巴西银行使用 Quarkus 和 Kafka 提取开放银行投资数据


巴西银行股份有限公司 (Banco do Brasil S.A.) 是一家巴西金融服务公司,总部位于巴西利亚。它是巴西历史最悠久的银行,也是世界上持续运营时间最长的银行之一,由葡萄牙国王约翰六世于 1808 年创立。它是巴西第二大银行机构,也是拉丁美洲第二大银行机构,以及世界第七十七大银行。巴西银行由巴西政府控制,并在圣保罗 B3 证券交易所上市。[1]

挑战
巴西银行有一个投资组合应用程序,其中所有客户的投资都集中在一起。这有助于我们的金融专家提供建议,也让客户在一个地方看到他们的所有投资。这些信息每天都会存储,因此可以创建图表,显示客户投资随时间的变化情况。
随着巴西开放银行的创建,现在可以从其他金融机构检索我们客户的投资数据。
根据巴西中央银行的说法
巴西中央银行 (BCB) 和国家货币委员会 (CMN) 将巴西开放银行环境定义为受监管实体(金融机构、支付机构和 BCB 许可的其他实体)之间的数据、产品和服务的共享,由客户自行决定,只要涉及他们自己的数据(个人或法人)。[2]
业务领导者设想有机会通过将来自其他金融机构的所有投资整合到我们全新的强大投资组合解决方案中来改善客户体验。
任务是以两种不同的方式提取此数据
-
每日 - 每个工作日。
-
按需 - 当金融专家或客户直接请求数据时。
从开放银行提取数据的技术挑战
遗留应用程序架构
遗留投资组合后端在大型机环境中运行,带有 COBOL 程序、JCL 过程和 DB2 数据库。
每天,此应用程序都会收到来自我们银行其他内部系统(如投资基金、账户和股票)的大量包含投资数据的文件。
重要的是要认识到大型机环境在这种大规模处理中表现出色,读取大量数据文件并使用不执行单个 SQL 的专用流程将数据存储在数据库中。这意味着我们可以生成一个包含数百万条记录的文件,并执行一个 DB2 过程,可以非常快速地存储所有这些数据。
解决问题的架构
新选择
巴西银行技术现在拥有一个由 Kubernetes 协调的私有云,我们可以在其中运行所有可以在容器中构建的东西。最常用的语言是 Java、TypeScript、Python 和 Go。
Quarkus 被我们的开发支持团队选为官方 Java 框架。主要原因是
-
非常好的开发体验,启动时间快,实时重新加载。
-
Quarkus 实现了 Eclipse MicroProfile 规范,这意味着我们不会被锁定在某个特定解决方案中,因此从理论上讲,如果需要,我们可以更改为另一个 MicroProfile 实现。
-
Quarkus 社区非常活跃,错误可以快速解决,并且经常发布新功能。
-
Quarkus 是云原生。
因此,Quarkus 被我们大量用于创建微服务。我们有各种各样的应用程序使用它,最常见的是简单的 API CRUD,但我们也有批处理、与使用 REST API 的其他机构集成、与巴西证券交易所 B3 集成(使用 FIX(金融信息交换)协议)、低延迟应用程序等等。
| 为了与 FIX 协议集成,我们使用 QuickFIX/J,这是一个 Java 开源解决方案。我们创建了这个 Fix Trading Simulator 项目,展示了如何将 QuickFIX/J 与 Quarkus 结合使用。 |
我们的决定
我们公司创建了一个新系统,用于与其他参与巴西开放银行环境的金融机构集成。它是我们的 开放银行集成器,它使用 Quarkus 构建。
在这一点上,我们需要决定如何克服所有项目挑战。我们是坚持使用大型机,在那里可以与我们的 开放银行集成器 通信,还是应该尝试一些新的东西?
