使用 LangChain4j 分析 PDF 文档

在我的咨询工作中,客户经常向我们提出具有挑战性的问题,需要创新的解决方案。最近,我们接到一项任务,要求通过自动分析从 PDF 文档中提取结构化元数据。在下文中,我将分享这个真实世界挑战的简化版本,以及我们如何解决它。
用例
我们的客户收到包含多达数百份需要审核的可移植文档格式 (PDF) 租赁文档的压缩档案(.zip 文件)。每份文档包含必须验证准确性的财产租赁详细信息。审核过程包括检查各种业务规则 - 例如,识别租期短于 2 年的租赁。目前,此文档验证是手动完成的,非常耗时。客户希望自动化和简化此审核工作流程,以提高效率。
这些租赁文档的一些复杂性包括:
-
文档不是标准格式,因此每份租赁合同可能由不同的物业经理以不同的方式编写。
-
文档可能经过扫描,因此文本有时是手写而不是打字的。
-
文档可能包含多个页面,这些页面的顺序并不总是相同的。
-
租赁期限可能不是实际日期,而是写为“从开始日期起五年到期”或“在开始日期的周年纪念日到期”。
-
我们的客户需要土地面积和税号信息等元数据来验证租赁详细信息。
您可以理解为什么人工审核和验证文档非常耗时。
我们的解决方案
在咨询 Dmytro Liubarskyi 并与 Quarkus 团队合作后,我们实施了一个使用 LangChain4j 进行文档元数据提取的解决方案。我们选择 Google Gemini 作为我们的大型语言模型 (LLM),因为它擅长通过其内置的光学字符识别 (OCR) 功能进行 PDF 分析,从而能够从数字文档和扫描文档中准确提取文本。
技术细节
该应用程序使用以下技术构建:
-
Quarkus - Kubernetes 原生 Java 框架
-
LangChain4j - LangChain 的 Java 绑定,用于与 LLM 交互
-
Google Gemini AI - 用于 PDF 文档分析和信息提取
-
Quarkus REST - 用于处理多部分文件上传
-
HTML/JavaScript 前端 - 用于文件上传和结果显示的简单 UI
后端通过以下步骤处理 PDF:
-
通过多部分表单数据接受 PDF 上传
-
将 PDF 内容转换为 base64 编码
-
将具有结构化 JSON 模式的消息发送到 Gemini AI 以进行响应格式化
-
以标准化格式返回已解析的租赁信息
-
在 Web 界面上以表格格式显示结果
主要组件包括:
-
LeaseAnalyzerResource- 用于 PDF 分析的 REST 端点 -
LeaseReport- 租赁信息的数据结构 -
用于文件上传和结果显示的 Web 界面
工作原理
首先,我们需要一个 Google Gemini API 密钥。您可以免费获得一个,请在此处查看更多详细信息:Gemini API 密钥文档。
export QUARKUS_LANGCHAIN4J_AI_GEMINI_API_KEY=<your-google-ai-gemini-api-key>接下来,我们需要安装 LangChain4j 依赖项
<dependency>
<groupId>io.quarkiverse.langchain4j</groupId>
<artifactId>quarkus-langchain4j-ai-gemini</artifactId>
<version>0.25.0</version>
</dependency>配置 Gemini LLM
接下来,我们需要将 Gemini LLM 连接到应用程序(使用您的 Google AI Gemini API 密钥)。
quarkus.langchain4j.ai.gemini.chat-model.model-id=gemini-2.0-flash
quarkus.langchain4j.log-requests=true
quarkus.langchain4j.log-responses=true记录请求和响应是可选的,但有助于调试。
注册 AI 服务
我们必须注册 AI 服务才能使用 LeaseAnalyzer 接口。
import dev.langchain4j.data.pdf.PdfFile;
