使用 Quarkus 和 Eclipse MicroProfile 构建 Kafka Streams 应用程序

Kafka Streams 是基于 Apache Kafka 实现流处理应用程序的一个非常流行的解决方案。它允许你执行典型的数据流任务,如过滤和转换消息、连接多个 Kafka 主题、执行(有状态)计算、在时间窗口中对值进行分组和聚合,以及更多功能。
与其他运行在特定处理集群上的流式查询引擎不同,Kafka Streams 是一个客户端库。这意味着需要一个(Java)应用程序来启动和运行流处理管道,从 Apache Kafka 集群读取数据并写入数据。
在这篇博文中,我们将讨论 Quarkus 和 Eclipse MicroProfile 的组合如何成为实现 Kafka Streams 应用程序的绝佳基础,该应用程序运行在 JVM 上,并通过 GraalVM 提前编译成本地代码。
Kafka Streams 的 Quarkus 扩展
从 0.17.0 版本开始,Quarkus 提供了用于构建 Kafka Streams 应用程序的扩展。要创建带有此扩展的新 Quarkus 项目,请运行以下命令
mvn io.quarkus:quarkus-maven-plugin:0.17.0:create \
-DprojectGroupId=org.acme \
-DprojectArtifactId=kafka-streams-quickstart-example \
-Dextensions="kafka-streams"这将设置一个新项目,添加 Quarkus Kafka Streams 扩展的依赖项,该依赖项又会拉入 Kafka Streams 及其所有依赖项。
如果你以前使用过 Kafka Streams,数据流处理管道的实现对你来说会非常熟悉。你首先构建一个 Topology,然后创建一个 KafkaStreams 实例。对于后者的启动和停止,Quarkus 的 StartupEvent 和 ShutdownEvent 类非常有用。
总的来说,在 Quarkus 上运行的 Kafka Streams 管道的结构如下所示:
@ApplicationScoped
public class MyStreamingPipeline {
private KafkaStreams streams;
void onStart(@Observes StartupEvent event) {
// set up Kafka Streams config, e.g. sourced from application.properties
Properties props = new Properties();
// props.put(..., ...);
// set up the stream topology
StreamsBuilder builder = new StreamsBuilder();
// builder.stream(...)
streams = new KafkaStreams(builder.build(), props);
streams.start();
}
void onStop(@Observes ShutdownEvent event) {
streams.close();
}
}对于将流处理管道中使用的 Java 类型序列化/反序列化为/从 JSON(例如,在状态存储中具体化它们时)这一非常普遍的要求,Quarkus Kafka Streams 扩展提供了 io.quarkus.kafka.client.serialization.JsonbSerde 类。这是一个基于 JSON-B 的 Serde 实现。
...
JsonbSerde<WeatherStation> weatherStationSerde = new JsonbSerde<>(WeatherStation.class);
GlobalKTable<Integer, WeatherStation> stations = builder.globalTable(
"weather-stations",
Consumed.with(Serdes.Integer(), weatherStationSerde)
);
...原生运行
基于 Kafka 的主题分区概念,Kafka Streams 应用程序可以轻松地扩展:负载将在多个应用程序实例之间共享,每个实例只处理输入主题的部分分区。
通过 GraalVM 以本地代码运行 Quarkus 应用程序在这方面非常有用:除了非常快的启动时间外,编译成本地代码后,应用程序将显著减少内存使用。这使你能够以非常内存高效的方式并行启动许多基于 Quarkus 的 Kafka Streams 管道实例。
该扩展负责构建本地 Kafka Streams 应用程序所需的一切,例如,它确保将正确的 RocksDB 本地库添加到应用程序映像中。你所需要做的就是为 Quarkus Maven 插件指定 enableJni 选项,允许通过 JNI 调用这些本地库。
<plugin>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-maven-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>native-image</goal>
</goals>
<configuration>
<enableJni>true</enableJni>
</configuration>
</execution>
</executions>
</plugin>当使用 JsonbSerde 将 JSON 解组为相应的 Java 对象时,这些类型必须用 @RegisterForReflection 注解标记,以便在本地模式下可以通过 JSON-B 反射实例化它们。
@RegisterForReflection
public class WeatherStation {
public int id;
public String name;
}然后使用 native 配置文件构建应用程序(请注意,这需要你的系统上安装了 GraalVM;有关更多信息,请参阅 Quarkus 的本地映像指南)。
mvn clean package -f aggregator/pom.xml -Pnative找到运行应用程序所需的正确内存量可能需要一些测试。例如,观察 CPU 负载并使用 -XX:+PrintGC -XX:+PrintGCTimeStamps -XX:+VerboseGC 选项运行本地二进制文件,以深入了解垃圾回收的发生频率。如果你启动应用程序时堆空间不足,通常会观察到 GC 发生得非常频繁,导致 CPU 负载增加。
例如,对于 Kafka Streams 扩展指南中讨论的流处理管道,32 MB 的堆大小(-Xmx32m)效果很好,导致进程总共只需要不到 50 MB 的内存(RSS,驻留集大小)。请注意,这个数字还包括该示例中定义的用于通过 REST 进行交互式查询的 HTTP 端点所需的内存。
运行状况检查
然后,创建运行状况检查就像在管道实现中添加以下内容一样简单:
@Liveness
@ApplicationScoped
public class MyStreamingPipeline implements HealthCheck {
private KafkaStreams streams;
// ...
