=false) at com/oracle/svm/core/os/AbstractCommittedMemoryProvider.java:124
#5 0x0000000000482f40 in com.oracle.svm.core.os.AbstractCommittedMemoryProvider::allocateAlignedChunk (this=0x7ffff7658cb0, nbytes=0x100000, alignment=0x100000) at com/oracle/svm/core/os/AbstractCommittedMemoryProvider.java:107
#6 com.oracle.svm.core.genscavenge.HeapChunkProvider::produceAlignedChunk (this=0x7ffff7444398) at com/oracle/svm/core/genscavenge/HeapChunkProvider.java:112
#7 0x0000000000489485 in com.oracle.svm.core.genscavenge.ThreadLocalAllocation::slowPathNewArrayLikeObject0 (hub=0x7ffff6ff6110, length=15, size=0x20, podReferenceMap=0x7ffff6700000) at com/oracle/svm/core/genscavenge/ThreadLocalAllocation.java:306
#8 0x0000000000489165 in com.oracle.svm.core.genscavenge.ThreadLocalAllocation::slowPathNewArrayLikeObject (objectHeader=0x8f6110 <io.smallrye.common.expression.ExpressionNode::toString+160>, length=15, podReferenceMap=0x7ffff6700000) at com/oracle/svm/core/genscavenge/ThreadLocalAllocation.java:279
#9 0x0000000000489066 in com.oracle.svm.core.genscavenge.ThreadLocalAllocation::slowPathNewArray (objectHeader=0x8f6110 <io.smallrye.common.expression.ExpressionNode::toString+160>, length=15) at com/oracle/svm/core/genscavenge/ThreadLocalAllocation.java:242
#10 0x0000000000d202a1 in java.util.Arrays::copyOfRange (original=0x7ffff6a33410, from=2, to=17) at java/util/Arrays.java:3819
#11 0x0000000000acf8e6 in java.lang.StringLatin1::newString (val=0x7ffff6a33410, index=2, len=15) at java/lang/StringLatin1.java:769
#12 0x0000000000acac59 in java.lang.String::substring (this=0x7ffff6dc0d48, beginIndex=2, endIndex=17) at java/lang/String.java:2712
#13 0x0000000000acaba2 in java.lang.String::substring (this=0x7ffff6dc0d48, beginIndex=2) at java/lang/String.java:2680
#14 0x00000000004f96cd in com.oracle.svm.core.posix.thread.PosixPlatformThreads::setNativeName (this=0x7ffff7658d10, thread=0x7ffff723fb30, name=0x7ffff6dc0d48) at com/oracle/svm/core/posix/thread/PosixPlatformThreads.java:163
#15 0x00000000004f9285 in com.oracle.svm.core.posix.thread.PosixPlatformThreads::beforeThreadRun (this=0x7ffff7658d10, thread=0x7ffff723fb30) at com/oracle/svm/core/posix/thread/PosixPlatformThreads.java:212
#16 0x00000000005237a2 in com.oracle.svm.core.thread.PlatformThreads::threadStartRoutine (threadHandle=0x1) at com/oracle/svm/core/thread/PlatformThreads.java:760
#17 0x00000000004f9627 in com.oracle.svm.core.posix.thread.PosixPlatformThreads::pthreadStartRoutine (data=0x2a06e20) at com/oracle/svm/core/posix/thread/PosixPlatformThreads.java:203
#18 0x0000000000462ab0 in com.oracle.svm.core.code.IsolateEnterStub::PosixPlatformThreads_pthreadStartRoutine_38d96cbc1a188a6051c29be1299afe681d67942e (__0=<optimized out>) at com/oracle/svm/core/code/IsolateEnterStub.java:1
#19 0x00007ffff7e4714d in start_thread (arg=<optimized out>) at pthread_create.c:442
#20 0x00007ffff7ec8950 in clone3 () at ../sysdeps/unix/sysv/linux/x86_64/clone3.S:81|
当 Quarkus 原生可执行文件通过 |
这就是上述火焰图显示总共有 72 次调用 GI_mmap64 来处理线程名称缩写堆栈跟踪,考虑到 Quarkus 原生可执行文件运行了 18 个线程。
第三个,也是最后一个观察结果是,如果您捕获 syscalls:sys_enter_munmmap 事件,您可能会发现一些分配也导致调用 munmap。在计算要预留的大小以进行分配时,请求的大小可能会四舍五入到页面大小。为了保持对齐,对于对齐块是 1MB,对于未对齐块是 1 字节,一些预留的内存可能会被取消预留。这就是这些 munmap 调用来源。
|
仅通过查看火焰图并计算源自线程本地分配的 |
bcc/eBPF
从 Linux 内核 4.8 开始,提供支持堆栈跟踪的 bcc / eBPF 版本。它可以进行内核内摘要,使其更高效且开销更低。不幸的是,它不理解 DWARF 调试符号,因此获得的信息可能更难阅读且细节更少。
bcc/eBPF 非常可扩展,因此更容易定制脚本来跟踪特定指标。bcc 项目包含一个 stackcount 程序,可用于以与上节中 perf 类似的方式计算堆栈跟踪。但在某些情况下,拥有比系统调用次数更多的指标可能更有用。malloc 就是一个例子。malloc 调用次数不是最重要的,但分配的大小更重要。因此,与其生成显示样本计数的火焰图,不如生成显示分配字节数的火焰图。
除了 mmap,GraalVM 生成的原生可执行文件中还存在 malloc 系统调用。让我们将 bcc/eBPF 付诸实践,生成一个使用 malloc 分配的字节火焰图。
为此,首先重新生成一个 Quarkus 原生可执行文件,移除 bcc/eBPF 不理解的调试信息,而是使用带有本地符号的帧指针来获取堆栈跟踪
$ mvn package -DskipTests -Dnative \
-Dquarkus.native.additional-build-args=-H:-DeleteLocalSymbols,-H:+PreserveFramePointer我们将使用 mallocstacks.py bcc/eBPF 脚本来捕获 malloc 堆栈跟踪及其分配的大小。此脚本和其他典型的 bcc/eBPF 脚本(例如 stackcount)需要提供进程 ID (PID)。这使得在想要跟踪启动时有些棘手,但您可以使用 gdb(即使您没有启用调试信息)来解决此障碍,因为它允许您在第一个指令处停止应用程序。让我们从通过 gdb 运行原生可执行文件开始
$ gdb --args ./target/code-with-quarkus-1.0.0-SNAPSHOT-runner -Xmx128m
...
(No debugging symbols found in ./target/code-with-quarkus-1.0.0-SNAPSHOT-runner)starti 是一个 gdb 命令,它在程序执行的第一个指令处设置一个临时断点。
(gdb) starti
Starting program: <..>/code-with-quarkus/target/code-with-quarkus-1.0.0-SNAPSHOT-runner -Xmx128m
Program stopped.
0x00007ffff7fe4790 in _start () from /lib64/ld-linux-x86-64.so.2接下来,调用 bcc/eBPF 脚本,为 Quarkus 进程提供 PID,以便它可以跟踪 malloc 调用、捕获堆栈跟踪并将它们转储到文件以供后续处理
$ sudo ./mallocstacks.py -p $(pidof code-with-quarkus-1.0.0-SNAPSHOT-runner) -f > out.stacks然后回到 gdb shell 并指示它在命中第一个指令后继续启动过程
(gdb) continue
Continuing.
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib64/libthread_db.so.1".
[New Thread 0x7ffff65ff6c0 (LWP 3342)]
...
[New Thread 0x7fffc6ffd6c0 (LWP 3359)]
__ ____ __ _____ ___ __ ____ ______
--/ __ \/ / / / _ | / _ \/ //_/ / / / __/
-/ /_/ / /_/ / __ |/ , _/ ,< / /_/ /\ \
--\___\_\____/_/ |_/_/|_/_/|_|\____/___/
2023-02-09 18:02:32,794 INFO [io.quarkus] (main) code-with-quarkus 1.0.0-SNAPSHOT native (powered by Quarkus 2.16.1.Final) started in 0.011s. Listening on: http://0.0.0.0:8080
2023-02-09 18:02:32,794 INFO [io.quarkus] (main) Profile prod activated.
2023-02-09 18:02:32,794 INFO [io.quarkus] (main) Installed features: [cdi, rest, smallrye-context-propagation, vertx]启动完成后,在 stackcount shell 中按 Ctrl-C。
然后将堆栈文件作为火焰图进行处理。请注意,此脚本生成的堆栈已折叠,因此火焰图可以这样生成
$ cat out.stacks | ${FG_HOME}/flamegraph.pl --color=mem --title="malloc bytes Flame Graph" --countname="bytes" > out.svg生成的火焰图应看起来像这样

这表明通过 malloc 请求的内存大部分来自 Java NIO 中的 epoll,但通过 malloc 分配的总量仅为 268KB。此 274,269 字节的数量可以通过将鼠标悬停在火焰图底部的 all 上来观察(您可能需要要求浏览器在不同的标签页或窗口中打开火焰图才能观察到)。与 mmap 为堆分配的数量相比,这非常少。
最后,简要提及其他 bcc/eBPF 命令以及如何将它们转换为火焰图。
$ sudo /usr/share/bcc/tools/stackcount -P -p $(pidof code-with-quarkus-1.0.0-SNAPSHOT-runner) \
-U "t:syscalls:sys_enter_m*" # count stacks for mmap and munmap
$ sudo /usr/share/bcc/tools/stackcount -P -p $(pidof code-with-quarkus-1.0.0-SNAPSHOT-runner) \
-U "c:*alloc" # count stacks for malloc, calloc and realloc
$ sudo /usr/share/bcc/tools/stackcount -P -p $(pidof code-with-quarkus-1.0.0-SNAPSHOT-runner) \
-U "c:free" # count stacks for free
$ sudo /usr/share/bcc/tools/stackcount -P -p $(pidof code-with-quarkus-1.0.0-SNAPSHOT-runner) \
-U "t:exceptions:page_fault_*" # count stacks for page faultsstackcount 生成的堆栈在转换为火焰图之前需要折叠。例如
${FG_HOME}/stackcollapse.pl < out.stacks | ${FG_HOME}/flamegraph.pl \
--color=mem --title="mmap munmap Flame Graph" --countname="calls" > out.svg原生镜像跟踪代理集成
想要将新库/组件集成到原生镜像过程中的 Quarkus 用户(例如 smbj),或者想要使用需要 extensive 原生镜像配置才能工作的 JDK API(例如图形用户界面),在生成使他们用例工作的原生镜像配置方面面临严峻挑战。这些用户可以调整他们的应用程序以在 JVM 模式下使用原生镜像代理运行,以自动生成原生镜像配置,这将帮助他们快速入门,使应用程序能够作为原生可执行文件运行。
原生镜像跟踪代理是一个 JVM 工具接口 (JVMTI) 代理,在 GraalVM 和 Mandrel 中均可用,它在应用程序的常规 JVM 执行期间跟踪动态功能的所有用法,例如反射、JNI、动态代理、访问类路径资源等。当 JVM 停止时,它会将运行期间使用的动态功能的信息转储到一组原生镜像配置文件中,这些文件可用于后续的原生镜像构建。
使用代理和应用生成的配置对 Quarkus 用户来说可能很困难。首先,代理可能很麻烦,因为它需要修改 JVM 参数,并且生成的配置需要放置在特定位置,以便后续的原生镜像构建能够获取它们。其次,生成的原生镜像配置包含许多多余的配置,而 Quarkus 集成会处理这些配置。
原生镜像跟踪代理集成已包含在 Quarkus 中,以便更轻松地使用该代理。在本节中,您将了解该集成以及如何将其应用于您的 Quarkus 应用程序。
|
目前该集成仅适用于 Maven 应用程序。Gradle 集成将随后推出。 |
使用跟踪代理进行集成测试
Quarkus 用户现在可以透明地在 Quarkus Maven 应用程序上以 JVM 模式运行集成测试,并使用原生镜像跟踪代理。为此,请确保可用容器运行时,因为 JVM 模式集成测试将使用默认 Mandrel 构建器容器镜像中的 JVM 运行。此镜像包含生成原生镜像配置所需的代理库,从而无需本地安装 Mandrel 或 GraalVM。
|
强烈建议将集成测试中使用的 Mandrel 版本与构建原生可执行文件时使用的 Mandrel 版本保持一致。使用默认 Mandrel 构建器镜像进行容器内原生构建是保持两个版本一致的最安全方法。 |
此外,请确保 native-image-agent 目标存在于 quarkus-maven-plugin 配置中
<plugin>
<groupId>${quarkus.platform.group-id}</groupId>
<artifactId>quarkus-maven-plugin</artifactId>
...
