在虚拟线程上处理 Kafka 记录

在另一篇博文中,我们了解了如何使用 Quarkus 实现 CRUD 应用程序来利用虚拟线程。Quarkus 中的虚拟线程支持不仅限于 REST 和 HTTP。许多其他部分也支持虚拟线程,例如 gRPC、计划任务和消息传递。在本文中,我们将了解如何处理虚拟线程上的 Kafka 记录,从而提高处理的并发性。
在虚拟线程上处理消息
Quarkus Reactive Messaging 扩展支持虚拟线程。与 HTTP 类似,要在虚拟线程上执行处理,您需要使用 @RunOnVirtualThread 注解。
@Incoming("input-channel")
@Outgoing("output-channel")
@RunOnVirtualThread
public Fraud detect(Transaction tx) {
// Run on a virtual thread
}每条消息的处理都在单独的虚拟线程上运行。因此,对于来自 input-channel 的每条消息,都会创建一个新的虚拟线程(如这篇博文中所述,虚拟线程创建的成本很低)。
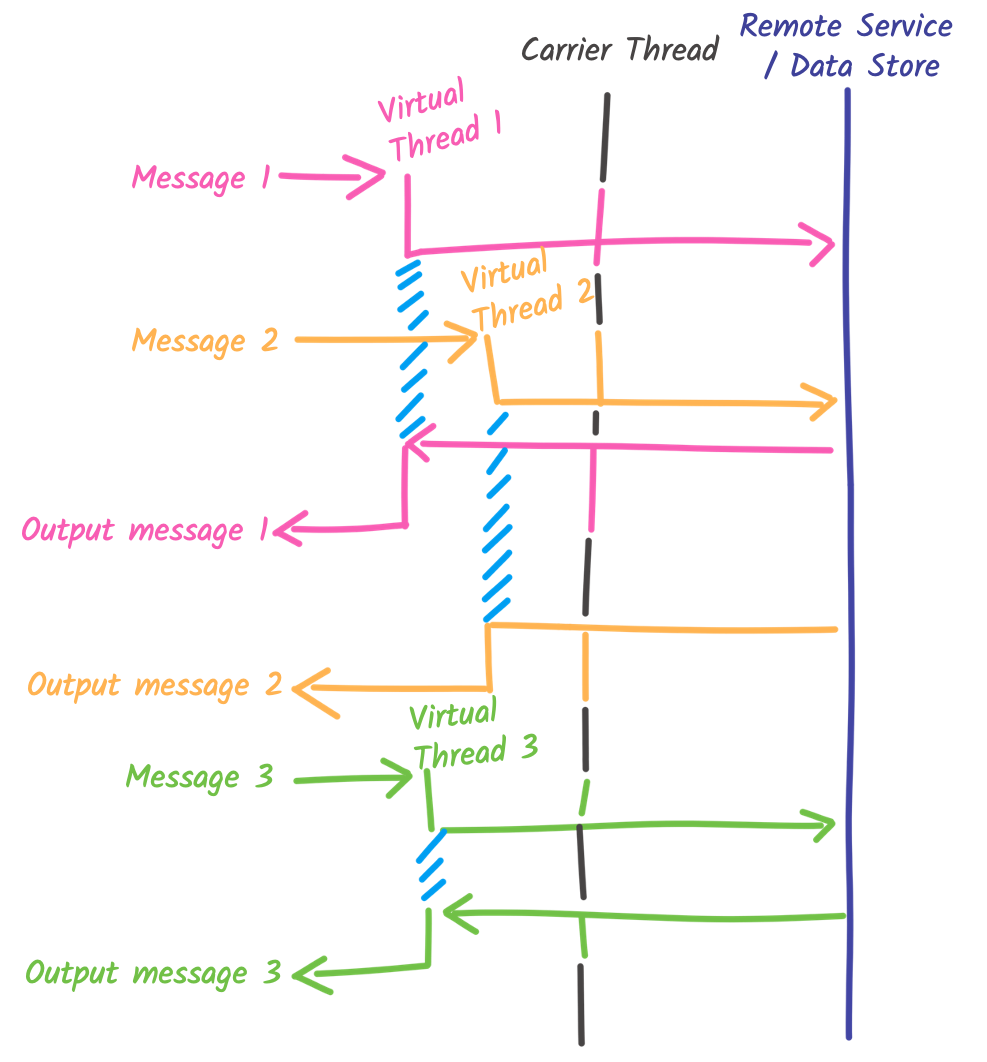
这种执行模型可以与任何 Quarkus 响应式消息传递连接器一起使用,包括 AMQP 1.0、Apache Pulsar 和 Apache Kafka。与使用 @Blocking 注解时相比,此处理的并发性不再受限于工作线程的数量。因此,这种新颖的执行模型简化了高并发数据流应用程序的开发。
正如我们稍后将看到的,如此高的并发性可能会导致问题。为了使这种并发性可控,Quarkus 将消息处理的并发数量限制为 1024(此默认值是可配置的)。此限制的主要好处之一是防止应用程序轮询数百万条消息,这在内存方面将非常昂贵。没有此限制,Kafka 应用程序将轮询已分配主题-分区的记录,并消耗大量内存。
此外,您可能想知道为什么我们不默认使用虚拟线程。原因已在之前的博文中解释过。存在可能导致虚拟线程存在风险的限制。在使用虚拟线程之前,您需要确保使用方式是安全的。我们将在本文中看到一些示例。
在虚拟线程上处理 Kafka 记录
为了说明如何在虚拟线程上处理 Kafka 记录,让我们看一个简单的应用程序。此应用程序是一个虚假欺诈检测器。它分析银行交易,如果给定账户在给定时间段内的交易金额达到阈值,我们就会认为存在欺诈。代码可在GitHub 存储库中找到。当然,您可以使用更复杂的检测算法,甚至可以使用 AI/ML。在这种情况下,我们使用了Redis 时间序列命令,但效率不高,目的是故意引入不必要的 I/O。这样做是为了利用虚拟线程的阻塞能力。
@Incoming("tx")
@Outgoing("frauds")
