MEF 和 Sofis 将 Quarkus 用作新型创新架构的核心组件

关于我们

乌拉圭经济和财政部(MEF)是一个政府部门。
网站:https://www.gub.uy/ministerio-economia-finanzas

Sofis Solutions 是一家在拉丁美洲组织的数字化转型和技术融合方面拥有超过 18 年经验的公司。主要专注于数字政府发展以及社会、环境和治理问题解决的项目。
网站:https://www.sofis.lat
问题陈述
乌拉圭经济和财政部目前的综合财务信息系统(SIIF)依赖于 Oracle Forms,这带来了一些缺点,例如兼容性有限、不灵活、维护成本高和支持有限。为了确保长期可行性和现代化,需要进行架构更新。主要目标是建立一个可扩展的参考架构,使 SIIF 能够作为现代化进程的一部分发展。2021 年底,成立了一个架构团队,并开始按照 TOGAF 架构开发方法 9.2 进行工作。
关键需求
这种现代化架构的关键需求是
-
必须可以审计对实体进行的事务和更改。
-
在运行时,软件系统应生成指标,以提供每个组件的运行状态的可见性。这些指标应可通过集中式监控平台访问,该平台应能够可视化当前状态并生成警报。
-
在正常的生产条件下,系统必须以小于一秒的延迟响应。
-
需要在办公时间内解决方案的每月可用性为 99%,办公时间外为 95%。
-
系统应能够通过利用横向扩展技术来处理不断增加的工作负载,例如添加新的用户组、更高的流量或更复杂的事务。服务必须作为 Docker 容器部署。
-
必须支持使用 REST(首选)和 SOAP(旧版)协议的系统间通信。
-
软件必须能够在单元、集成和系统范围内进行测试。
-
事务系统的中心数据存储库必须保持永久的数据完整性和一致性。尽管发生技术故障或其他组件崩溃,也必须确保这种一致性。
-
所有日志数据和异常都必须被正确捕获并集中管理。
-
正在开发的软件应该具有高度可配置性,以确保它可以部署在各种安装环境中,例如开发、测试、预生产、生产等,而无需为每个环境重新编译。
-
组件应易于与 Kafka 等分布式事件流平台集成。
-
使用的框架必须增强开发人员的体验。编码时的实时重新加载非常有价值。
-
编码必须与 Java EE 和 MicroProfile 生态系统保持一致。
-
组件必须提供一种机制,允许通过平台的健康监控器进行健康监控。
我们选择了 Quarkus 作为后端框架,因为它能够满足我们所有的关键需求。其广泛的功能、能力和活跃的社区正是我们所需要的,使其成为我们项目的重要工具。
架构
架构图是按照 C4 模型制作的。系统由使用宏服务方法实现的模块组成,这些模块大于微服务,但小于单体应用程序。系统概况的简化版本如下所示
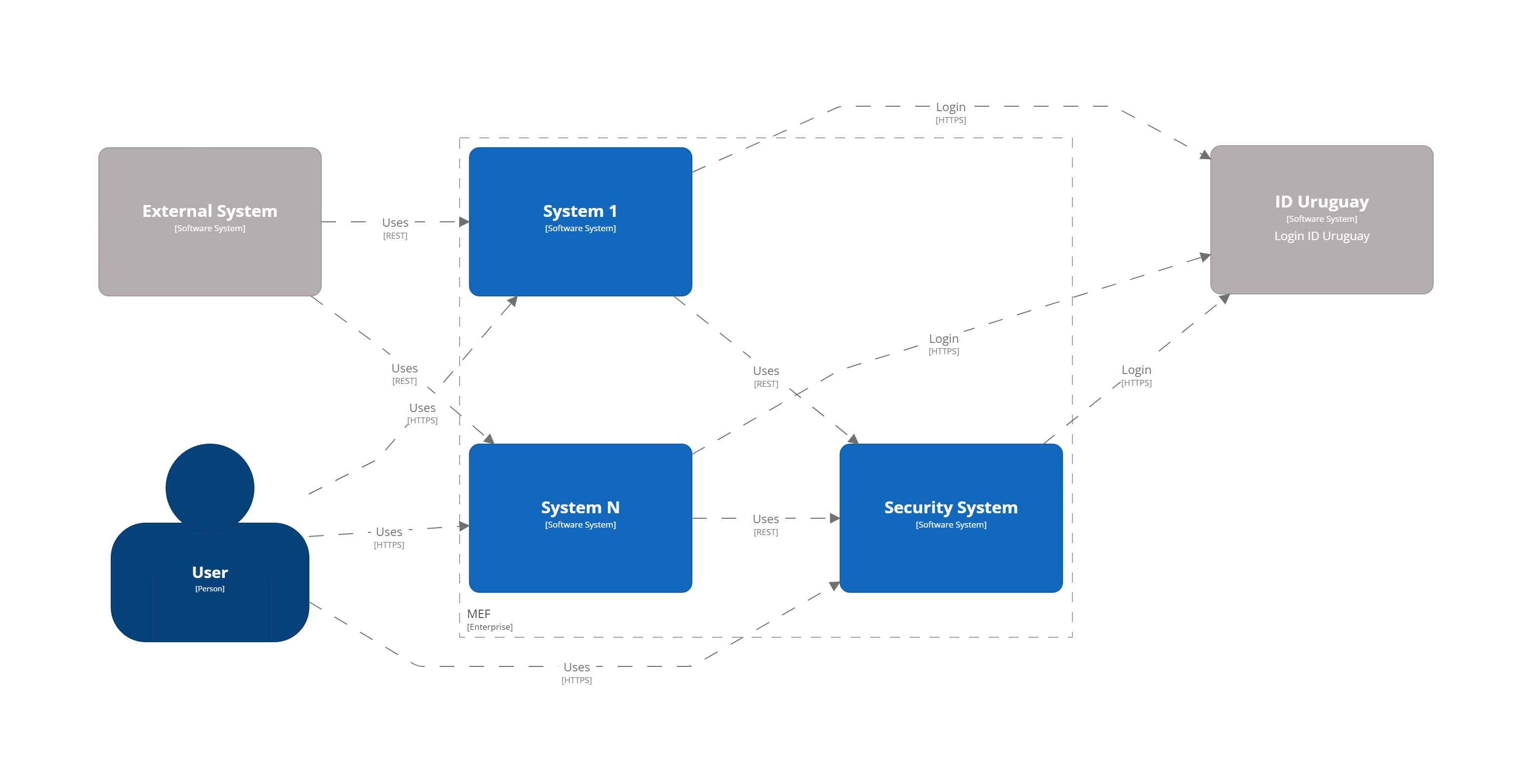
描述
-
系统 1 到 N。可以是 MEF 中使用的任何系统。
-
安全系统。用户、角色、操作、审计日志等的管理。
-
ID Uruguay。AGESIC 身份和身份验证提供程序。用户必须通过 MEF 应用程序启动针对此提供程序的 OAuth2 身份验证流程。
-
外部系统。表示使用 MEF API 的外部系统。
除了内部系统外,我们使用的一些最相关的工具是
-
Kubernetes。容器编排器。
-
Ceph。存储平台。
-
Elasticsearch、Fluentd、Kibana 技术栈。日志和审计数据的存储和可视化。
-
Prometheus、Alertmanager、Grafana 技术栈。基础设施和服务指标的可视化。还负责生成警报。
-
Matomo。用于获取用户分析及其在网站上的行为。
-
Apache Kafka。分布式事件流平台。
-
Apache APISIX API 网关。管理和公开 API。
-
ArgoCD。GitOps 持续交付工具。
-
GitLab。代码存储库和 CI/CD DevOps 工具。
-
Nexus。库和 Docker 镜像的存储库。
-
SonarQube。静态代码分析工具。
Kubernetes