与软件架构中的所有决策一样,我们总是有优点和缺点。最后,我们决定在我们的私有云中运行用 Quarkus 编写的微服务来解决这个问题。主要原因是
-
更容易水平扩展流程。
-
增加暴露指标的可能性,从而实现良好的可观察性。
-
容错控制,特别是超时、断路器、舱壁和重试。
-
与 Kafka 的良好集成。
新架构
我们决定创建四个微服务来处理这些问题
-
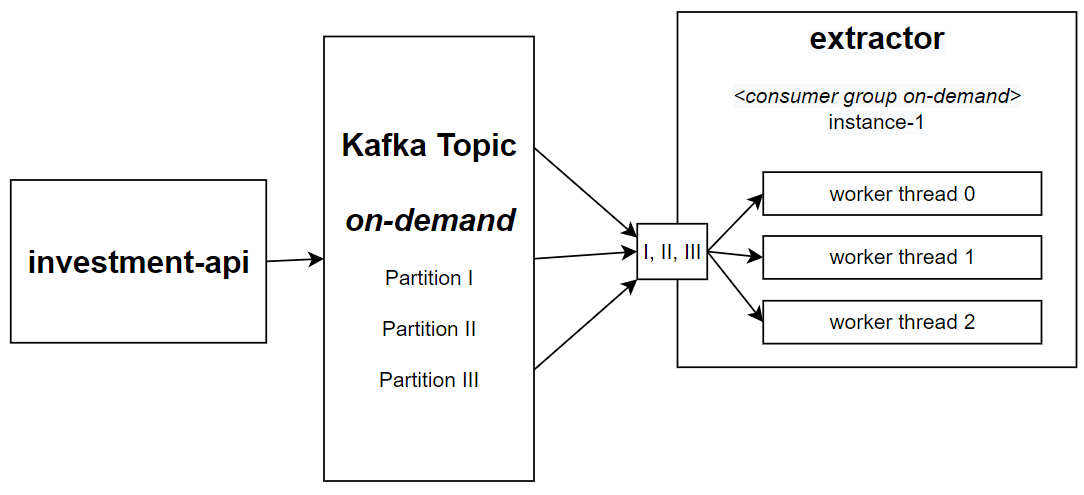
Investment-api - 负责在前端应用程序和开放银行投资数据之间创建异步通信层。当信息已经是最新的并且可用时,它会立即从 REST API 响应 200(正常),但当信息不是最新的时,它会响应 202(已接受),然后向 按需 主题发送一条消息,该消息将由 提取器 微服务处理。
-
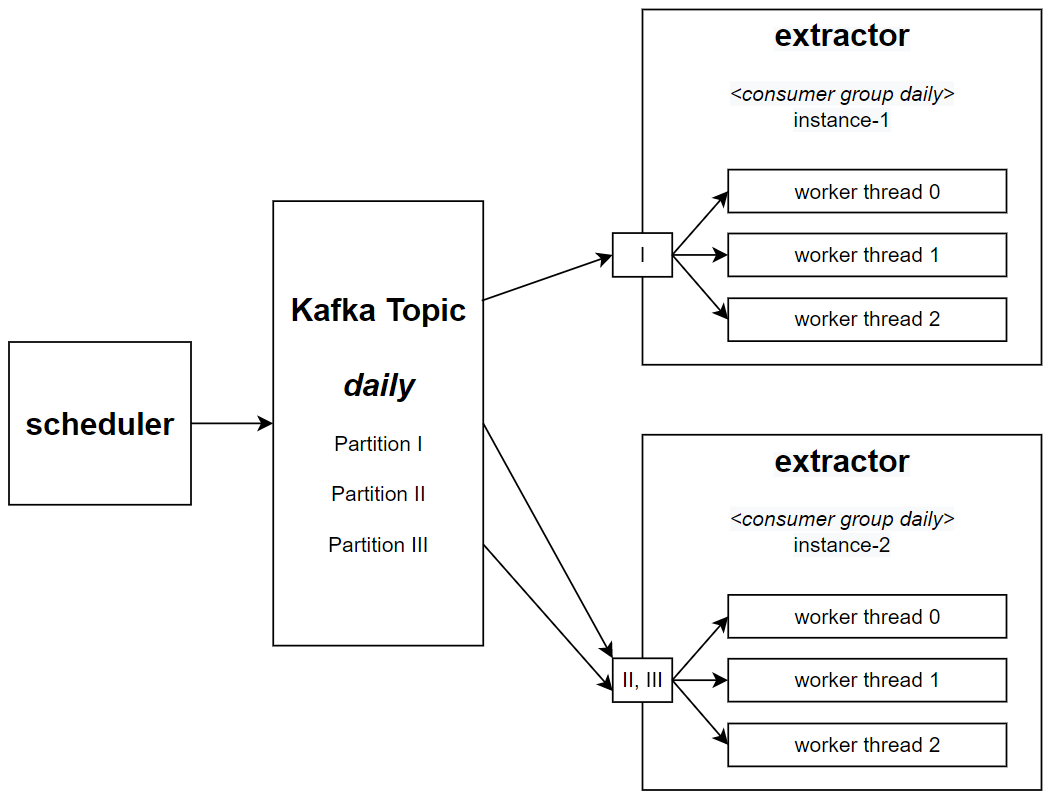
Scheduler - 负责控制日常流程。访问 开放银行集成器 数据库以检索所有在开放银行上共享投资数据的客户,并使用 每日 主题向 提取器 微服务发送每位客户一条消息。
-
Extractor - 该系统的核心。它接收来自 按需 和 每日 主题的消息。访问 开放银行集成器 系统并存储数据。
-
Monitoring - 使用 Prometheus 从上述微服务收集指标,使用 Grafana 的仪表板提供可观察性,并在出现问题时发送警报。
Quarkus 在项目中帮助我们
在一个实例中同时处理 Kafka 消息
提取器 微服务部署了两种不同的配置。一种用于 按需 流程,另一种用于 每日 流程。每个配置都接收一个特定的 Kafka 主题、所需的 Pod 数量以及必须处理该主题的并发工作线程数。
我们可以通过创建应用程序的新实例来读取特定的 Kafka 分区来扩展 提取器 处理。例如,如果我们的 Kafka 主题有三个分区,我们可以创建三个应用程序实例,每个实例处理一个不同的分区。
但是,使用应用程序的整个实例一次处理一条消息似乎是一种资源浪费。过去,我们的要求是每个正在运行的 Pod 都应该能够同时处理来自 Kafka 主题的多条消息。这一挑战是该项目最令人兴奋的部分。
该团队认为我们需要以编程方式执行此操作,从 Kafka 消费者接收消息并手动创建线程。然后,我们阅读了 Quarkus Kafka 指南,发现可以对使用消息的工作线程池进行一些调整。该指南说,SmallRye Reactive Messaging 文档中有更多信息。
| 在 SmallRye Reactive Messaging – 处理阻塞执行指南 中,我们发现如果我们不需要按顺序处理我们的消息,我们实际上可以定义将使用 Kafka 消息的工作池大小。这对我们来说就像魔术一样!我们所需要做的就是将这些注释放在我们的 Kafka 消费者中 |
@Incoming("extraction")
@Blocking(ordered = false, value = "extraction-pool")
public void process(Extraction extraction) {
// process the extraction
}现在,我们可以配置工作池大小,这意味着有多少线程将同时处理我们的 Kafka 消息,传递此参数
smallrye.messaging.worker.extraction-pool.max-concurrency=7|
每次提取都需要调用由其他金融机构提供的 API,有时这比 Vert.x 工作池定义的默认时间(60 秒)花费更多的时间。60 秒后,应用程序会收到警告,通知我们工作线程被阻塞。可以使用此参数进行配置 |