<executions>
<execution>
<goals>
...
<goal>native-image-agent</goal>
</goals>
</execution>
</executions>
</plugin>在容器运行时正在运行时,调用 Maven 的 verify 目标并使用 -DskipITs=false -Dquarkus.test.integration-test-profile=test-with-native-agent 来运行 JVM 模式集成测试并生成原生镜像配置。例如
$ ./mvnw verify -DskipITs=false -Dquarkus.test.integration-test-profile=test-with-native-agent
...
[INFO] --- failsafe:3.5.2:integration-test (default) @ new-project ---
...
[INFO] -------------------------------------------------------
[INFO] T E S T S
[INFO] -------------------------------------------------------
[INFO] Running org.acme.GreetingResourceIT
2024-05-14 16:29:53,941 INFO [io.qua.tes.com.DefaultDockerContainerLauncher] (main) Executing "podman run --name quarkus-integration-test-PodgW -i --rm --user 501:20 -p 8081:8081 -p 8444:8444 --entrypoint java -v /tmp/new-project/target:/project --env QUARKUS_LOG_CATEGORY__IO_QUARKUS__LEVEL=INFO --env QUARKUS_HTTP_PORT=8081 --env QUARKUS_HTTP_SSL_PORT=8444 --env TEST_URL=https://:8081 --env QUARKUS_PROFILE=test-with-native-agent --env QUARKUS_TEST_INTEGRATION_TEST_PROFILE=test-with-native-agent quay.io/quarkus/ubi9-quarkus-mandrel-builder-image:jdk-21 -agentlib:native-image-agent=access-filter-file=quarkus-access-filter.json,caller-filter-file=quarkus-caller-filter.json,config-output-dir=native-image-agent-base-config, -jar quarkus-app/quarkus-run.jar"
...
[INFO]
[INFO] --- quarkus:3.24.4:native-image-agent (default) @ new-project ---
[INFO] Discovered native image agent generated files in /tmp/new-project/target/native-image-agent-final-config
[INFO]
...Maven 调用完成后,您可以检查 target/native-image-agent-final-config 文件夹中生成的配置
$ cat ./target/native-image-agent-final-config/reflect-config.json
[
...
{
"name":"org.acme.Alice",
"methods":[{"name":"<init>","parameterTypes":[] }, {"name":"sayMyName","parameterTypes":[] }]
},
{
"name":"org.acme.Bob"
},
...
]默认包含信息
默认情况下,生成的原生镜像配置文件不会被后续的原生镜像构建过程使用。此预防措施是为了避免出现似乎无关的操作对生成的原生可执行文件产生意外后果的情况,例如禁用随机失败的测试。
Quarkus 用户可以自由地将文件从构建中报告的文件夹中复制出来,将其存储在源代码控制下并根据需要进行演进。理想情况下,这些文件应存储在 src/main/resources/META-INF/native-image/<group-id>/<artifact-id> 文件夹下,在这种情况下,原生镜像过程将自动获取它们。
|
如果手动管理原生镜像代理配置文件,强烈建议每次 Mandrel 版本更新时重新生成它们,因为内部 Mandrel 更改可能会导致使应用程序正常工作的配置发生变化。 |
可以通过设置 -Dquarkus.native.agent-configuration-apply 属性来指示 Quarkus 将生成的原生镜像配置文件可选地应用于后续的原生镜像过程。这有助于验证原生集成测试是否按预期工作,假设 JVM 单元测试已生成正确的原生镜像配置。典型的流程是先使用原生镜像代理运行集成测试,如上一节所示
$ ./mvnw verify -DskipITs=false -Dquarkus.test.integration-test-profile=test-with-native-agent
...
[INFO] --- quarkus:3.24.4:native-image-agent (default) @ new-project ---
[INFO] Discovered native image agent generated files in /tmp/new-project/target/native-image-agent-final-config然后请求进行原生构建,并传递配置应用标志。原生构建过程中的消息将指示正在应用原生镜像代理生成的配置文件
$ ./mvnw verify -Dnative -Dquarkus.native.agent-configuration-apply
...
[INFO] --- quarkus:3.24.4:build (default) @ new-project ---
[INFO] [io.quarkus.deployment.pkg.steps.JarResultBuildStep] Building native image source jar: /tmp/new-project/target/new-project-1.0.0-SNAPSHOT-native-image-source-jar/new-project-1.0.0-SNAPSHOT-runner.jar
[INFO] [io.quarkus.deployment.steps.ApplyNativeImageAgentConfigStep] Applying native image agent generated files to current native executable build调试跟踪代理集成
如果生成的原生镜像代理配置不令人满意,可以通过以下任一技术获取更多信息
调试过滤器
Quarkus 生成原生镜像跟踪代理配置过滤器。这些过滤器会排除 Quarkus 已应用必要配置的常用包。
如果原生镜像代理生成的配置不起作用,您应该检查配置文件是否包含预期信息。例如,如果某个方法在运行时通过反射被访问,并且您收到错误,您希望验证配置文件是否包含该方法的反射条目。
如果条目缺失,可能是某个调用路径被过滤掉了,而实际上不应该被过滤。要验证这一点,请检查 target/quarkus-caller-filter.json 和 target/quarkus-access-filter.json 文件的内容,并确认进行调用或被访问的类和/或包没有被过滤掉。
如果缺失的条目与某个资源有关,您应该检查 Quarkus 构建的调试输出,并验证哪些资源模式被丢弃了,例如
$ ./mvnw -X verify -DskipITs=false -Dquarkus.test.integration-test-profile=test-with-native-agent
...
[INFO] --- quarkus:3.24.4:native-image-agent (default) @ new-project ---
...
[DEBUG] Discarding resources from native image configuration that match the following regular expression: .*(application.properties|jakarta|jboss|logging.properties|microprofile|quarkus|slf4j|smallrye|vertx).*
[DEBUG] Discarded included resource with pattern: \\QMETA-INF/microprofile-config.properties\\E
[DEBUG] Discarded included resource with pattern: \\QMETA-INF/services/io.quarkus.arc.ComponentsProvider\\E
...跟踪代理日志记录
原生镜像跟踪代理可以将导致生成配置的方法调用记录到一个 JSON 文件中。这有助于理解为什么会生成配置条目。要启用此日志记录,需要添加 -Dquarkus.test.native.agent.output.property.name=trace-output 和 -Dquarkus.test.native.agent.output.property.value=native-image-agent-trace-file.json 系统属性。例如
$ ./mvnw verify -DskipITs=false \
-Dquarkus.test.integration-test-profile=test-with-native-agent \
-Dquarkus.test.native.agent.output.property.name=trace-output \
-Dquarkus.test.native.agent.output.property.value=native-image-agent-trace-file.json配置跟踪输出时,不会生成原生镜像配置,而是生成一个 target/native-image-agent-trace-file.json 文件,其中包含跟踪信息。例如
[
{"tracer":"meta", "event":"initialization", "version":"1"},
{"tracer":"meta", "event":"phase_change", "phase":"start"},
{"tracer":"jni", "function":"FindClass", "caller_class":"java.io.ObjectStreamClass", "result":true, "args":["java/lang/NoSuchMethodError"]},
...
{"tracer":"reflect", "function":"findConstructorHandle", "class":"io.vertx.core.impl.VertxImpl$1$1$$Lambda/0x000000f80125f4e8", "caller_class":"java.lang.invoke.InnerClassLambdaMetafactory", "result":true, "args":[["io.vertx.core.Handler"]]},
{"tracer":"meta", "event":"phase_change", "phase":"dead"},
{"tracer":"meta", "event":"phase_change", "phase":"unload"}
]不幸的是,跟踪输出没有考虑应用的配置过滤器,因此输出包含了代理所做的所有配置决策。这在短期内不太可能改变(请参阅 oracle/graal#7635)。
带来源头信息的配置(实验性)
作为跟踪输出的替代方案,可以通过一个实验性标志来配置原生镜像代理,该标志显示配置条目的来源。您可以通过以下附加系统属性来启用它
$ ./mvnw verify -DskipITs=false \
-Dquarkus.test.integration-test-profile=test-with-native-agent \
-Dquarkus.test.native.agent.additional.args=experimental-configuration-with-origins配置条目的来源可以在 target/native-image-agent-base-config 文件夹内的文本文件中找到。例如
$ cat target/native-image-agent-base-config/reflect-origins.txt
root
├── java.lang.Thread#run()
│ └── java.lang.Thread#runWith(java.lang.Object,java.lang.Runnable)
│ └── io.netty.util.concurrent.FastThreadLocalRunnable#run()
│ └── org.jboss.threads.ThreadLocalResettingRunnable#run()
│ └── org.jboss.threads.DelegatingRunnable#run()
│ └── org.jboss.threads.EnhancedQueueExecutor$ThreadBody#run()
│ └── org.jboss.threads.EnhancedQueueExecutor$Task#run()
│ └── org.jboss.threads.EnhancedQueueExecutor$Task#doRunWith(java.lang.Runnable,java.lang.Object)
│ └── io.quarkus.vertx.core.runtime.VertxCoreRecorder$14#runWith(java.lang.Runnable,java.lang.Object)
│ └── org.jboss.resteasy.reactive.common.core.AbstractResteasyReactiveContext#run()
│ └── io.quarkus.resteasy.reactive.server.runtime.QuarkusResteasyReactiveRequestContext#invokeHandler(int)
│ └── org.jboss.resteasy.reactive.server.handlers.InvocationHandler#handle(org.jboss.resteasy.reactive.server.core.ResteasyReactiveRequestContext)
│ └── org.acme.GreetingResource$quarkusrestinvoker$greeting_709ef95cd764548a2bbac83843a7f4cdd8077016#invoke(java.lang.Object,java.lang.Object[])
│ └── org.acme.GreetingResource#greeting(java.lang.String)
│ └── org.acme.GreetingService_ClientProxy#greeting(java.lang.String)
│ └── org.acme.GreetingService#greeting(java.lang.String)
│ ├── java.lang.Class#forName(java.lang.String) - [ { "name":"org.acme.Alice" }, { "name":"org.acme.Bob" } ]
│ ├── java.lang.Class#getDeclaredConstructor(java.lang.Class[]) - [ { "name":"org.acme.Alice", "methods":[{"name":"<init>","parameterTypes":[] }] } ]
│ ├── java.lang.reflect.Constructor#newInstance(java.lang.Object[]) - [ { "name":"org.acme.Alice", "methods":[{"name":"<init>","parameterTypes":[] }] } ]
│ ├── java.lang.reflect.Method#invoke(java.lang.Object,java.lang.Object[]) - [ { "name":"org.acme.Alice", "methods":[{"name":"sayMyName","parameterTypes":[] }] } ]
│ └── java.lang.Class#getMethod(java.lang.String,java.lang.Class[]) - [ { "name":"org.acme.Alice", "methods":[{"name":"sayMyName","parameterTypes":[] }] } ]
...使用 GDB 进行调试
原生镜像代理本身是使用 GraalVM 制作的原生可执行文件,它使用 JVMTI 来拦截需要原生镜像配置的调用。作为最后的手段,可以使用 GDB 调试原生镜像代理,请参阅此处的说明。
检查和调试原生可执行文件
本调试指南提供了有关 Quarkus 原生可执行文件中可能在开发或生产过程中出现的问题的更多详细信息。
它以《入门指南》中开发的应用程序为输入。您可以在本指南中找到有关如何快速设置此应用程序的说明。
要求和假设
本调试指南有以下要求
-
已安装 JDK 17,并已正确配置
JAVA_HOME -
Apache Maven 3.9.9
-
可用的容器运行时(Docker、podman)
本指南在 Linux 环境中构建和执行 Quarkus 原生可执行文件。为了在所有环境中提供同质化的体验,本指南依赖容器运行时环境来构建和运行原生可执行文件。下面的说明以 Docker 为例,但非常类似的命令应该适用于其他容器运行时,例如 podman。
|
构建原生可执行文件是一个昂贵的过程,因此请确保容器运行时具有足够的 CPU 和内存来完成此操作。最少需要 4 个 CPU 和 4GB 内存。 |
最后,本指南假定使用 GraalVM 的Mandrel 发行版来构建原生可执行文件,并且这些文件在容器内构建,因此无需在主机上安装 Mandrel。
引导项目
首先创建一个新的 Quarkus 项目。打开终端并运行以下命令
适用于 Linux 和 MacOS 用户
对于 Windows 用户
-
如果使用 cmd,(不要使用反斜杠
\并将所有内容放在同一行上) -
如果使用 Powershell,请将
-D参数用双引号括起来,例如"-DprojectArtifactId=debugging-native"
对于 Windows 用户
-
如果使用 cmd,(不要使用反斜杠
\,并将所有内容放在同一行上) -
如果使用 Powershell,请将
-D参数用双引号括起来,例如"-DprojectArtifactId=debugging-native"
配置 Quarkus 属性
本调试指南中将始终使用一些 Quarkus 配置选项,因此为了帮助减少命令行调用的混乱,建议将这些选项添加到 application.properties 文件中。因此,请继续并将以下选项添加到该文件中
quarkus.native.container-build=true
quarkus.native.builder-image=quay.io/quarkus/ubi9-quarkus-mandrel-builder-image:jdk-21
quarkus.container-image.build=true
quarkus.container-image.group=test初步调试步骤
首先,切换到项目目录并为应用程序构建原生可执行文件
./mvnw package -DskipTests -Dnative运行应用程序以验证其按预期工作。在一个终端中
docker run -i --rm -p 8080:8080 test/debugging-native:1.0.0-SNAPSHOT在另一个终端中
curl -w '\n' https://:8080/hello本节的其余部分将探讨构建带有额外信息的原生可执行文件的方法,但首先,请停止正在运行的应用程序。我们可以通过添加额外的 native-image 构建选项(例如 -Dquarkus.native.additional-build-args)来在构建原生可执行文件时获取这些信息,例如
./mvnw package -DskipTests -Dnative \
-Dquarkus.native.additional-build-args=--native-image-info执行此操作将产生如下额外的输出行
...