Kubernetes 是一个开源容器编排系统,用于自动化软件部署、扩展和管理。Quarkus 和 Kubernetes 的结合为创建可扩展、快速和轻量级的应用程序提供了理想的环境。我们的应用程序和工具部署在两个用于生产和非生产环境的本地 Kubernetes 集群中。
ArgoCD 和 Kustomize
ArgoCD 是一个 Kubernetes 运算符,它利用 CRD(自定义资源定义)来配置其操作。这些 CRD 允许通过 Git 存储的文件定义基础设施,并自动执行部署,跟踪所做的任何更改。
Kustomize 通过利用 Kubernetes 对象来定义配置文件并以声明方式管理这些配置来遵守 Kubernetes 原则。 Kustomization 对象定义了如何生成或转换其他 Kubernetes 对象,并在名为 kustomization.yaml 的文件中创建,Kustomize 本身可以编辑该文件。可以使用覆盖修补 Kustomization 以覆盖基本设置并创建变体。 ArgoCD 提供无缝的 Kustomize 支持,从而可以更高效、有效地管理 Kubernetes 配置。
Ceph
Ceph 是一个开源软件定义存储平台,它在单个分布式计算机集群上实现对象存储,并为对象、块和文件级存储提供 3 合 1 接口。我们有两个与我们的 Kubernetes 集群集成的本地集群(生产和非生产)。
CI/CD
我们目前正在使用主要基于 成功的 Git 分支模型 的自定义 CI/CD 流程。所有 CI/CD 任务都是使用 GitLab 实现的。
我们尽可能遵循“一次构建,随处部署”的方法。代码是使用 s2i(源代码到镜像)构建的,镜像通过不同的环境(开发、集成、测试/QA、培训、预生产和生产)传播。
我们的开发类型要求我们每个项目有 3 个唯一的长期分支
-
Main。所有开发人员持续合并其新功能的地方。
-
Release。当 main 中的代码准备好发布到 QA 时,它会被合并到 release 分支。应用错误修复时,Release 可以独立于 main 发展。
-
Production。代码发布到生产环境的地方。从中创建 Hotfixes 分支。
指标
Prometheus-Grafana 组合已成为云原生领域中最受欢迎的监控、警报和可视化解决方案之一。 Prometheus 是一个开源系统监控和警报工具包。 Grafana 是一个多平台开源分析和交互式可视化 Web 应用程序。它提供开箱即用的支持来显示 Prometheus 收集的数据。
有了它们,我们可以收集、可视化和响应来自 Kubernetes、CephFS、Apache APISIX、Elasticsearch、Kafka、Zookeeper、数据库、后端、前端等的指标。
要开始使用 Quarkus 公开指标,必须添加 quarkus-micrometer-registry-prometheus 扩展。这使我们能够获得有关我们的应用程序的有趣指标,例如 CPU、堆、非堆、http 请求等。使用公开的默认 HTTP 指标,我们能够按方法获得以下见解
-
请求总数
-
最长请求持续时间
-
平均请求持续时间
-
每个请求的持续时间总和
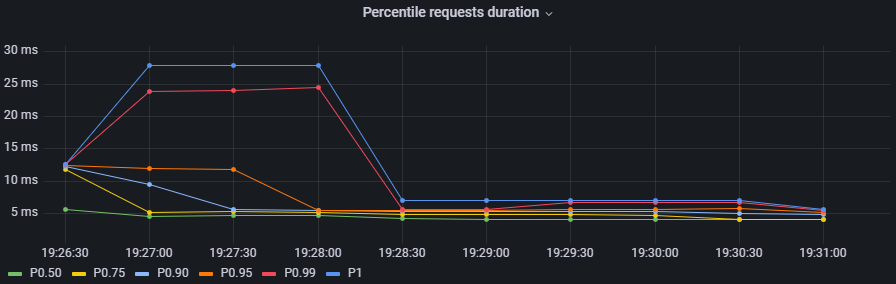
要确定最长请求持续时间是孤立的情况还是发生在许多请求中,必须使用百分位数。
百分位数
百分位数是统计学中使用的一种度量,指示一组观察值中给定百分比的观察值下降到的值。例如,响应时间值低于其 90% 的 HTTP 请求的响应时间称为 90 百分位数响应时间。计算百分位数的推荐方法是使用“百分位数直方图”方法。请参阅 https://micrometer.io/docs/concepts#_histograms_and_percentiles。 Quarkus(和 Micrometer)允许您通过定义 @Singleton MeterFilterProducer 来启用此类指标。以下是示例代码
@Singleton
public class MeterFilterProducer {