@Override
public HealthCheckResponse call() {
return HealthCheckResponse.named("My Pipeline")
.state(streams.state().isRunning())
.build();
}
}这将通过 HTTP 在 /health/live 下公开一个运行状况检查,查询时会产生如下响应:
HTTP/1.1 200 OK
Connection: keep-alive
Content-Length: 144
Content-Type: application/json;charset=UTF-8
Date: Wed, 26 Jun 2019 10:08:36 GMT
{
"checks": [
{
"name": "My Pipeline",
"status": "UP"
}
],
"status": "UP"
}当使用 Kubernetes 等容器编排器时,你可以为该端点设置存活探针。如果运行状况检查失败(即流处理管道未处于运行状态),它将返回 HTTP 503 响应。这将指示编排器重新启动此应用程序的 pod。
指标
虽然运行状况检查提供了简单的方法来确定应用程序是否处于可以处理请求/消息的状态,但最好能更深入地了解服务的行为。例如,查看流处理管道处理了多少消息、消息的到达速率、平均处理时间以及更多内容会很有趣。
Kafka Streams 具有丰富的指标功能,可以帮助回答这些问题。使用 MicroProfile Metrics API,可以通过 HTTP 公开这些指标。然后,它们可以被 Prometheus 等工具抓取,并最终馈送到 Grafana 等仪表板解决方案。请注意,通过 HTTP 而不是 JMX 公开指标的好处是,在通过 GraalVM 以本地模式运行应用程序时,这也有效。
与运行状况检查类似,只需少量粘合代码即可公开指标:
@ApplicationScoped
public class MyStreamingPipeline {
@Inject
MetricRegistry metricRegistry;
private KafkaStreams streams;
void onStart(@Observes StartupEvent event) {
// ...
streams.start();
exportMetrics();
}
// ...
private void exportMetrics() {
Set<String> processed = new HashSet<>();
for (Metric metric : streams.metrics().values()) { (1)
String name = metric.metricName().group() +
":" + metric.metricName().name();
if (processed.contains(name)) {
continue;
}
// string-typed metric not supported
if (name.contentEquals("app-info:commit-id") || (2)
name.contentEquals("app-info:version")) {
continue;
}
else if (name.endsWith("count") || name.endsWith("total")) { (3)
registerCounter(metric, name);
}
else {
registerGauge(metric, name); (4)
}
processed.add(name);
}
}
private void registerGauge(Metric metric, String name) {
Metadata metadata = new Metadata(name, MetricType.GAUGE);
metadata.setDescription(metric.metricName().description());
metricRegistry.register(metadata, new Gauge<Double>() {
@Override
public Double getValue() {
return (Double) metric.metricValue();
}
} );
}
private void registerCounter(Metric metric, String name) {
// ...