# Printing compilation-target information to: /project/reports/target_info_20220223_100915.txt
…
# Printing native-library information to: /project/reports/native_library_info_20220223_100925.txt|
请注意, |
目标信息文件包含目标平台、编译可执行文件的工具链以及使用的 C 库等信息
$ cat target/*/reports/target_info_*.txt
Building image for target platform: org.graalvm.nativeimage.Platform$LINUX_AMD64
Using native toolchain:
Name: GNU project C and C++ compiler (gcc)
Vendor: redhat
Version: 8.5.0
Target architecture: x86_64
Path: /usr/bin/gcc
Using CLibrary: com.oracle.svm.core.posix.linux.libc.GLib原生库信息文件包含添加到二进制文件中的静态库以及动态链接到可执行文件的其他库的信息
$ cat target/*/reports/native_library_info_*.txt
Static libraries:
../opt/mandrel/lib/svm/clibraries/linux-amd64/liblibchelper.a
../opt/mandrel/lib/static/linux-amd64/glibc/libnet.a
../opt/mandrel/lib/static/linux-amd64/glibc/libextnet.a
../opt/mandrel/lib/static/linux-amd64/glibc/libnio.a
../opt/mandrel/lib/static/linux-amd64/glibc/libjava.a
../opt/mandrel/lib/static/linux-amd64/glibc/libfdlibm.a
../opt/mandrel/lib/static/linux-amd64/glibc/libsunec.a
../opt/mandrel/lib/static/linux-amd64/glibc/libzip.a
../opt/mandrel/lib/svm/clibraries/linux-amd64/libjvm.a
Other libraries: stdc++,pthread,dl,z,rt通过传递 --verbose 作为额外的 native-image 构建参数,可以获得更多细节。此选项在检测您通过 Quarkus 在高级别传递的选项是否被传递到原生可执行文件生产,或者第三方 jar 是否包含某些原生镜像配置并触及了 native-image 调用时非常有用
./mvnw package -DskipTests -Dnative \
-Dquarkus.native.additional-build-args=--verbose使用 --verbose 运行将演示 native-image 构建过程是两个顺序的 Java 进程
-
第一个是一个非常短的 Java 进程,它执行一些基本验证并构建第二个进程的参数(在标准的 GraalVM 发行版中,这是作为原生代码执行的)。
-
第二个 Java 进程是原生可执行文件生产的主要部分。
--verbose选项显示实际执行的 Java 进程。您可以获取输出并自行运行。
也可以通过用逗号分隔来组合多个原生构建选项,例如
./mvnw package -DskipTests -Dnative \
-Dquarkus.native.additional-build-args=--native-image-info,--verbose|
请记住,如果 |
检查原生可执行文件
给定一个原生可执行文件,可以使用各种 Linux 工具来检查它。为了支持各种环境,检查将从 Linux 容器内部进行。让我们创建一个包含本指南所需所有工具的 Linux 容器镜像
FROM fedora:35
RUN dnf install -y \
binutils \
gdb \
git \
perf \
perl-open
ENV FG_HOME /opt/FlameGraph
RUN git clone https://github.com/brendangregg/FlameGraph $FG_HOME
WORKDIR /data
ENTRYPOINT /bin/bash在使用非 Linux 环境中的 docker 时,您可以使用此 Dockerfile 通过以下方式创建镜像
docker build -t fedora-tools:v1 .然后,转到项目根目录并像这样运行我们刚刚创建的 Docker 容器
docker run -t -i --rm -v ${PWD}:/data -p 8080:8080 fedora-tools:v1ldd 显示可执行文件的共享库依赖项
ldd ./target/debugging-native-1.0.0-SNAPSHOT-runnerstrings 可用于查找二进制文件中的文本消息
strings ./target/debugging-native-1.0.0-SNAPSHOT-runner | grep Hello使用 strings 还可以获取给定二进制文件的 Mandrel 信息
strings ./target/debugging-native-1.0.0-SNAPSHOT-runner | grep core.VM最后,使用 readelf 我们可以检查二进制文件的不同节。例如,我们可以看到堆和文本节如何占据了二进制文件的大部分
readelf -SW ./target/debugging-native-1.0.0-SNAPSHOT-runner|
Quarkus 生成的用于运行原生可执行文件的运行时容器不包含上述工具。要探索运行时容器中的原生可执行文件,最好先运行容器本身,然后将可执行文件通过 从那里,您可以直接检查可执行文件,或使用上面的工具容器。 |
原生报告
可以选择,原生构建过程可以生成显示二进制文件内容的报告
./mvnw package -DskipTests -Dnative \
-Dquarkus.native.enable-reports报告将在 target/debugging-native-1.0.0-SNAPSHOT-native-image-source-jar/reports/ 下创建。这些报告是遇到缺少方法/类的问题,或遇到 Mandrel 拒绝的方法时非常有用的资源。
调用树报告
call_tree csv 文件报告是当传递 -Dquarkus.native.enable-reports 选项时生成的一些默认报告。这些 csv 文件可以导入到图数据库中,例如 Neo4j,以便更轻松地检查它们并对调用树运行查询。这对于估算某个方法/类为何包含在二进制文件中很有用。
让我们实际看看。
首先,启动一个 Neo4j 实例
export NEO_PASS=...