@Inject
@ConfigProperty(name = "app.enable-percentiles-histogram", defaultValue = "true")
Boolean enablePercentilesHistogram;
@Produces
@Singleton
public MeterFilter percentilesHistogram() {
return new MeterFilter() {
@Override
public DistributionStatisticConfig configure(Meter.Id id, DistributionStatisticConfig config) {
return BooleanUtils.isTrue(enablePercentilesHistogram)
? DistributionStatisticConfig.builder()
.percentilesHistogram(true)
.build()
.merge(config)
: config;
}
};
}
}有了这些新的公开指标,我们可以定义,例如
-
Prometheus 中的警报,当第 95 百分位数的请求持续时间超过 300 毫秒时会触发。
histogram_quantile(0.95, sum(rate(http_server_requests_seconds_bucket[2m])) by (service, namespace, uri, method, le)) > 0.3 -
Grafana 中的交互式图表,以显示一些所需的百分位数,如 50、75、90、95、99 和 1
histogram_quantile(0.90, sum(rate(http_server_requests_seconds_bucket{service="$application", namespace="$namespace", uri=~"$percentiles_uri", method=~"$percentiles_method"}[2m])) by (le))
身份验证和授权
我们的 API 安全是使用 Json Web Tokens 实现的。我们有一个集中的身份验证服务来生成 JWT,用户和应用程序使用这些 JWT 来使用公开的 API。每个后端都可以访问公钥,并且可以自行验证签名。为了保护端点,使用了 @RolesAllowed 注解。除此之外,还必须添加 quarkus-security 扩展。
您可能已经熟悉 JSON Web Tokens (JWT) 中的“groups”属性,该属性通常映射到许多 jwt-security 验证库中的 @RolesAllowed 属性。但是,这种方法假定角色需要硬编码,这可能并不总是合适的。在我们的例子中,我们希望端点上的安全性是面向操作的,以便用户可以拥有动态角色,具有不同的操作。为了实现这一点
-
每个端点都必须映射到单个操作。
-
需要在 JWT 组和操作之间进行映射。在 JWT 的 groups 属性中存储操作并不理想,因为数组可能很大,导致令牌很大。
我们决定使用 ContainerRequestFilter 实现 JWT 验证,如 https://quarkus.net.cn/guides/security-customization#jaxrs-security-context 中所述。在该过滤器中,获取 JWT 组并调用带有 @CacheResult 的缓存方法以获取相关操作。截至今天,为了简单起见,我们使用的是带有 Caffeine 的内存缓存,但 Quarkus 3 中引入的新的 Redis 作为缓存后端似乎是一个不错的选择,因为我们可以在所有实例之间共享缓存。请参阅 https://quarkus.net.cn/guides/cache-redis-reference。
SecurityContext isUserInRole 方法被覆盖为
@Override
public boolean isUserInRole(String o) {
