如何使用 Stork 选择“正确”的服务?

分布式系统的本质在于服务之间的交互。在现代架构中,您通常拥有服务的多个实例来分摊负载或通过冗余提高弹性。
但是,当您拥有所有这些实例时,如何选择最好的一个呢?Stork 就是为此而设计的。Stork 是一个服务发现和负载均衡框架。Stork 将定位并为每次调用选择最合适的实例。在这篇文章中,我们将探讨 Stork 提供的一些负载均衡策略,以便您可以决定哪种策略最适合您。
游乐场
当您的应用程序需要调用远程服务(2)时,它会请求 Stork 定位该服务(3)。此服务发现步骤会检索服务实例。您可能只有一个实例,这可以简化选择过程,但您也可以有多个可用实例。然后,您需要选择一个。这时 Stork 的负载均衡功能就派上用场了,它会选择实例(4)。
为了说明此服务选择功能,我们需要一个应用程序。下图代表了我们的系统
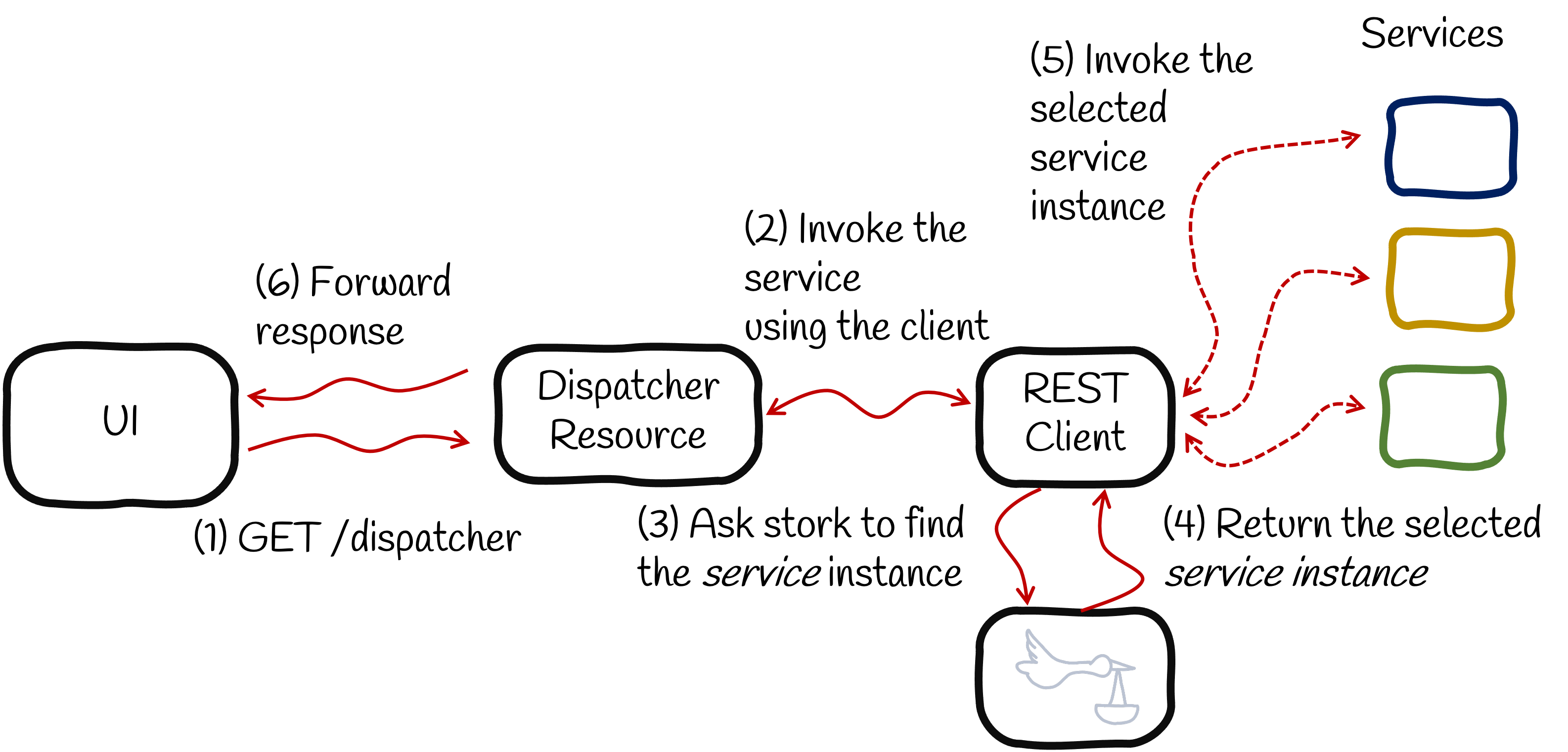
该系统由三个服务实例组成:蓝色、黄色和绿色
-
蓝色实例返回 🔵 。
-
黄色实例返回 🟡 。此服务比蓝色服务稍慢。
-
绿色实例返回 🟢 。它是最快的,但有 20% 的失败几率。
主应用程序包含一个配置为使用 stork 的 REST Client
@Path("/")
// The client delegates the discovery and selection to stork.
@RegisterRestClient(baseUri = "stork://my-service")
public interface Client {
@GET
@Produces(MediaType.TEXT_PLAIN)
String invoke();
}主端点将调用委托给客户端
@Path("/dispatcher")
public class Dispatcher {
@RestClient
Client client;
@GET
@Produces(MediaType.TEXT_PLAIN)
public String invoke() {
return client.invoke(); // just delegate to the REST client.
}
}UI(可在 https://:8080 上访问)允许您调用 /dispatcher 端点十次。它将使用 REST Client 调用十次,这将导致十次服务选择。这些调用可以是:
-
顺序调用:它按顺序调用服务十次,在发出下一次调用之前等待前一次调用完成。这种方法保留了顺序。
-
并发调用:它同时发出十个请求。您不控制这些请求的发送方式以及接收和处理它们的顺序。
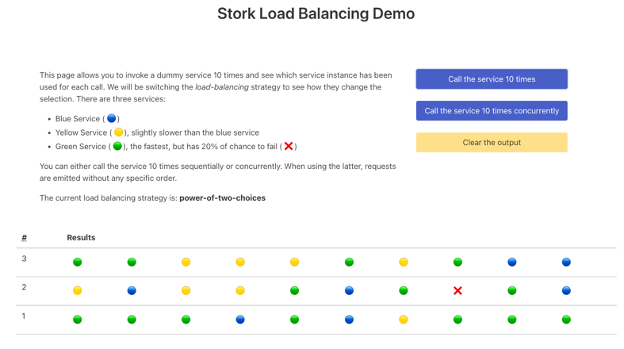
现在让我们看看 Stork 提供的各种负载均衡策略。
轮询策略
如果您不设置任何负载均衡策略,Stork 将使用轮询。当您调用服务(顺序或并发)时,您会得到类似这样的结果:

Stork 遍历可用的实例。因此,我们可以看到 🔵 🟡 🟢 🔵 🟡 🟢 🔵 🟡 🟢 序列。当调用失败时,它不会更改策略。当绿色实例失败(❌)时,它不会驱逐该实例,而是继续迭代,然后选择蓝色实例,接着是黄色实例,然后再次选择绿色实例。
轮询策略方便地将负载平均分配给一组服务实例。当发生故障且可以重试时,您可以使用 @Retry 来使用下一个服务实例。
随机策略
与轮询策略不同,随机策略会随机选择一个实例。以下依赖项提供了随机策略:
<dependency>
<groupId>io.smallrye.stork</groupId>
<artifactId>stork-load-balancer-random</artifactId>
</dependency>要使用此负载均衡策略,您必须配置服务的负载均衡器:
quarkus.stork.my-service.load-balancer.type=random如下图所示,它不遵循任何模式。因此,同一个服务实例可能会连续被调用多次。

此策略不会在实例之间平均分配负载。在最坏的情况下,它可能会选择一个繁忙的实例。但是,如果被调用的服务也被其他应用程序(也使用随机负载均衡)使用,那么分摊负载并避免全局性地使特定实例过载可能会很方便。
最少请求数
前两种策略不监控调用。最少请求数策略会。当选择一个实例时,它会跟踪调用,对于此策略,它会计算正在进行的请求数。当调用完成(无论成功与否),它会递减计数器。因此,选择一个实例返回具有较少正在进行调用数的实例。
要使用此策略,您需要以下依赖项:
<dependency>
<groupId>io.smallrye.stork</groupId>
<artifactId>stork-load-balancer-least-requests</artifactId>
</dependency>您还需要配置服务的负载均衡器:
quarkus.stork.my-service.load-balancer.type=least-requests如果顺序调用服务,它总是选择同一个实例

事实上,该服务的正在进行调用数始终为 0,因为它会等待响应后再调用一次。但是,当您并发调用服务时,此策略变得更加相关:

由于绿色服务是最快的,因此它被调用的频率更高,因为正在进行的请求数会很快减少。因此,当蓝色和黄色服务仍在进行调用时,绿色服务已恢复到 0 并被选中。
此策略在服务具有具有不同响应时间的 API 时非常方便。例如,您可能有一些响应很快的端点,也有一些执行更多工作、因此花费更多时间的端点。
此策略有一个缺点。如果您有很多服务实例,您需要遍历整个列表才能找到要选择的实例。
随机两项选择
此策略扩展了最少请求数策略并解决了上述缺点。它不是遍历整个实例列表,而是随机选择两个实例,并选择正在进行请求数较少的一个。
要使用此策略,您需要以下依赖项:
<dependency>
<groupId>io.smallrye.stork</groupId>
<artifactId>stork-load-balancer-power-of-two-choices</artifactId>
</dependency>您还需要为服务配置负载均衡器:
quarkus.stork.my-service.load-balancer.type=power-of-two-choices由于我们只有三个实例,因此结果与最少请求数相似:

但是,当您拥有大量实例且迭代花费太多时间时,此策略成本较低。在最坏的情况下,它会选择两个最繁忙的实例,然后选择请求数较少的一个。
最少响应时间
最少响应时间会跟踪响应时间和故障。因此,它会选择最快的实例。该策略通过对故障实例进行处罚来处理故障。
要使用此策略,您需要以下依赖项:
<dependency>
<groupId>io.smallrye.stork</groupId>
<artifactId>stork-load-balancer-least-response-time</artifactId>
</dependency>您还需要为服务配置负载均衡器:
quarkus.stork.my-service.load-balancer.type=least-response-time此策略会更频繁地选择绿色实例。但是,由于存在故障几率,它有时也会选择其他实例。

总结
这篇博客文章介绍了 Stork 提供的负载均衡策略。您可以在 Stork 网站上找到完整列表。
像 random 或 round-robin 这样的策略允许在实例之间分配负载。least-request、power-of-two-choices 和 least-response-time 策略会监控调用以选择负载较少或响应时间较快的实例。
如果这些策略不符合您的要求,那也不是问题,因为您可以 实现自己的策略,并制定完美的选型算法。
您还可以通过 使用 Stork 与 Quarkus 的指南 了解更多关于 Stork 及其在 Quarkus 中集成的信息。