docker run \
--detach \
--rm \
--name testneo4j \
-p7474:7474 -p7687:7687 \
--env NEO4J_AUTH=neo4j/${NEO_PASS} \
neo4j:latest容器运行后,您可以访问 Neo4j 浏览器。使用 neo4j 作为用户名,并使用 NEO_PASS 的值作为密码登录。
要导入 CSV 文件,我们需要以下 cypher 脚本,它将导入 CSV 文件中的数据并创建图数据库节点和边
CREATE CONSTRAINT unique_vm_id FOR (v:VM) REQUIRE v.vmId IS UNIQUE;
CREATE CONSTRAINT unique_method_id FOR (m:Method) REQUIRE m.methodId IS UNIQUE;
LOAD CSV WITH HEADERS FROM 'file:///reports/call_tree_vm.csv' AS row
MERGE (v:VM {vmId: row.Id, name: row.Name})
RETURN count(v);
LOAD CSV WITH HEADERS FROM 'file:///reports/call_tree_methods.csv' AS row
MERGE (m:Method {methodId: row.Id, name: row.Name, type: row.Type, parameters: row.Parameters, return: row.Return, display: row.Display})
RETURN count(m);
LOAD CSV WITH HEADERS FROM 'file:///reports/call_tree_virtual_methods.csv' AS row
MERGE (m:Method {methodId: row.Id, name: row.Name, type: row.Type, parameters: row.Parameters, return: row.Return, display: row.Display})
RETURN count(m);
LOAD CSV WITH HEADERS FROM 'file:///reports/call_tree_entry_points.csv' AS row
MATCH (m:Method {methodId: row.Id})
MATCH (v:VM {vmId: '0'})
MERGE (v)-[:ENTRY]->(m)
RETURN count(*);
LOAD CSV WITH HEADERS FROM 'file:///reports/call_tree_direct_edges.csv' AS row
MATCH (m1:Method {methodId: row.StartId})
MATCH (m2:Method {methodId: row.EndId})
MERGE (m1)-[:DIRECT {bci: row.BytecodeIndexes}]->(m2)
RETURN count(*);
LOAD CSV WITH HEADERS FROM 'file:///reports/call_tree_override_by_edges.csv' AS row
MATCH (m1:Method {methodId: row.StartId})
MATCH (m2:Method {methodId: row.EndId})
MERGE (m1)-[:OVERRIDEN_BY]->(m2)
RETURN count(*);
LOAD CSV WITH HEADERS FROM 'file:///reports/call_tree_virtual_edges.csv' AS row
MATCH (m1:Method {methodId: row.StartId})
MATCH (m2:Method {methodId: row.EndId})
MERGE (m1)-[:VIRTUAL {bci: row.BytecodeIndexes}]->(m2)
RETURN count(*);将脚本的内容复制并粘贴到一个名为 import.cypher 的文件中。
|
Mandrel 22.0.0 包含一个错误,其中生成报告时符号链接的设置不正确(有关更多详细信息,请参阅此处)。可以通过将以下脚本复制到文件中并执行它来解决此问题 |
接下来,将导入 cypher 脚本和 CSV 文件复制到 Neo4j 的导入文件夹
docker cp \
target/*-native-image-source-jar/reports \
testneo4j:/var/lib/neo4j/import
docker cp import.cypher testneo4j:/var/lib/neo4j复制所有文件后,调用导入脚本
docker exec testneo4j bin/cypher-shell -u neo4j -p ${NEO_PASS} -f import.cypher导入完成后(不应超过几分钟),转到 Neo4j 浏览器,您将能够观察到图中的数据摘要
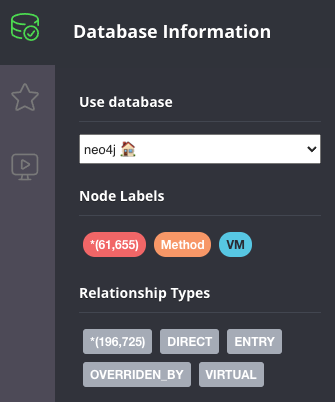
上面的数据显示大约有 60000 个方法,以及超过 200000 个方法之间的边。这里演示的 Quarkus 应用程序非常基础,所以我们能探索的不多,但这里有一些示例查询,您可以运行它们来更详细地探索图。通常,您会从查找给定方法开始
match (m:Method) where m.name = "hello" return *从那里,您可以缩小到特定类型上的特定方法
match (m:Method) where m.name = "hello" and m.type =~ ".*GreetingResource" return *一旦您找到了所需特定方法的节点,您通常想回答的问题是:为什么这个方法会被包含在调用树中?要做到这一点,从该方法开始,并在给定深度下查找传入连接,从结束方法开始。例如,直接调用某个方法的调用者可以通过以下方式找到
match (m:Method) <- [*1..1] - (o) where m.name = "hello" and m.type =~ ".*GreetingResource" return *然后您可以查找深度为 2 的直接调用,因此您将搜索调用目标方法的那些方法
match (m:Method) <- [*1..2] - (o) where m.name = "hello" and m.type =~ ".*GreetingResource" return *您可以继续向上逐层,但不幸的是,如果您达到一个具有太多节点的深度,Neo4j 浏览器将无法全部可视化它们。当发生这种情况时,您可以选择直接在 cypher shell 中运行查询
docker exec testneo4j bin/cypher-shell -u neo4j -p ${NEO_PASS} \
"match (m:Method) <- [*1..10] - (o) where m.name = 'hello' and m.type =~ '.*GreetingResource' return *"有关更多信息,请查看这篇博客文章,该文章使用上述技术探索了 Quarkus Hibernate ORM quickstart。
构建时与运行时初始化
Quarkus 指示 Mandrel 在构建时初始化尽可能多的代码,以便运行时启动尽可能快。这在容器化环境中很重要,因为启动速度对应用程序准备好执行工作有多快有很大影响。构建时初始化还最小化了运行时故障的风险,因为不受支持的功能可以通过运行时初始化变得可达,从而使 Quarkus 更可靠。
构建时初始化的最常见示例是静态变量和块。尽管 Mandrel 默认在运行时执行它们,但 Quarkus 指示 Mandrel 在构建时执行它们,原因如上所述。
这意味着任何内联初始化的静态变量,或在静态块中初始化的静态变量,即使应用程序重新启动,它们的值也会保持不变。这与作为 Java 执行时的情况不同。
为了通过一个非常基础的示例来演示这一点,向应用程序添加一个新的 TimestampResource,其代码如下
package org.acme;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
@Path("/timestamp")
public class TimestampResource {
static long firstAccess = System.currentTimeMillis();
@GET
@Produces(MediaType.TEXT_PLAIN)
public String timestamp() {
return "First access " + firstAccess;
}
}使用以下命令重新构建二进制文件
./mvnw package -DskipTests -Dnative在一个终端中运行应用程序(执行此操作前请确保停止运行任何其他原生可执行容器)
docker run -i --rm -p 8080:8080 test/debugging-native:1.0.0-SNAPSHOT从另一个终端发送多次 GET 请求
curl -w '\n' https://:8080/timestamp # run this multiple times以查看当前时间已烘焙到二进制文件中。该时间是在构建二进制文件时计算的,因此应用程序重启无效。
在某些情况下,构建时初始化会导致构建原生可执行文件时出错。一个例子是当一个值在构建时被计算出来,而这个值不允许驻留在烘焙到二进制文件中的 JVM 堆中。为了演示这一点,请添加此 REST 资源
package org.acme;
import javax.crypto.Cipher;
import javax.crypto.NoSuchPaddingException;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import java.nio.charset.StandardCharsets;
import java.security.KeyPair;
import java.security.KeyPairGenerator;
import java.security.NoSuchAlgorithmException;
@Path("/encrypt-decrypt")
public class EncryptDecryptResource {
static final KeyPairGenerator KEY_PAIR_GEN;
static final Cipher CIPHER;
static {
try {
KEY_PAIR_GEN = KeyPairGenerator.getInstance("RSA");
KEY_PAIR_GEN.initialize(1024);
CIPHER = Cipher.getInstance("RSA");
} catch (NoSuchAlgorithmException | NoSuchPaddingException e) {
throw new RuntimeException(e);
}
}
@GET
@Path("/{message}")
public String encryptDecrypt(String message) throws Exception {
KeyPair keyPair = KEY_PAIR_GEN.generateKeyPair();
byte[] text = message.getBytes(StandardCharsets.UTF_8);
// Encrypt with private key
CIPHER.init(Cipher.ENCRYPT_MODE, keyPair.getPrivate());
byte[] encrypted = CIPHER.doFinal(text);
// Decrypt with public key
CIPHER.init(Cipher.DECRYPT_MODE, keyPair.getPublic());
byte[] unencrypted = CIPHER.doFinal(encrypted);
return new String(unencrypted, StandardCharsets.UTF_8);
}
}当尝试重新构建应用程序时,您会遇到一个错误
./mvnw package -DskipTests -Dnative
...
Error: Unsupported features in 2 methods
Detailed message:
Error: Detected an instance of Random/SplittableRandom class in the image heap. Instances created during image generation have cached seed values and don't behave as expected. To see how this object got instantiated use --trace-object-instantiation=java.security.SecureRandom. The object was probably created by a class initializer and is reachable from a static field. You can request class initialization at image runtime by using the option --initialize-at-run-time=<class-name>. Or you can write your own initialization methods and call them explicitly from your main entry point.
Trace: Object was reached by
reading field java.security.KeyPairGenerator$Delegate.initRandom of
constant java.security.KeyPairGenerator$Delegate@58b0fe1b reached by
reading field org.acme.EncryptDecryptResource.KEY_PAIR_GEN
Error: Detected an instance of Random/SplittableRandom class in the image heap. Instances created during image generation have cached seed values and don't behave as expected. To see how this object got instantiated use --trace-object-instantiation=java.security.SecureRandom. The object was probably created by a class initializer and is reachable from a static field. You can request class initialization at image runtime by using the option --initialize-at-run-time=<class-name>. Or you can write your own initialization methods and call them explicitly from your main entry point.
Trace: Object was reached by
reading field sun.security.rsa.RSAKeyPairGenerator.random of
constant sun.security.rsa.RSAKeyPairGenerator$Legacy@3248a092 reached by
reading field java.security.KeyPairGenerator$Delegate.spi of
constant java.security.KeyPairGenerator$Delegate@58b0fe1b reached by
reading field org.acme.EncryptDecryptResource.KEY_PAIR_GEN因此,上述消息告诉我们,我们的应用程序将一个本应是随机的值缓存为常量。这是不理想的,因为一个本应是随机的东西不再是随机的,因为种子被烘焙到镜像中了。上述消息清楚地说明了原因,但在其他情况下,原因可能更加模糊。下一步,我们将添加一些额外的标志来生成原生可执行文件以获取更多信息。
正如消息所示,让我们首先添加一个跟踪对象实例化的选项
./mvnw package -DskipTests -Dnative \
-Dquarkus.native.additional-build-args="--trace-object-instantiation=java.security.SecureRandom"
...
Error: Unsupported features in 2 methods
Detailed message:
Error: Detected an instance of Random/SplittableRandom class in the image heap. Instances created during image generation have cached seed values and don't behave as expected. Object has been initialized by the com.sun.jndi.dns.DnsClient class initializer with a trace:
at java.security.SecureRandom.<init>(SecureRandom.java:218)
at sun.security.jca.JCAUtil$CachedSecureRandomHolder.<clinit>(JCAUtil.java:59)
at sun.security.jca.JCAUtil.getSecureRandom(JCAUtil.java:69)
at com.sun.jndi.dns.DnsClient.<clinit>(DnsClient.java:82)
. Try avoiding to initialize the class that caused initialization of the object. The object was probably created by a class initializer and is reachable from a static field. You can request class initialization at image runtime by using the option --initialize-at-run-time=<class-name>. Or you can write your own initialization methods and call them explicitly from your main entry point.
Trace: Object was reached by
reading field java.security.KeyPairGenerator$Delegate.initRandom of
constant java.security.KeyPairGenerator$Delegate@4a5058f9 reached by
reading field org.acme.EncryptDecryptResource.KEY_PAIR_GEN
Error: Detected an instance of Random/SplittableRandom class in the image heap. Instances created during image generation have cached seed values and don't behave as expected. Object has been initialized by the com.sun.jndi.dns.DnsClient class initializer with a trace:
at java.security.SecureRandom.<init>(SecureRandom.java:218)
at sun.security.jca.JCAUtil$CachedSecureRandomHolder.<clinit>(JCAUtil.java:59)
at sun.security.jca.JCAUtil.getSecureRandom(JCAUtil.java:69)
at com.sun.jndi.dns.DnsClient.<clinit>(DnsClient.java:82)
. Try avoiding to initialize the class that caused initialization of the object. The object was probably created by a class initializer and is reachable from a static field. You can request class initialization at image runtime by using the option --initialize-at-run-time=<class-name>. Or you can write your own initialization methods and call them explicitly from your main entry point.
Trace: Object was reached by
reading field sun.security.rsa.RSAKeyPairGenerator.random of
constant sun.security.rsa.RSAKeyPairGenerator$Legacy@71880cf1 reached by
reading field java.security.KeyPairGenerator$Delegate.spi of
constant java.security.KeyPairGenerator$Delegate@4a5058f9 reached by
reading field org.acme.EncryptDecryptResource.KEY_PAIR_GEN错误消息指向示例中的代码,但引用 DnsClient 的出现可能会令人惊讶。为什么呢?关键在于 KeyPairGenerator.initialize() 方法调用内部发生了什么。它使用了 JCAUtil.getSecureRandom(),这就是为什么这会引起问题,但有时跟踪选项会显示一些不代表实际情况的堆栈跟踪。最佳选择是深入研究源代码并使用跟踪输出来指导,但不能作为全部真相。
将 KEY_PAIR_GEN.initialize(1024); 调用移动到运行时执行的方法 encryptDecrypt 足以解决此特定问题。重新构建应用程序,并通过发送任何消息并检查回复是否与传入消息相同来验证加密/解密端点是否按预期工作
$ ./mvnw package -DskipTests -Dnative
...
$ docker run -i --rm -p 8080:8080 test/debugging-native:1.0.0-SNAPSHOT
...
$ curl -w '\n' https://:8080/encrypt-decrypt/hellomandrel
hellomandrel通过传递 -H:+PrintClassInitialization 标志(通过 -Dquarkus.native.additional-build-args),可以获得有关哪些类被初始化以及为什么被初始化的额外信息。
分析运行时行为
单线程
在本练习中,我们将分析编译为原生可执行文件的某个 Quarkus 应用程序的运行时行为,以确定瓶颈所在。假设您遇到的情况是无法分析纯 Java 版本,可能是因为问题仅在应用程序的原生版本中出现。
添加一个具有以下代码的 REST 资源(示例来自 Andrei Pangin 的 Java Profiling 演示文稿)
package org.acme;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
@Path("/string-builder")
public class StringBuilderResource {
@GET
@Produces(MediaType.TEXT_PLAIN)
public String appendDelete() {
StringBuilder sb = new StringBuilder();
sb.append(new char[1_000_000]);
do
{
sb.append(12345);
sb.delete(0, 5);
} while (Thread.currentThread().isAlive());
return "Never happens";
}
}重新编译应用程序,重建二进制文件并运行它。尝试一个简单的 curl 请求将永远不会完成,正如预期的那样
$ ./mvnw package -DskipTests -Dnative
...