return user != null ? user.getOperations().contains(o) : false;
}审计请求
一个常见的需求是审计对我们的 API 发出的请求。决定
-
将其作为数据流存储在 Elasticsearch 中。
-
异步存储它,而不干扰请求。
-
始终审计 POST、PUT、PATCH 和 DELETE 方法。在少数特殊情况下,也审计 GET 方法。
我们希望审计的参数包括服务、requestDate、responseDate、方法、baseUri、path、queryParams、userId、ip、traceId、traceApplicationChain、responseStatus、requestBody(可选)和 responseBody(可选)。
为此,我们实现了一些实用程序类
-
一个
ContainerRequestFilter,用于获取一些参数,例如请求开始日期,并通过ContainerRequestContext传播它们。 -
一个
ContainerResponseFilter,用于获取其余参数并调用负责将审计事件发送到 Kafka 主题的方法。我们决定仅在响应过滤器中发送事件,这是出于性能原因,假设如果未调用,则可能只会发生最小的损失。 -
一个
@AuditedEndpoint注解,用于标识和自定义我们要审计的方法。未注解的 API 方法会被过滤器忽略。此注解有两个可以在方法级别自定义的布尔参数:auditRequestBody(默认为 true)和auditResponseBody(默认为 false)。
可以使用 Emitter 发送强制性事件到 Kafka(请参阅 https://quarkus.net.cn/guides/kafka#sending-messages-with-emitter)。必须添加 quarkus-smallrye-reactive-messaging-kafka 扩展。
在我们有了主题中的事件后,我们需要一种方法来处理它们并将它们存储在 Elasticsearch 中。为了执行此任务,我们使用了部署在 Kafka Connect 中的 Elasticsearch Service Sink Connector。 Kafka Connect 是一种在 Apache Kafka 和其他数据系统之间可扩展且可靠地流式传输数据的工具。它可以简单地快速定义连接器,以将大量数据集移入和移出 Kafka。请参阅 https://docs.confluent.io/platform/current/connect/index.html。
| 此外,我们还采用了 Hibernate Envers 用于面向实体的审计。 |
| 除了审计事件处理之外,Kafka 将用作用于具有独立数据库的服务(和系统)之间通信的机制。 |
数据库模式和迁移
我们有多个环境,例如开发、集成、测试/QA、培训、预生产和生产。有必要在将服务部署到不同环境时自动执行脚本。 Flyway 是一款很棒的工具,可以实现这一点。它允许您
-
从头开始重新创建数据库。
-
始终明确数据库处于什么状态。
-
以确定的方式从当前版本的数据库迁移到较新版本。
需要 quarkus-flyway 扩展。在运行测试或部署服务时,迁移功能将启动以应用必要的脚本。
我们的自定义案例 (1)
我们的系统类型要求有服务组共享一个数据库(请参阅 https://microservices.io/patterns/data/shared-database.html)。此外,在某些情况下,存在旧版数据库。从头开始使用新的迁移重新创建完整的结构是一项艰巨的任务。
决策和影响
-
对于旧版数据库,应使用当前状态创建 Flyway“基线”,并在该点之后应用迁移。
-
每个服务在数据库中都有自己的模式,并负责其演变。每个模式都需要一个
flyway_schema_history表。 -