@RunOnVirtualThread
public Fraud detect(Transaction tx) {
String key = "account:transactions:" + tx.account;
// Add sample
long timestamp = tx.date.toInstant(ZoneOffset.UTC).toEpochMilli();
timeseries.tsAdd(key, timestamp, tx.amount, new AddArgs()
.onDuplicate(DuplicatePolicy.SUM));
// Retrieve the last sum.
var range = timeseries.tsRevRange(key, TimeSeriesRange.fromTimeSeries(),
// 1 min for demo purpose.
new RangeArgs().aggregation(Aggregation.SUM, Duration.ofMinutes(1))
.count(1));
if (!range.isEmpty()) {
// Analysis
var sum = range.get(0).value;
if (sum > 10_000) {
Log.warnf("Fraud detected for account %s: %.2f", tx.account, sum);
return new Fraud(tx.account, sum);
}
}
return null;
}如果您运行此应用程序并出现大量交易,它将无法正常工作。处理是在虚拟线程上正确执行的。但是,Redis 连接池尚未针对处理如此高的并发级别进行调整。很快,就没有可用的 Redis 连接了,它开始将命令排入等待列表。当此队列已满时,它将开始拒绝命令。幸运的是,您可以使用以下方式配置等待队列的最大大小:
# Increase Redis pool size (and waiting queue size) as we will have a lot of concurrency
quarkus.redis.max-pool-size=100 # Number of connection in the pool
quarkus.redis.max-pool-waiting=10000 # Waiting queue max size虽然我们在本应用程序中使用 Redis,但您会遇到许多其他客户端(包括 HTTP 客户端)的相同问题。因此,请妥善配置它们以处理这种新的并发级别。
如果您运行该应用程序并打开 UI,您将看到并发性达到了预期的最大值 1024。