$ docker run -i --rm -p 8080:8080 test/debugging-native:1.0.0-SNAPSHOT
...
$ curl https://:8080/string-builder # this will never complete但是,我们在这里试图回答的问题是:此类代码的瓶颈是什么?是追加字符?是删除它?是检查线程是否活动?
由于我们处理的是一个 Linux 原生可执行文件,我们可以直接使用 perf 等工具。要使用 perf,请转到项目根目录并以特权用户身份启动之前创建的工具容器
docker run --privileged -t -i --rm -v ${PWD}:/data -p 8080:8080 fedora-tools:v1|
请注意,为了使用 |
容器运行后,您需要确保内核已准备好进行性能分析练习
echo -1 | sudo tee /proc/sys/kernel/perf_event_paranoid
echo 0 | sudo tee /proc/sys/kernel/kptr_restrict|
上述内核修改也适用于 Linux 虚拟机。如果运行在裸金属 Linux 机器上,仅调整 |
然后,从工具容器内部执行
perf record -F 1009 -g -a ./target/debugging-native-1.0.0-SNAPSHOT-runner|
上述 |
当 perf record 运行时,打开另一个窗口并访问端点
curl https://:8080/string-builder # this will never complete几秒钟后,停止 perf record 进程。这将生成一个 perf.data 文件。我们可以使用 perf report 来检查 perf 数据,但通常通过将数据显示为火焰图可以获得更好的图像。为了生成火焰图,我们将使用 FlameGraph GitHub 存储库,该存储库已安装在工具容器中。
接下来,使用 perf record 捕获的数据生成火焰图
perf script -i perf.data | ${FG_HOME}/stackcollapse-perf.pl | ${FG_HOME}/flamegraph.pl > flamegraph.svg火焰图是一个 svg 文件,Web 浏览器(如 Firefox)可以轻松显示。在上述两个命令完成后,可以在浏览器中打开 flamegraph.svg

我们看到大部分时间都花在了我们认为是主程序中的内容上,但我们没有看到 StringBuilderResource 类或我们调用的 StringBuilder 类的任何踪迹。我们应该查看二进制文件的符号表:我们能否找到我们类和 StringBuilder 的符号?我们需要它们才能获得有意义的数据。从工具容器内部查询符号表
objdump -t ./target/debugging-native-1.0.0-SNAPSHOT-runner | grep StringBuilder
[no output]查询符号表时没有输出。这就是为什么我们在火焰图中看不到任何调用图。这是原生镜像的一个刻意决定。默认情况下,它会从二进制文件中删除符号。
为了恢复符号,我们需要重新构建二进制文件,指示 GraalVM 不要删除符号。除此之外,启用 DWARF 调试信息,以便堆栈跟踪可以填充该信息。从工具容器外部执行
./mvnw package -DskipTests -Dnative \
-Dquarkus.native.debug.enabled \
-Dquarkus.native.additional-build-args=-H:-DeleteLocalSymbols接下来,如果您已退出,请重新进入工具容器,并使用 objdump 检查原生可执行文件,并查看符号现在是如何存在的
$ objdump -t ./target/debugging-native-1.0.0-SNAPSHOT-runner | grep StringBuilder
000000000050a940 l F .text 0000000000000091 .hidden ReflectionAccessorHolder_StringBuilderResource_appendDelete_9e06d4817d0208a0cce97ebcc0952534cac45a19_e22addf7d3eaa3ad14013ce01941dc25beba7621
000000000050a9e0 l F .text 00000000000000bb .hidden ReflectionAccessorHolder_StringBuilderResource_constructor_0f8140ea801718b80c05b979a515d8a67b8f3208_12baae06bcd6a1ef9432189004ae4e4e176dd5a4
...您应该看到一个长列表的符合该模式的符号。
然后,通过 perf 运行可执行文件,**指示调用图是 dwarf**
perf record -F 1009 --call-graph dwarf -a ./target/debugging-native-1.0.0-SNAPSHOT-runner再次运行 curl 命令,停止二进制文件,生成火焰图并打开它
perf script -i perf.data | ${FG_HOME}/stackcollapse-perf.pl | ${FG_HOME}/flamegraph.pl > flamegraph.svg火焰图现在显示了瓶颈所在。它是在调用 StringBuilder.delete() 时发生的,该方法又调用了 System.arraycopy()。问题在于,需要以非常小的增量移动一百万个字符

多线程
多线程程序在理解其运行时行为时可能需要特别注意。为了演示这一点,请将此 MulticastResource 代码添加到您的项目中(示例来自 Andrei Pangin 的 Java Profiling 演示文稿)
package org.acme;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.DatagramChannel;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.atomic.AtomicInteger;
@Path("/multicast")
public class MulticastResource
{
@GET
@Produces(MediaType.TEXT_PLAIN)
public String send() throws Exception {
sendMulticasts();
return "Multicast packets sent";
}
static void sendMulticasts() throws Exception {
DatagramChannel ch = DatagramChannel.open();
ch.bind(new InetSocketAddress(5555));
ch.configureBlocking(false);
ExecutorService pool =
Executors.newCachedThreadPool(new ShortNameThreadFactory());
for (int i = 0; i < 10; i++) {
pool.submit(() -> {
final ByteBuffer buf = ByteBuffer.allocateDirect(1000);
final InetSocketAddress remoteAddr =
new InetSocketAddress("127.0.0.1", 5556);
while (true) {
buf.clear();
ch.send(buf, remoteAddr);
}
});
}
System.out.println("Warming up...");
Thread.sleep(3000);
System.out.println("Benchmarking...");
Thread.sleep(5000);
}
private static final class ShortNameThreadFactory implements ThreadFactory {
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix = "thread-";
public Thread newThread(Runnable r) {
return new Thread(r, namePrefix + threadNumber.getAndIncrement());
}
}
}使用调试信息构建原生可执行文件
./mvnw package -DskipTests -Dnative \
-Dquarkus.native.debug.enabled \
-Dquarkus.native.additional-build-args=-H:-DeleteLocalSymbols从工具容器内部(作为特权用户)使用 perf 运行原生可执行文件
perf record -F 1009 --call-graph dwarf -a ./target/debugging-native-1.0.0-SNAPSHOT-runner调用端点以发送多播数据包
curl -w '\n' https://:8080/multicast生成并打开火焰图
perf script -i perf.data | ${FG_HOME}/stackcollapse-perf.pl | ${FG_HOME}/flamegraph.pl > flamegraph.svg
生成的火焰图看起来很奇怪。每个线程都独立处理,即使它们都做相同的工作。这使得难以清晰地了解程序的瓶颈。
这种情况发生的原因是,从 perf 的角度来看,每个线程都是一个不同的命令。如果检查 perf report,我们可以看到这一点
perf report --stdio
# Children Self Command Shared Object Symbol
# ........ ........ ............... ...................................... ......................................................................................
...
6.95% 0.03% thread-2 debugging-native-1.0.0-SNAPSHOT-runner [.] MulticastResource_lambda$sendMulticasts$0_cb1f7b5dcaed7dd4e3f90d18bad517d67eae4d88
...
4.60% 0.02% thread-10 debugging-native-1.0.0-SNAPSHOT-runner [.] MulticastResource_lambda$sendMulticasts$0_cb1f7b5dcaed7dd4e3f90d18bad517d67eae4d88
...可以通过对 perf 输出进行一些修改来解决此问题,以使所有线程具有相同的名称。例如
perf script | sed -E "s/thread-[0-9]*/thread/" | ${FG_HOME}/stackcollapse-perf.pl | ${FG_HOME}/flamegraph.pl > flamegraph.svg
当您打开火焰图时,您将看到所有线程的工作都折叠到单个区域中。然后,您可以清楚地看到存在一些可能影响性能的锁定。
调试原生崩溃
使用原生可执行文件的一个缺点是它们不能使用标准的 Java 调试器进行调试,而是需要使用 GNU 项目调试器 gdb 进行调试。为了演示如何做到这一点,我们将生成一个原生的 Quarkus 应用程序,该应用程序在访问 https://:8080/crash 时因段错误而崩溃。为了实现这一点,请将以下 REST 资源添加到项目中
package org.acme;
import sun.misc.Unsafe;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import java.lang.reflect.Field;
@Path("/crash")
public class CrashResource {
@GET
@Produces(MediaType.TEXT_PLAIN)
public String hello() {
Field theUnsafe = null;
try {
theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
theUnsafe.setAccessible(true);
Unsafe unsafe = (Unsafe) theUnsafe.get(null);
unsafe.copyMemory(0, 128, 256);
} catch (NoSuchFieldException | IllegalAccessException e) {
e.printStackTrace();
}
return "Never happens";
}
}此代码将尝试将 256 字节从地址 0x0 复制到 0x80,从而导致段错误。为了验证这一点,请编译并运行示例应用程序
$ ./mvnw package -DskipTests -Dnative
...
$ docker run -i --rm -p 8080:8080 test/debugging-native:1.0.0-SNAPSHOT
...
$ curl https://:8080/crash这将产生以下输出
$ docker run -i --rm -p 8080:8080 test/debugging-native:1.0.0-SNAPSHOT
...
Segfault detected, aborting process. Use runtime option -R:-InstallSegfaultHandler if you don't want to use SubstrateSegfaultHandler.
...上述省略的输出包含导致问题的线索,但在本练习中,我们将假设没有提供信息。让我们尝试使用 gdb 调试段错误。为此,请转到项目根目录并进入工具容器
docker run -t -i --rm -v ${PWD}:/data -p 8080:8080 fedora-tools:v1 /bin/bash然后使用 run 命令在 gdb 中启动应用程序。
gdb ./target/debugging-native-1.0.0-SNAPSHOT-runner
...
Reading symbols from ./target/debugging-native-1.0.0-SNAPSHOT-runner...
(No debugging symbols found in ./target/debugging-ntaive-1.0.0-SNAPSHOT-runner)
(gdb) run
Starting program: /data/target/debugging-native-1.0.0-SNAPSHOT-runner接下来,尝试访问 https://:8080/crash
curl https://:8080/crash这将在 gdb 中产生以下消息
Thread 4 "ecutor-thread-0" received signal SIGSEGV, Segmentation fault.
[Switching to Thread 0x7fe103dff640 (LWP 190)]
0x0000000000461f6e in ?? ()如果我们尝试获取有关导致此崩溃的回溯的更多信息,我们将看到信息不足。
(gdb) bt
#0 0x0000000000418b5e in ?? ()
#1 0x00007ffff6f2d328 in ?? ()
#2 0x0000000000418a04 in ?? ()
#3 0x00007ffff44062a0 in ?? ()
#4 0x00000000010c3dd3 in ?? ()
#5 0x0000000000000100 in ?? ()
#6 0x0000000000000000 in ?? ()这是因为我们没有使用 -Dquarkus.native.debug.enabled 编译 Quarkus 应用程序,因此 gdb 无法找到我们原生可执行文件的调试符号,如 gdb 开头处的“在 ./target/debugging-native-1.0.0-SNAPSHOT-runner 中找不到调试符号”消息所示。
通过使用 -Dquarkus.native.debug.enabled 重新编译 Quarkus 应用程序并再次通过 gdb 运行它,我们现在可以获得回溯,从而清楚地了解导致崩溃的原因。此外,添加 -H:-OmitInlinedMethodDebugLineInfo 选项以防止内联方法从回溯中省略
./mvnw package -DskipTests -Dnative \
-Dquarkus.native.debug.enabled \
-Dquarkus.native.additional-build-args=-H:-OmitInlinedMethodDebugLineInfo
...