import dev.langchain4j.service.UserMessage;
import io.quarkiverse.langchain4j.PdfUrl;
import io.quarkiverse.langchain4j.RegisterAiService;
@RegisterAiService(chatMemoryProviderSupplier = RegisterAiService.NoChatMemoryProviderSupplier.class)
public interface LeaseAnalyzer {
@UserMessage("Analyze the given document")
LeaseReport analyze(@PdfUrl PdfFile pdfFile);
}定义您的数据结构
现在我们需要为租赁信息建模数据结构,我们希望 LLM 从任何租赁文档中提取这些信息。您可以根据您需要从 PDF 文档中获取的信息自定义这些字段,但在我们的用例中,我们提取以下信息:
public record LeaseReport(
LocalDate agreementDate,
LocalDate termStartDate,
LocalDate termEndDate,
LocalDate developmentTermEndDate,
String landlordName,
String tenantName,
String taxParcelId,
BigDecimal acres,
Boolean exclusiveRights) {
}创建 REST 端点
最后,我们需要创建一个 LeaseAnalyzerResource 类,它将使用 LLM 从 PDF 文档中提取租赁信息。
@Inject
LeaseAnalyzer analyzer;
@PUT
@Consumes(MediaType.MULTIPART_FORM_DATA)
@Produces(MediaType.TEXT_PLAIN)
public String upload(@RestForm("file") FileUpload fileUploadRequest) {
final String fileName = fileUploadRequest.fileName();
log.infof("Uploading file: %s", fileName);
try {
// Convert input stream to byte array for processing
byte[] fileBytes = Files.readAllBytes(fileUploadRequest.filePath());
// Encode PDF content to base64 for transmission
String documentEncoded = Base64.getEncoder().encodeToString(fileBytes);
log.info("Google Gemini analyzing....");
long startTime = System.nanoTime();
LeaseReport result = analyzer.analyze(PdfFile.builder().base64Data(documentEncoded).build());
long endTime = System.nanoTime();
log.infof("Google Gemini analyzed in %.2f seconds: %s", (endTime - startTime) / 1_000_000_000.0, result);
return result;
} catch (IOException e) {
throw new RuntimeException(e);
}
}有一个简单的 HTML/JavaScript 前端,允许您上传 PDF 文档并查看结果。在下面的示例中,上传并分析了 3 个不同的租赁文档。
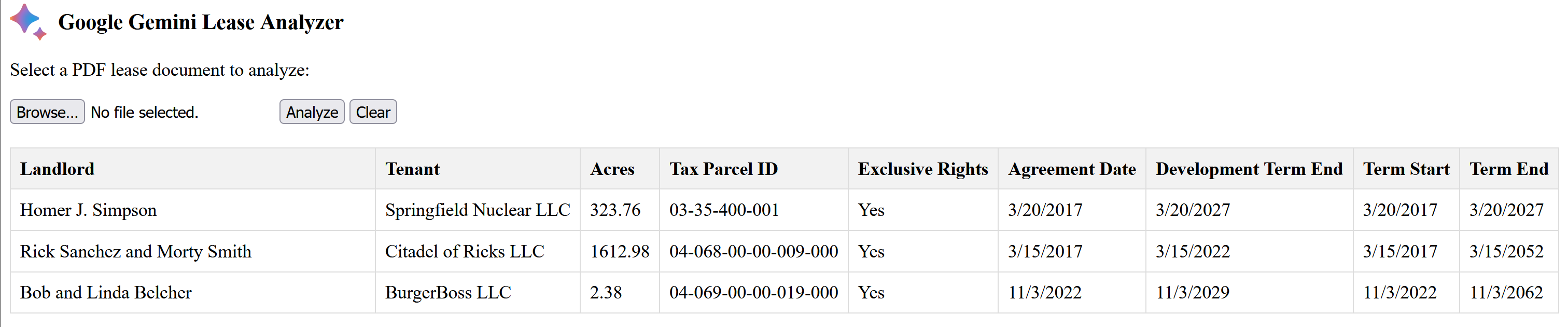
您可以在 GitHub 上找到完整的示例代码。