在某些情况下,模式 A 中的表可以具有指向模式 B 的外键。因此,一个服务可能需要来自另一个服务的结构才能正确运行。这强制要求模式 B 的服务所有者必须在模式 A 的所有者之前发布。作为通用规则,我们尽可能避免在 A 和 B 之间具有双向外键。
-
自动化测试必须针对具有所有结构的现有数据库运行。单个后端无法重新创建整个数据库。请参阅 [自动化测试 / 代码分析]。
请注意,在使用某些数据库(如 Oracle 或 MySQL)时,失败的 DDL 迁移不会自动回滚。请参阅 https://flywaydb.org/documentation/learnmore/faq#rollback。我们找到了两种缓解这种情况的方法
-
在
quarkus.flyway.clean-on-validation-error=true的环境中运行测试。这允许在发布到另一个环境之前测试所有迁移。在不共享数据库的新服务中最为有用。 -
按功能创建独立的迁移。在这种情况下,迁移应该很小,并且更容易回滚。为避免同一版本的迁移之间发生名称冲突,可以使用名称中的时间戳和
quarkus.flyway.out-of-order=true。
我们的自定义案例 (2)
所有系统的用户、角色、操作的管理都在具有自己数据库的一个横向安全管理系统中处理。当后端公开新的 API 时,它定义了一个新的操作和一个 @RolesAllowed 注解。如果需要,它可能还需要创建新角色。这些新数据必须在安全系统数据库中持久化/更新。我们需要触发此类更新作为服务 CI/CD 流程的一部分。为了解决这种情况,服务需要两个迁移文件夹:db/migration(用于服务模式)和 db/migrationsecurity(用于安全数据库)。在安全数据库中,每个服务都有自己的“flyway_schema_history”表,以记录执行的迁移。例如“fsh_service_A”、“fsh_service_B”等。
我们如何做到这一点?默认的 db/migration 文件夹由 Quarkus 在运行测试或部署时处理。另一方面,db/migrationsecurity 由在将应用程序部署到任何环境之前运行的 GitLab 作业拾取。由于安全数据库在环境中的所有服务之间共享,因此 Flyway 配置可以以统一的方式声明为 GitLab CI/CD 变量。另一个也可能有效的方法是使用 quarkus.flyway."named-data-sources" 属性,该属性允许您在不同的数据源中应用迁移。
自动化测试和代码分析
要实现自动化测试,需要 quarkus-junit5 扩展。如上所述,我们的自动化测试必须针对具有所有必要结构的现有数据库运行。因此,我们无法从头开始设置测试数据库,例如使用 TestContainers。我们还需要一种回滚测试引入的更改的方法。感谢 Quarkus 提供的 @TestTransaction 注解,后者非常容易实现(请参阅 https://quarkus.net.cn/guides/getting-started-testing#tests-and-transactions)。事务性测试非常有用,因为它允许我们针对真实数据库运行测试,而无需模拟。除了测试方法的逻辑之外,它还保证实体和表已正确定义。
关于代码分析,我们正在使用两个 Maven 插件:sonar-maven-plugin 和 dependency-check-maven。 SonarQube 是 SonarSource 开发的开源平台,用于持续检查代码质量,以通过代码的静态分析执行自动审查,以检测错误和代码异味。 Dependency-Check 是一种软件组成分析工具,它尝试检测项目中依赖项中包含的公开披露的漏洞。可以在 SonarQube 中安装一个插件以与依赖项检查报告集成。
quarkus-jacoco 扩展也用于获取测试的覆盖率。生成的报告由 SonarQube 拾取,结果用于检查质量门。
代码分析工具可能需要一些时间。因此,我们决定仅在 GitLab 调度程序触发的夜间构建中运行此任务。此决定取决于每个项目的要求。
依赖项机器人