$ gdb ./target/debugging-native-1.0.0-SNAPSHOT-runner
Reading symbols from ./target/debugging-native-1.0.0-SNAPSHOT-runner...
(gdb) run
Starting program: /data/target/debugging-native-1.0.0-SNAPSHOT-runner
...
$ curl https://:8080/crash这将在 gdb 中产生以下消息
Thread 4 "ecutor-thread-0" received signal SIGSEGV, Segmentation fault.
[Switching to Thread 0x7fffeffff640 (LWP 362984)]
com.oracle.svm.core.UnmanagedMemoryUtil::copyLongsBackward(org.graalvm.word.Pointer *, org.graalvm.word.Pointer *, org.graalvm.word.UnsignedWord *) ()
at com/oracle/svm/core/UnmanagedMemoryUtil.java:169
169 com/oracle/svm/core/UnmanagedMemoryUtil.java: No such file or directory.我们已经看到 gdb 能够告诉我们哪个方法导致了崩溃以及它在源代码中的位置。我们还可以获得导致我们进入此状态的调用图的回溯
(gdb) bt
#0 com.oracle.svm.core.UnmanagedMemoryUtil::copyLongsBackward(org.graalvm.word.Pointer *, org.graalvm.word.Pointer *, org.graalvm.word.UnsignedWord *) () at com/oracle/svm/core/UnmanagedMemoryUtil.java:169
#1 0x0000000000461e14 in com.oracle.svm.core.UnmanagedMemoryUtil::copyBackward(org.graalvm.word.Pointer *, org.graalvm.word.Pointer *, org.graalvm.word.UnsignedWord *) () at com/oracle/svm/core/UnmanagedMemoryUtil.java:110
#2 0x0000000000461dc8 in com.oracle.svm.core.UnmanagedMemoryUtil::copy(org.graalvm.word.Pointer *, org.graalvm.word.Pointer *, org.graalvm.word.UnsignedWord *) () at com/oracle/svm/core/UnmanagedMemoryUtil.java:67
#3 0x000000000045d3c0 in com.oracle.svm.core.JavaMemoryUtil::unsafeCopyMemory(java.lang.Object *, long, java.lang.Object *, long, long) () at com/oracle/svm/core/JavaMemoryUtil.java:276
#4 0x00000000013277de in jdk.internal.misc.Unsafe::copyMemory0 () at com/oracle/svm/core/jdk/SunMiscSubstitutions.java:125
#5 jdk.internal.misc.Unsafe::copyMemory(java.lang.Object *, long, java.lang.Object *, long, long) () at jdk/internal/misc/Unsafe.java:788
#6 0x00000000013b1a3f in jdk.internal.misc.Unsafe::copyMemory () at jdk/internal/misc/Unsafe.java:799
#7 sun.misc.Unsafe::copyMemory () at sun/misc/Unsafe.java:585
#8 org.acme.CrashResource::hello(void) () at org/acme/CrashResource.java:22类似地,我们可以获得其他线程的调用图的回溯。
-
首先,我们可以使用以下命令列出可用线程
(gdb) info threads Id Target Id Frame 1 Thread 0x7fcc62a07d00 (LWP 322) "debugging-nativ" 0x00007fcc62b8b77a in __futex_abstimed_wait_common () from /lib64/libc.so.6 2 Thread 0x7fcc60eff640 (LWP 326) "gnal Dispatcher" 0x00007fcc62b8b77a in __futex_abstimed_wait_common () from /lib64/libc.so.6 * 4 Thread 0x7fcc5b7fe640 (LWP 328) "ecutor-thread-0" com.oracle.svm.core.UnmanagedMemoryUtil::copyLongsBackward(org.graalvm.word.Pointer *, org.graalvm.word.Pointer *, org.graalvm.word.UnsignedWord *) () at com/oracle/svm/core/UnmanagedMemoryUtil.java:169 5 Thread 0x7fcc5abff640 (LWP 329) "-thread-checker" 0x00007fcc62b8b77a in __futex_abstimed_wait_common () from /lib64/libc.so.6 6 Thread 0x7fcc59dff640 (LWP 330) "ntloop-thread-0" 0x00007fcc62c12c9e in epoll_wait () from /lib64/libc.so.6 ... -
选择要检查的线程,例如线程 1
(gdb) thread 1 [Switching to thread 1 (Thread 0x7ffff7a58d00 (LWP 1028851))] #0 __futex_abstimed_wait_common64 (private=0, cancel=true, abstime=0x0, op=393, expected=0, futex_word=0x2cd7adc) at futex-internal.c:57 57 return INTERNAL_SYSCALL_CANCEL (futex_time64, futex_word, op, expected, -
最后,打印堆栈跟踪
(gdb) bt #0 __futex_abstimed_wait_common64 (private=0, cancel=true, abstime=0x0, op=393, expected=0, futex_word=0x2cd7adc) at futex-internal.c:57 #1 __futex_abstimed_wait_common (futex_word=futex_word@entry=0x2cd7adc, expected=expected@entry=0, clockid=clockid@entry=0, abstime=abstime@entry=0x0, private=private@entry=0, cancel=cancel@entry=true) at futex-internal.c:87 #2 0x00007ffff7bdd79f in __GI___futex_abstimed_wait_cancelable64 (futex_word=futex_word@entry=0x2cd7adc, expected=expected@entry=0, clockid=clockid@entry=0, abstime=abstime@entry=0x0, private=private@entry=0) at futex-internal.c:139 #3 0x00007ffff7bdfeb0 in __pthread_cond_wait_common (abstime=0x0, clockid=0, mutex=0x2ca07b0, cond=0x2cd7ab0) at pthread_cond_wait.c:504 #4 ___pthread_cond_wait (cond=0x2cd7ab0, mutex=0x2ca07b0) at pthread_cond_wait.c:619 #5 0x00000000004e2014 in com.oracle.svm.core.posix.headers.Pthread::pthread_cond_wait () at com/oracle/svm/core/posix/thread/PosixJavaThreads.java:252 #6 com.oracle.svm.core.posix.thread.PosixParkEvent::condWait(void) () at com/oracle/svm/core/posix/thread/PosixJavaThreads.java:252 #7 0x0000000000547070 in com.oracle.svm.core.thread.JavaThreads::park(void) () at com/oracle/svm/core/thread/JavaThreads.java:764 #8 0x0000000000fc5f44 in jdk.internal.misc.Unsafe::park(boolean, long) () at com/oracle/svm/core/thread/Target_jdk_internal_misc_Unsafe_JavaThreads.java:49 #9 0x0000000000eac1ad in java.util.concurrent.locks.LockSupport::park(java.lang.Object *) () at java/util/concurrent/locks/LockSupport.java:194 #10 0x0000000000ea5d68 in java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject::awaitUninterruptibly(void) () at java/util/concurrent/locks/AbstractQueuedSynchronizer.java:2018 #11 0x00000000008b6b30 in io.quarkus.runtime.ApplicationLifecycleManager::run(io.quarkus.runtime.Application *, java.lang.Class *, java.util.function.BiConsumer *, java.lang.String[] *) () at io/quarkus/runtime/ApplicationLifecycleManager.java:144 #12 0x00000000008bc055 in io.quarkus.runtime.Quarkus::run(java.lang.Class *, java.util.function.BiConsumer *, java.lang.String[] *) () at io/quarkus/runtime/Quarkus.java:67 #13 0x000000000045c88b in io.quarkus.runtime.Quarkus::run () at io/quarkus/runtime/Quarkus.java:41 #14 io.quarkus.runtime.Quarkus::run () at io/quarkus/runtime/Quarkus.java:120 #15 0x000000000045c88b in io.quarkus.runner.GeneratedMain::main () #16 com.oracle.svm.core.JavaMainWrapper::runCore () at com/oracle/svm/core/JavaMainWrapper.java:150 #17 com.oracle.svm.core.JavaMainWrapper::run(int, org.graalvm.nativeimage.c.type.CCharPointerPointer *) () at com/oracle/svm/core/JavaMainWrapper.java:186 #18 0x000000000048084d in com.oracle.svm.core.code.IsolateEnterStub::JavaMainWrapper_run_5087f5482cc9a6abc971913ece43acb471d2631b(int, org.graalvm.nativeimage.c.type.CCharPointerPointer *) () at com/oracle/svm/core/JavaMainWrapper.java:280
或者,我们可以使用单个命令列出所有线程的回溯
(gdb) thread apply all backtrace
Thread 22 (Thread 0x7fffc8dff640 (LWP 1028872) "tloop-thread-15"):
#0 0x00007ffff7c64c2e in epoll_wait (epfd=8, events=0x2ca3880, maxevents=1024, timeout=-1) at ../sysdeps/unix/sysv/linux/epoll_wait.c:30
#1 0x000000000166e01c in Java_sun_nio_ch_EPoll_wait ()
#2 0x00000000011bfece in sun.nio.ch.EPoll::wait(int, long, int, int) () at com/oracle/svm/core/stack/JavaFrameAnchors.java:42
#3 0x00000000011c08d2 in sun.nio.ch.EPollSelectorImpl::doSelect(java.util.function.Consumer *, long) () at sun/nio/ch/EPollSelectorImpl.java:120
#4 0x00000000011d8977 in sun.nio.ch.SelectorImpl::lockAndDoSelect(java.util.function.Consumer *, long) () at sun/nio/ch/SelectorImpl.java:124
#5 0x0000000000705720 in sun.nio.ch.SelectorImpl::select () at sun/nio/ch/SelectorImpl.java:141
#6 io.netty.channel.nio.SelectedSelectionKeySetSelector::select(void) () at io/netty/channel/nio/SelectedSelectionKeySetSelector.java:68
#7 0x0000000000703c2e in io.netty.channel.nio.NioEventLoop::select(long) () at io/netty/channel/nio/NioEventLoop.java:813
#8 0x0000000000701a5f in io.netty.channel.nio.NioEventLoop::run(void) () at io/netty/channel/nio/NioEventLoop.java:460
#9 0x00000000008496df in io.netty.util.concurrent.SingleThreadEventExecutor$4::run(void) () at io/netty/util/concurrent/SingleThreadEventExecutor.java:986
#10 0x0000000000860762 in io.netty.util.internal.ThreadExecutorMap$2::run(void) () at io/netty/util/internal/ThreadExecutorMap.java:74
#11 0x0000000000840da4 in io.netty.util.concurrent.FastThreadLocalRunnable::run(void) () at io/netty/util/concurrent/FastThreadLocalRunnable.java:30
#12 0x0000000000b7dd04 in java.lang.Thread::run(void) () at java/lang/Thread.java:829