# The maximum amount of time the worker thread can be blocked. Default 60S
quarkus.vertx.max-worker-execute-time=300S| 我们创建了项目 POC Kakfa Quarkus,您可以在其中模拟同时运行线程以处理来自 Kafka 主题的消息的此功能。 |
使用 Hibernate ORM 的多个持久性单元
此功能对我们的项目非常重要。开放银行集成器 在 Oracle 数据库中存储了一些业务数据。为了提高处理速度,我们需要直接从此数据库获取一些信息。由于我们的应用程序有一个 DB2 数据库,因此 Hibernate ORM 多个持久性单元功能非常有帮助。更多信息请参见 Hibernate Quarkus 指南。
容错重试
我们执行的 API 可能会返回错误,表明系统暂时不可用。在这种情况下,我们需要等待一段时间然后重试。
当使用 @Retry 注释时,这非常简单
@Retry(retryOn = { ExceptionOfTheApiThatWeMustTryAgain.class }, maxRetries = 3, delay = 1000)
public void callExternalEndpoint() {
//
}我们可以使用这些属性配置重试之间的 maxRetries 和 delay
Retry/maxRetries=${APP_MAX_RETRY:3}
Retry/delay=${APP_DELAY_MS_RETRY:1000}MicroProfile 容错规范指南 解释说,我们可以单独(类或方法)或全局配置这些值。
此配置非常有用,因为我们不希望重试在我们的测试中花费太多时间,因此可以专门为测试设置值
%test.Retry/maxRetries=${APP_MAX_RETRY:3}
%test.Retry/delay=${APP_DELAY_MS_RETRY:1}使用容错舱壁同步访问
我们的 调度器 微服务不能并行运行计划。
我们使用策略类型 Recreate 将其部署在 Kubernetes 上,这意味着所有 Pod 在创建新 Pod 之前都会被终止。这保证了一次只能执行一个 Pod。那么我们如何避免来自同一实例的多个线程同时执行同一方法呢?
答案是使用 Bulkhead 容错注释
// maximum 1 concurrent requests allowed, maximum 1 requests allowed in the waiting queue
@Bulkhead(value = 1, waitingTaskQueue = 1)
public void processSchedule() {
//
}当请求无法添加到等待队列时,将抛出 BulkheadException。
关于 Quarkus 的最后几句话
我们的组织有数百名 Java 程序员,但我们看到的一个问题是很难聘请已经有 Quarkus 经验的人。我们认为,具有其他 Java 框架经验的人可以轻松学习 Quarkus - 特别是因为 Quarkus 依赖于现有和经过验证的技术(JAX-RS、CDI、Hibernate ORM、Eclipse MicroProfile…) - 并且随着时间的推移,我们将拥有更多掌握它的专业人士。
在团队经验中,Quarkus 帮助我们构建可靠的应用程序,并提供在云环境中运行现代应用程序所需的所有资源。
开发体验非常棒,并且经常发布新版本,创建新功能,使 Quarkus 变得更好。