我们生活在一个持续交付代码的时代,Quarkus 也不例外。该团队正在以快速的步伐发布包含改进和错误修复的新版本。除此之外,我们还制作了一些实用程序库,这些库在我们的后端和前端之间共享。有新版本时,应更新所有服务。
截至今天(初始阶段),我们有大约 30 个服务,但在不久的将来预计会有更多服务。拥有一个依赖项机器人来帮助我们更新这些依赖项并运行自动验证任务是必须的。
由于我们正在使用 GitLab,因此推荐的选项之一是 Renovatebot。请参阅 https://docs.renovatebot.com/。它相对容易设置,可以与 Java 无缝协作,并且具有高度可定制性。
安全域和 DAO 库
作为项目的一部分,我们必须编写一个实用程序 JPA DAO 库,以简化开发人员发出的查询。因此,“jpacriteria-dao”库诞生了。在底层,它使用 JPA criteria 库。
主要目标是
-
简化查询的创建。开发人员只需要编写 DTO 过滤器并将属性映射到 criteria 谓词。该库创建最终查询。它会自动检测何时执行内部/左连接,何时使用 distinct 等。
-
支持将
includeFields与导航一起使用,因此开发人员可以选择要查询的字段 (field1.field2.id,field1.field2.name, 等)。执行本机查询并将结果映射到 DTO。限制查询范围非常有用。 -
在我们的系统中,我们有具有优先级的安全域。有些用户只能看到属于其域的数据。该库在收到指令时可以在 DAO 级别自动执行验证和过滤。需要支持它的实体必须扩展
DataSecurity接口。
我们决定将其开源,并且可能还会将其部署到 Maven Central。该代码发布在 https://github.com/sofisslat/jpacriteria-dao GitHub 存储库中。我们还上传了一个使用该库的示例 Quarkus 应用程序(在 example 文件夹下)。截至今天,我们将该库视为概念验证,可以对其进行演进和改进。
日志 (EFK)
在 Kubernetes 集群上运行多个服务和应用程序时,集中式集群级别日志记录堆栈可以帮助快速排序和分析 pod 产生的大量日志数据。一种流行的集中式日志记录解决方案是 Elasticsearch、Fluentd 和 Kibana (EFK) 堆栈。数据流是建议的在 Elasticsearch 中存储日志的方式。在典型的设置中,所有日志都具有有用的上下文信息,用于过滤为“命名空间”、“服务”、“日志级别”等。
挑战在于向记录的信息添加尽可能多的上下文,例如
-
traceId(链接对应于调用跟踪的日志)
-
tokenId(链接对应于 JWT 授权令牌的日志)
-
userId/userCode(链接对应于给定用户的日志)
此附加信息有助于我们的开发团队调试用户报告的错误。
JSON 日志记录格式
可以更改控制台日志的输出格式。这在 Quarkus 应用程序的输出被捕获的服务捕获并在以后分析时处理和存储日志信息的环境中可能很有用。为了配置 JSON 日志记录格式,可以使用 quarkus-logging-json 扩展。请参阅 https://quarkus.net.cn/guides/logging#json-logging。
在我们的例子中,这使我们能够在 JSON 日志输出中添加一些额外的参数,这些参数很容易被 fluentd 拾取并发送到 Elasticsearch。
quarkus.log.console.json.exception-output-type=formatted 属性也用于发送堆栈跟踪。
| Docker 的日志大小限制为 16K(kubernetes/kubernetes#52444 和 moby/moby#34620)。具有较大堆栈跟踪的错误将生成拆分日志。提议的 fluentd 社区解决方案是使用 fluent-plugin-concat。请记住,在旋转文件日志时可能存在边缘情况。另一个解决方案是如 https://quarkus.net.cn/guides/centralized-log-management 中提到的那样直接发送日志。 |