#13 0x0000000000547dcc in com.oracle.svm.core.thread.JavaThreads::threadStartRoutine(org.graalvm.nativeimage.ObjectHandle *) () at com/oracle/svm/core/thread/JavaThreads.java:597
#14 0x00000000004e15b1 in com.oracle.svm.core.posix.thread.PosixJavaThreads::pthreadStartRoutine(com.oracle.svm.core.thread.JavaThreads$ThreadStartData *) () at com/oracle/svm/core/posix/thread/PosixJavaThreads.java:194
#15 0x0000000000480984 in com.oracle.svm.core.code.IsolateEnterStub::PosixJavaThreads_pthreadStartRoutine_e1f4a8c0039f8337338252cd8734f63a79b5e3df(com.oracle.svm.core.thread.JavaThreads$ThreadStartData *) () at com/oracle/svm/core/posix/thread/PosixJavaThreads.java:182
#16 0x00007ffff7be0b1a in start_thread (arg=<optimized out>) at pthread_create.c:443
#17 0x00007ffff7c65650 in clone3 () at ../sysdeps/unix/sysv/linux/x86_64/clone3.S:81
Thread 21 (Thread 0x7fffc97fa640 (LWP 1028871) "tloop-thread-14"):
#0 0x00007ffff7c64c2e in epoll_wait (epfd=53, events=0x2cd0970, maxevents=1024, timeout=-1) at ../sysdeps/unix/sysv/linux/epoll_wait.c:30
#1 0x000000000166e01c in Java_sun_nio_ch_EPoll_wait ()
#2 0x00000000011bfece in sun.nio.ch.EPoll::wait(int, long, int, int) () at com/oracle/svm/core/stack/JavaFrameAnchors.java:42
#3 0x00000000011c08d2 in sun.nio.ch.EPollSelectorImpl::doSelect(java.util.function.Consumer *, long) () at sun/nio/ch/EPollSelectorImpl.java:120
#4 0x00000000011d8977 in sun.nio.ch.SelectorImpl::lockAndDoSelect(java.util.function.Consumer *, long) () at sun/nio/ch/SelectorImpl.java:124
#5 0x0000000000705720 in sun.nio.ch.SelectorImpl::select () at sun/nio/ch/SelectorImpl.java:141
#6 io.netty.channel.nio.SelectedSelectionKeySetSelector::select(void) () at io/netty/channel/nio/SelectedSelectionKeySetSelector.java:68
#7 0x0000000000703c2e in io.netty.channel.nio.NioEventLoop::select(long) () at io/netty/channel/nio/NioEventLoop.java:813
#8 0x0000000000701a5f in io.netty.channel.nio.NioEventLoop::run(void) () at io/netty/channel/nio/NioEventLoop.java:460
#9 0x00000000008496df in io.netty.util.concurrent.SingleThreadEventExecutor$4::run(void) () at io/netty/util/concurrent/SingleThreadEventExecutor.java:986
#10 0x0000000000860762 in io.netty.util.internal.ThreadExecutorMap$2::run(void) () at io/netty/util/internal/ThreadExecutorMap.java:74
#11 0x0000000000840da4 in io.netty.util.concurrent.FastThreadLocalRunnable::run(void) () at io/netty/util/concurrent/FastThreadLocalRunnable.java:30
#12 0x0000000000b7dd04 in java.lang.Thread::run(void) () at java/lang/Thread.java:829
#13 0x0000000000547dcc in com.oracle.svm.core.thread.JavaThreads::threadStartRoutine(org.graalvm.nativeimage.ObjectHandle *) () at com/oracle/svm/core/thread/JavaThreads.java:597
#14 0x00000000004e15b1 in com.oracle.svm.core.posix.thread.PosixJavaThreads::pthreadStartRoutine(com.oracle.svm.core.thread.JavaThreads$ThreadStartData *) () at com/oracle/svm/core/posix/thread/PosixJavaThreads.java:194
#15 0x0000000000480984 in com.oracle.svm.core.code.IsolateEnterStub::PosixJavaThreads_pthreadStartRoutine_e1f4a8c0039f8337338252cd8734f63a79b5e3df(com.oracle.svm.core.thread.JavaThreads$ThreadStartData *) () at com/oracle/svm/core/posix/thread/PosixJavaThreads.java:182
#16 0x00007ffff7be0b1a in start_thread (arg=<optimized out>) at pthread_create.c:443
#17 0x00007ffff7c65650 in clone3 () at ../sysdeps/unix/sysv/linux/x86_64/clone3.S:81
Thread 20 (Thread 0x7fffc9ffb640 (LWP 1028870) "tloop-thread-13"):
...但是,请注意,尽管能够获得回溯,我们仍然无法使用 list 命令列出源代码位置。
(gdb) list
164 in com/oracle/svm/core/UnmanagedMemoryUtil.java这是因为 gdb 不知道源代码文件的位置。我们正在目标目录之外运行可执行文件。要解决此问题,我们可以从目标目录重新运行 gdb,或者运行 directory target/debugging-native-1.0.0-SNAPSHOT-native-image-source-jar/sources,例如
(gdb) directory target/debugging-native-1.0.0-SNAPSHOT-native-image-source-jar/sources
Source directories searched: /data/target/debugging-native-1.0.0-SNAPSHOT-native-image-source-jar/sources:$cdir:$cwd
(gdb) list
164 UnsignedWord offset = size;
165 while (offset.aboveOrEqual(32)) {
166 offset = offset.subtract(32);
167 Pointer src = from.add(offset);
168 Pointer dst = to.add(offset);
169 long l24 = src.readLong(24);
170 long l16 = src.readLong(16);
171 long l8 = src.readLong(8);
172 long l0 = src.readLong(0);
173 dst.writeLong(24, l24);我们现在可以检查第 169 行并获得可能出错的第一个提示(在这种情况下,我们看到它在第一次从 src 读取时失败,src 包含地址 0x0000),或者使用 gdb 的 up 命令向上遍历堆栈,以查看我们代码的哪个部分导致了这种情况。有关使用 gdb 调试原生可执行文件的更多信息,请参阅 GraalVM 调试信息功能指南。
常见问题解答
为什么生成原生可执行文件的过程很慢?
原生可执行文件生成是一个多步骤过程。分析和编译步骤是最耗时的,因此它们主导了生成原生可执行文件所花费的时间。
在分析阶段,静态指向分析从程序的 main 方法开始,以找出什么代码是可达的。当发现新类时,其中一些类会在此过程中根据配置进行初始化。在下一步中,将对堆进行快照,并检查哪些类型需要在运行时可用。初始化和堆快照可能导致发现新类型,在这种情况下,过程会重复。当达到固定点时,即可达程序不再增长时,过程停止。
编译步骤非常直接,它只编译所有可达的代码。
分析和编译阶段花费的时间取决于应用程序的大小。应用程序越大,编译所需的时间就越长。但是,某些功能会产生指数级影响。例如,当为反射访问注册类型和方法时,分析无法轻松看到这些类型或方法背后的内容,因此它必须做更多的工作才能完成分析步骤。
我收到有关使用实验性选项的警告,我该怎么办?
从 Mandrel 23.1 和 GraalVM for JDK 21 开始,原生可执行文件生成过程将使用类似以下消息的警告来提示使用实验性选项
Warning: The option '-H:ReflectionConfigurationResources=META-INF/native-image/io.micrometer/micrometer-core/reflect-config.json' is experimental and must be enabled via '-H:+UnlockExperimentalVMOptions' in the future.如果提到的选项是由第三方库添加的(如上面的示例),您应该考虑在库的存储库中打开一个 issue,要求删除该选项。如果该选项由您的应用程序添加,您应该考虑将其包装在 -H:+UnlockExperimentalVMOptions 和 -H:-UnlockExperimentalVMOptions 之间,或者删除它(如果它不是必需的)。
我在构建原生可执行文件时收到 AnalysisError$ParsingError,因为 UnresolvedElementException,我该怎么办?
构建原生可执行文件时,Quarkus 要求所有代码引用的类,无论它们是构建时还是运行时初始化的,都必须存在于类路径中。这样可以确保运行时不会因为潜在的 NoClassDefFoundError 异常而崩溃。为此,它使用 GraalVM 的 --link-at-build-time 参数
--link-at-build-time require types to be fully defined at image build-time. If used
without args, all classes in scope of the option are required to
be fully defined.但是,这可能会在构建时导致 AnalysisError$ParsingError,因为 UnresolvedElementException。这通常是由应用程序引用可选依赖项中的类引起的。
如果您可以访问引起对缺失依赖项引用的源代码并可以修改它,您应该考虑以下措施之一
-
如果引用实际上不是必需的,请删除该引用。
-
将受影响的代码移到子模块中,并使依赖项成为非可选的(这是最佳实践)。
-
使依赖项成为非可选的。
在不幸的情况下,当引用是由您无法修改的第三方库引起的时,您应该考虑以下措施之一
-
使用类/方法替换来删除所述引用。
-
将可选依赖项添加为项目的非可选依赖项。
请注意,虽然选项 (1) 在性能上是最佳选择,因为它最小化了应用程序的内存占用,但它可能并不容易实现。更糟糕的是,它也不容易维护,因为它与第三方库的实现紧密耦合。选项 (2) 是解决问题的直接替代方案,但代价是将可能永远不会被调用的代码包含在生成的原生可执行文件中。
构建原生可执行文件时出现 OutOfMemoryError (OOME),我该怎么办?
构建原生可执行文件不仅耗时,而且还需要相当多的内存。例如,构建一个示例原生 Quarkus Jakarta Persistence 应用程序(如 Hibernate ORM quickstart)可能需要 6GB 到 8GB 的内存常驻集大小。其中大部分内存是 Java 堆,但还需要额外的内存来运行原生构建过程的 JVM 的其他方面。仍然可以在总内存接近极限的环境中构建此类应用程序,但为此需要缩小 GraalVM 原生镜像进程的最大堆大小。为此,请使用 quarkus.native.native-image-xmx 属性设置最大堆大小。例如,我们可以通过传递 -Dquarkus.native.native-image-xmx=5g 作为命令行参数来指示 GraalVM 使用 5GB 的最大堆大小。
以这种方式构建原生可执行文件可能会导致完成时间更长。这是因为垃圾回收必须更努力地工作,以便原生镜像生成有空间来执行其任务。
请注意,典型的应用程序可能比 quickstart 更大,因此内存需求也可能更高。
为什么原生可执行文件的运行时性能不如 JVM 模式?
正如生活中的大多数事情一样,选择原生编译而不是 JVM 模式会涉及一些权衡。因此,根据应用程序的不同,原生应用程序的运行时性能可能比 JVM 模式慢,尽管并非总是如此。
JVM 执行应用程序包括代码的运行时优化,这些优化从执行过程中收集的配置文件中受益。这包括内联更多代码的机会,将热代码定位在直接路径上(即确保更好的指令缓存局部性)以及从冷路径中删除大量代码(在 JVM 中,许多代码直到有人尝试执行它才会被编译——它被一个导致去优化和重新编译的陷阱替换)。删除冷路径提供了比提前编译更多的优化机会,因为它显著减少了已编译的少量热代码的分支复杂性和组合逻辑。
相比之下,原生可执行文件编译在离线编译代码时必须考虑所有可能的执行路径,因为它不知道哪些是热路径或冷路径,也无法使用植入陷阱并在命中时重新编译的技巧。出于同样的原因,它无法加载骰子来确保通过共定位热路径来最小化代码缓存冲突。原生可执行文件生成能够移除一些代码,因为有了封闭世界假设,但这通常不足以弥补配置文件和运行时去优化与重新编译为 JVM JIT 编译器提供的所有优势。
但请注意,您需要为可能更高的 JVM 速度付出代价,而这个代价是增加资源使用(CPU 和内存)和启动时间,因为
-
代码需要解释执行一段时间,并且可能被多次编译,才能实现所有潜在的优化。
-
JIT 编译器消耗的资源本可以由应用程序使用。
-
JVM 必须保留更多的元数据和编译器/配置文件数据,以支持它能提供的更好优化。
1) 的原因是代码需要解释执行一段时间,并且可能需要多次编译才能确保
-
编译该代码路径是值得的,即它被执行的次数足够多,并且
-
我们有足够的配置文件数据来进行有意义的优化。
1) 的一个含义是,对于小型、短暂的应用程序,原生可执行文件可能是一个更好的选择。尽管编译的代码优化程度不高,但它可以立即获得。
2) 的原因是 JVM 本质上是在运行时与应用程序本身并行运行编译器。在原生可执行文件的情况下,编译器是在提前运行的,从而无需与应用程序并行运行编译器。
3) 有几个原因。JVM 没有封闭世界假设。因此,如果加载新类意味着它需要修改编译时进行的乐观假设,那么它必须能够重新编译代码。例如,如果一个接口只有一个实现,它可以将调用直接跳转到该代码。然而,在加载第二个实现类的情况下,调用站点需要被修补以测试接收者实例的类型并跳转到属于其类的代码。支持像这样的优化需要保留比原生可执行文件更多的类基础细节,包括记录完整的类和接口层次结构、哪些方法覆盖了其他方法、所有方法字节码等。在原生可执行文件中,运行时可以忽略大部分类结构和字节码的详细信息。
JVM 还必须应对类基础或执行配置文件的更改,导致线程进入以前的冷路径。此时,JVM 必须从编译代码跳到解释器并重新编译代码以处理包含以前冷路径的新执行配置文件。这需要保留允许编译堆栈帧被一个或多个解释器帧替换的运行时信息。它还需要分配和更新运行时可扩展的配置文件计数器,以跟踪已执行或未执行的内容。
为什么原生可执行文件“大”?