}
}| 1 | 处理所有 Kafka Streams 指标,并使用唯一名称进行注册 |
| 2 | 必须排除一些字符串类型的“指标” |
| 3 | 所有以“total”或“counter”结尾的指标都将作为计数器类型的指标公开 |
| 4 | 所有其他指标将作为 gauge 类型(即纯数值)的指标公开 |
应用程序启动后,指标将在 /metrics 下公开,默认以 OpenMetrics 格式返回数据。
# HELP application:stream_metrics_process_total The total number of occurrence of process operations.
# TYPE application:stream_metrics_process_total counter
application:stream_metrics_process_total 2866.0
# HELP application:stream_metrics_poll_latency_avg The average latency of poll operation.
# TYPE application:stream_metrics_poll_latency_avg gauge
application:stream_metrics_poll_latency_avg 83.3135593220339
# ...只需几分钟即可设置 Prometheus 来抓取此目标,在 Grafana 中配置 Prometheus 数据源,并配置仪表板来可视化您感兴趣的指标。例如,下图显示了一个简单的仪表板,用于显示 quickstart 示例中的 poll/process/commit 速率和延迟以及处理过的事件总数。
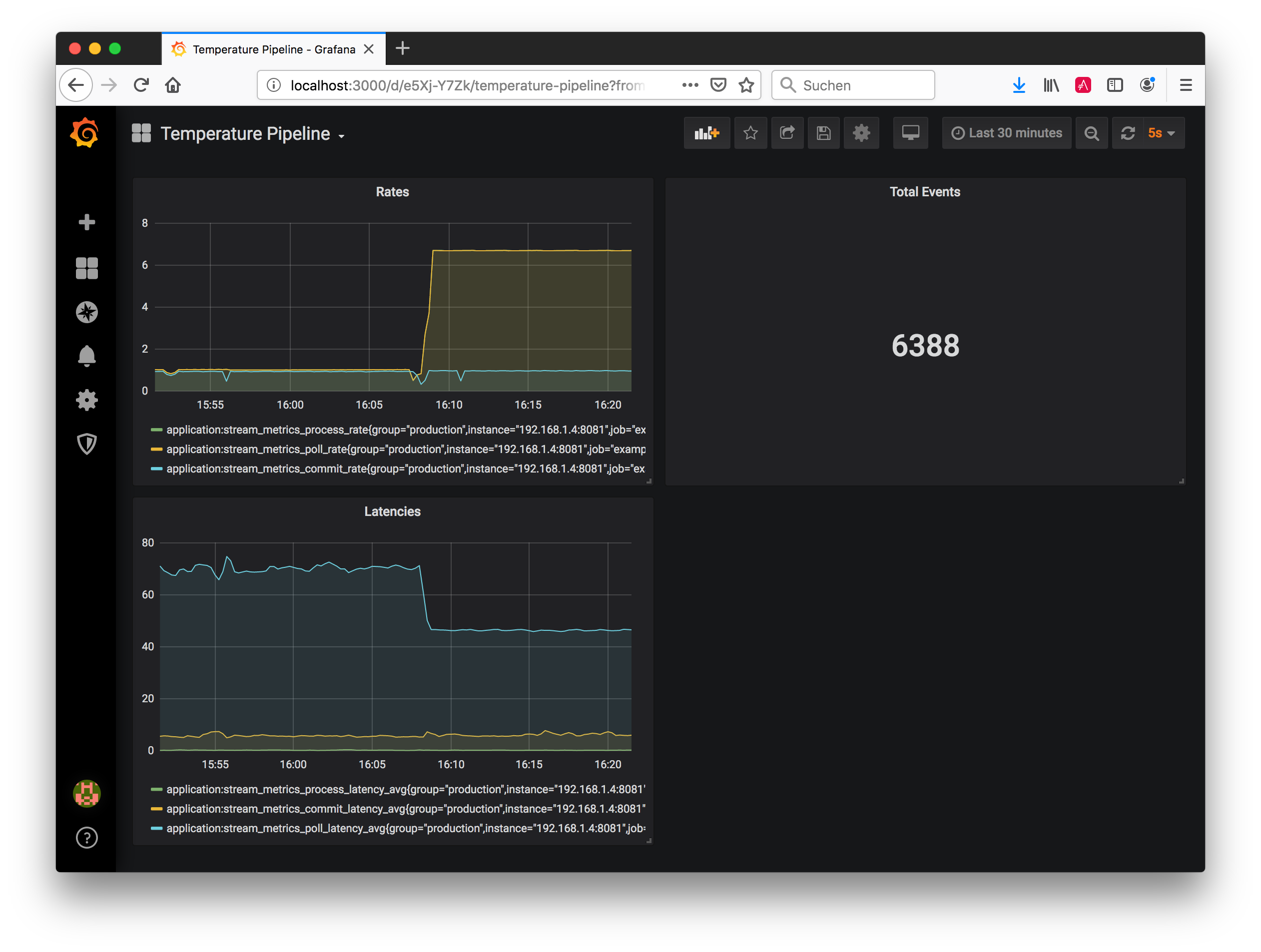
总结和展望
Quarkus 和 Eclipse MicroProfile 是构建 Kafka Streams 应用程序的绝佳基础。Kafka Streams 的 Quarkus 扩展提供了在 JVM 和 GraalVM 的本地模式下运行流处理管道所需的一切。用于运行状况检查和指标的 MicroProfile API 可用于公开必要的信息,以深入了解运行中的流处理应用程序。
展望未来,我们计划进一步减少在 Quarkus 上构建 Kafka Streams 应用程序所需的努力。您将不必处理管道的生命周期,只需声明一个返回流式 Topology 的 CDI producer 方法即可。
@Produces
public Topology buildTopology() {
// set up the stream topology
StreamsBuilder builder = new StreamsBuilder();
// builder.stream(...)
return builder.build();
}这意味着您可以专注于实现实际的管道逻辑,而 Quarkus 扩展将负责其他所有事情:根据 Quarkus application.properties 文件配置 Kafka Streams,启动管道,并自动公开运行状况检查和指标。
如果您对此感兴趣,请关注下一个 Quarkus 版本公告,因为此改进功能即将推出。如果您有任何相关想法,请告知我们,并加入 Quarkus issue #2863 的讨论。
要详细了解 Quarkus Kafka Streams 扩展及其当前功能,请查看详细指南。它不仅讨论了实际的流处理管道实现,还涉及构建(分布式)交互式查询,通过 REST 公开当前的处理状态。