这可以归因于多种原因
-
原生可执行文件不仅包含应用程序代码,还包含库代码和 JDK 代码。因此,更公平的比较是将原生可执行文件的大小与应用程序的大小加上它使用的库的大小,再加上 JDK 的大小进行比较。即使在简单的 HelloWorld 等应用程序中,JDK 部分也并非微不足道。要大致了解镜像中包含的内容,可以在构建原生可执行文件时使用
-H:+PrintUniverse。 -
即使它们可能从未在运行时实际使用过,某些功能也始终包含在原生可执行文件中。例如垃圾回收。在编译时,我们无法确定应用程序是否需要在运行时运行垃圾回收,因此垃圾回收始终包含在原生可执行文件中,即使不需要也会增加其大小。原生可执行文件生成依赖于静态代码分析来识别哪些代码路径是可达的,而静态代码分析可能不精确,导致将比实际需要更多的代码包含到镜像中。
有一个 GraalVM 上游 issue 讨论了该主题,其中包含一些有趣的讨论。
生成二进制文件使用了哪个版本的 Mandrel?
可以通过检查二进制文件来查看使用了哪个 Mandrel 版本来生成二进制文件
$ strings target/debugging-native-1.0.0-SNAPSHOT-runner | \
grep -e 'com.oracle.svm.core.VM=' -e 'com.oracle.svm.core.VM.Java.Version' -F
com.oracle.svm.core.VM.Java.Version=21.0.5
com.oracle.svm.core.VM=Mandrel-23.1.5.0-Final如何在原生可执行文件中启用 GC 日志记录?
有关详细信息,请参阅 原生内存管理 GC 日志记录部分。
我能获取原生可执行文件的线程转储吗?
是的,Quarkus 为 SIGQUIT 信号(或 Windows 上的 SIGBREAK)设置了一个信号处理程序,该处理程序在接收到 SIGQUIT/SIGBREAK 信号时会打印线程转储。您可以使用 kill -SIGQUIT <pid> 来触发线程转储。
|
Quarkus 使用自己的信号处理程序,要使用 GraalVM 的默认信号处理程序,您需要:1. 将 |
我能获取原生可执行文件的堆转储吗?例如,如果它内存不足
从 GraalVM 22.2.0 开始,可以根据请求创建堆转储,例如 kill -SIGUSR1 <pid>。支持在内存不足错误时转储堆转储将在稍后推出。
我可以在 Linux 中的容器外构建和运行这些示例吗?
是的,您可以。实际上,在 Linux 裸金属盒上调试原生可执行文件可提供最佳体验。在这种环境中,不需要 root 访问权限,除非需要安装运行某些调试步骤所需的软件包,或者启用 perf 来收集内核事件。
以下是在 Linux 环境中运行不同调试部分所需的软件包
# dnf (rpm-based)
sudo dnf install binutils gdb perf perl-open
# Debian-based distributions:
sudo apt install binutils gdb perf生成火焰图很慢,或者产生错误,我该怎么办?
有多种方法可以对 Mandrel 生成的原生可执行文件进行性能分析。所有方法都需要您传递 -H:-DeleteLocalSymbols 选项。
本参考指南中显示的方法生成一个带有 DWARF 调试信息的二进制文件,通过 perf record 运行它,然后使用 perf script 和火焰图工具生成火焰图。但是,在此二进制文件上执行的 perf script 后处理步骤可能会显得缓慢或显示某些 DWARF 错误。
生成火焰图的另一种方法是在生成原生可执行文件时传递 -H:+PreserveFramePointer 而不是生成 DWARF 调试信息。它指示二进制文件使用额外的寄存器来表示帧指针。这使 perf 能够进行堆栈遍历以分析运行时行为。要使用这些标志生成原生可执行文件,请执行以下操作
./mvnw package -DskipTests -Dnative
-Dquarkus.native.additional-build-args=-H:+PreserveFramePointer,-H:-DeleteLocalSymbols要从原生可执行文件中获取运行时性能信息,只需执行
perf record -F 1009 -g -a ./target/debugging-native-1.0.0-SNAPSHOT-runner生成运行时性能信息的推荐方法是使用调试信息,而不是生成保留帧指针的二进制文件。这是因为在原生可执行文件构建过程中添加调试信息对运行时性能没有负面影响,而保留帧指针则有。
DWARF 调试信息是在单独的文件中生成的,甚至可以从默认部署中省略,并且仅按需传输和使用,用于性能分析或调试目的。此外,调试信息的存在使 perf 能够显示相关的源代码行,因此它不会使原生可执行文件本身膨胀。为此,只需调用 perf report 并使用额外的参数来显示源代码行
perf report --stdio -F+srcline
...
83.69% 0.00% GreetingResource.java:20 ...
...
83.69% 0.00% AbstractStringBuilder.java:1025 ...
...
83.69% 0.00% ArraycopySnippets.java:95 ...保留帧指针的性能损失是由于在堆栈遍历中使用额外的寄存器,尤其是在 x86_64 上,相对于寄存器较少的 aarch64。使用这个额外的寄存器会减少可用于其他工作的寄存器数量,这可能导致性能损失。
我认为我发现了 native-image 中的一个 bug,我该如何用 IDE 调试它?
虽然可以在容器内远程调试进程,但通过在路径中安装 Mandrel 本地并将其添加到 shell 进程的路径中,可以更轻松地逐步调试 native-image。
原生可执行文件生成是两个 Java 进程顺序执行的结果。第一个进程非常短,其主要工作是为第二个进程设置。第二个进程负责大部分工作。调试一个进程或另一个进程的步骤略有不同。
首先讨论如何调试第二个进程,这是您最可能想要调试的进程。第二个进程的起点是 com.oracle.svm.hosted.NativeImageGeneratorRunner 类。要调试此进程,只需将 --debug-attach=*:8000 添加为额外的构建时参数
./mvnw package -DskipTests -Dnative \
-Dquarkus.native.additional-build-args=--debug-attach=*:8000第一个进程的起点是 com.oracle.svm.driver.NativeImages 类。在 GraalVM CE 发行版中,这个第一个进程是一个二进制文件,因此无法用传统的 Java IDE 进行调试。但是,Mandrel 发行版(或本地构建的 GraalVM CE 实例)将其保留为一个正常的 Java 进程,因此您可以通过将 --vm.agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=*:8000 添加为额外的构建参数来远程调试此进程,例如
$ ./mvnw package -DskipTests -Dnative \
-Dquarkus.native.additional-build-args=--vm.agentlib:jdwp=transport=dt_socket\\,server=y\\,suspend=y\\,address=*:8000我能使用 JFR/JMC 来调试或分析原生二进制文件吗?
Java Flight Recorder (JFR) 和 JDK Mission Control (JMC) 自 GraalVM CE 21.2.0 起可用于分析原生二进制文件。然而,与 HotSpot 相比,GraalVM 中的 JFR 目前功能有限。自定义事件 API 完全受支持,但某些 VM 级别功能不可用。未来的版本将继续添加更多事件和 JFR 功能。下表按版本概述了原生镜像 JFR 支持和限制。
| GraalVM 版本 | 支持 | 限制 |
|---|---|---|
GraalVM CE 21.3 和 Mandrel 21.3 |
|
|
GraalVM CE 22.3 和 Mandrel 22.3 |
|
|
GraalVM CE for JDK 17/20 和 Mandrel 23.0 |
|
|
GraalVM CE for JDK 23 和 Mandrel 24.1 |
|
|
要为您的 Quarkus 可执行文件添加 JFR 支持,请添加应用程序属性:-Dquarkus.native.monitoring=jfr。例如:
./mvnw package -DskipTests -Dnative -Dquarkus.native.container-build=true \
-Dquarkus.native.builder-image=quay.io/quarkus/ubi9-quarkus-mandrel-builder-image:jdk-21 \
-Dquarkus.native.monitoring=jfr编译完镜像后,通过运行时标志启用并启动 JFR:-XX:+FlightRecorder 和 -XX:StartFlightRecording。例如:
./target/debugging-native-1.0.0-SNAPSHOT-runner \
-XX:+FlightRecorder \
-XX:StartFlightRecording="filename=recording.jfr"有关使用 JFR 的更多信息,请参阅 GraalVM JDK Flight Recorder (JFR) with Native Image 指南。
如何排查仅在生产环境中可重现的性能问题?
在这种情况下,首先尝试切换到 JVM 模式是最好的选择。如果在切换到 JVM 模式后性能问题仍然存在,您可以使用更成熟和稳定的工具来找出根本原因。如果性能问题仅限于原生模式,您可能无法使用 perf,因此 JFR 是在这种情况下收集任何信息的唯一方法。随着 JFR 对原生模式的支持不断扩展,直接在生产环境中检测性能问题根源的能力将会提高。
在构建时或运行时发生的问题,什么信息最有助于调试?
要修复构建时的类路径、类初始化或禁止的 API 错误,最好使用 构建时报告 来理解封闭的世界。对世界的完整了解,以及不同类和方法之间的关系,将有助于发现和修复大多数问题。
构建卡住数分钟,CPU 使用率很低
有时构建会卡住,甚至出现
Image generator watchdog detected no activity.一个可能的解释是熵不足,例如在熵受限的虚拟机上,如果需要熵源(如构建时的 Bouncycastle)。
可以在 Linux 系统上使用以下命令检查可用熵:
$ cat /proc/sys/kernel/random/entropy_avail如果数量不足百位,可能会有问题。一个可能的解决方法是妥协(对于测试来说是可以接受的),并设置
export JAVA_OPTS=-Djava.security.egd=/dev/urandom正确的解决方案是增加系统的熵。但这取决于每个操作系统供应商和虚拟化解决方案。
规避缺失的 CPU 功能
当在较新的机器上构建,并在较旧的机器上运行原生可执行文件时,您可能会在启动应用程序时看到以下失败:
The current machine does not support all of the following CPU features that are required by the image: [CX8, CMOV, FXSR, MMX, SSE, SSE2, SSE3, SSSE3, SSE4_1, SSE4_2, POPCNT, LZCNT, AVX, AVX2, BMI1, BMI2, FMA].
Please rebuild the executable with an appropriate setting of the -march option.此错误消息意味着原生编译使用了运行应用程序的 CPU 不支持的更高级的指令集。要解决此问题,请将以下行添加到 application.properties:
quarkus.native.march=compatibility然后,重新构建您的原生可执行文件。此设置会强制原生编译使用较旧的指令集,从而增加兼容性。
要显式定义目标架构,请运行 native-image -march=list 来获取支持的配置,然后将 -march 设置为其中之一,例如 quarkus.native.additional-build-args=-march=x86-64-v4。如果您针对的是 AMD64 主机,-march=x86-64-v2 在大多数情况下都可以正常工作。
march 参数仅在 GraalVM 23+ 上可用。 |
