在没有数据库的 Quarkus 应用程序中利用 Hibernate Search 功能

这是本系列文章的第二篇,深入探讨了 quarkus.io/guides/ 指南搜索的后台应用程序的实现细节。
Hibernate Search 主要以其 与 Hibernate ORM 的集成而闻名,它可以检测到通过 ORM 对实体所做的更改,并将这些更改反映在搜索索引中。但 Hibernate Search 的功能远不止于此。
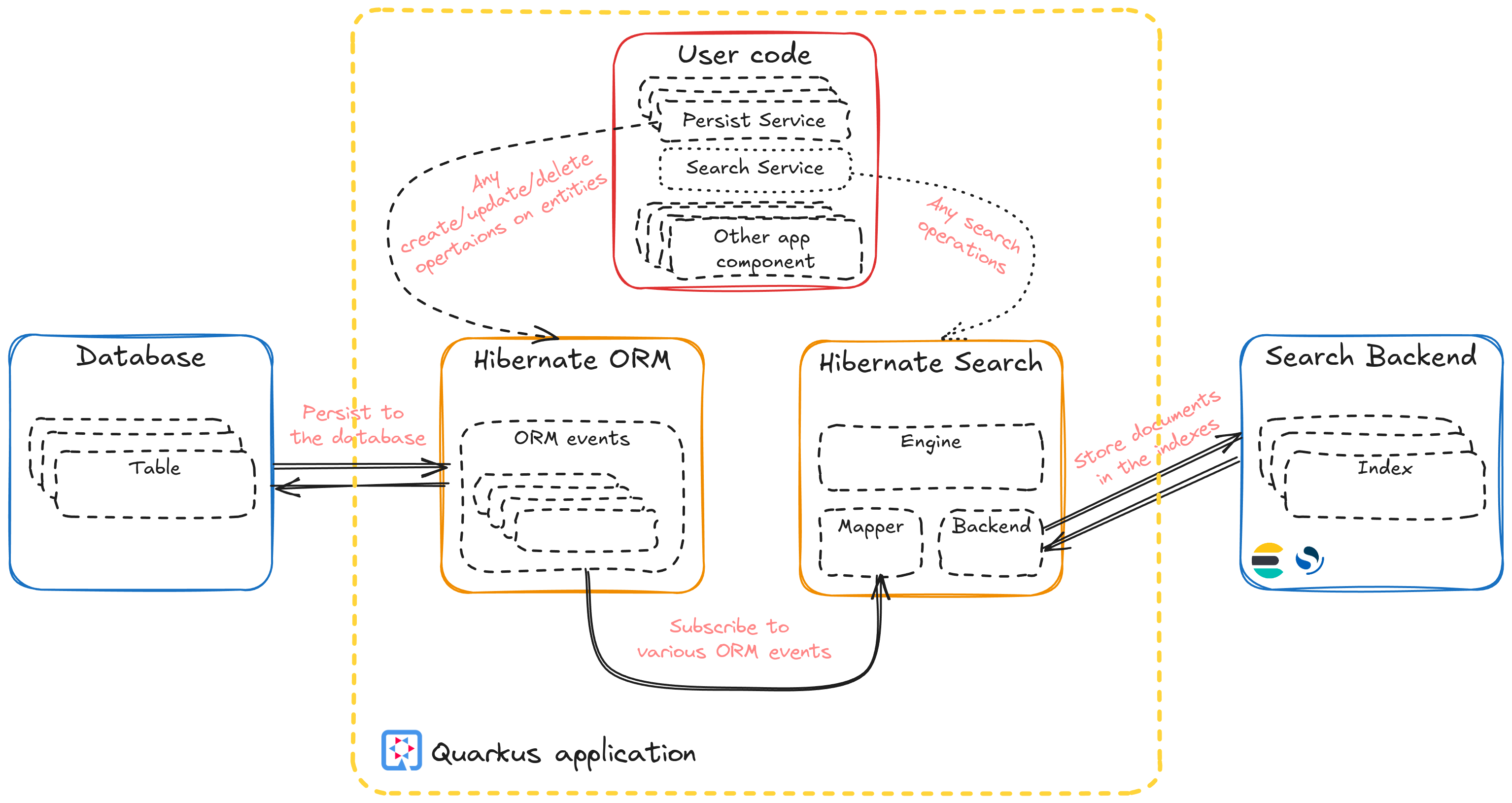
并非所有需要搜索功能的应用都依赖数据库来提供搜索索引的源。有些应用依赖 NOSQL 存储(此时 Hibernate ORM 不适用),甚至依赖平面文件存储。在这些场景下该如何处理?
这时 Hibernate Search Standalone mapper 就能派上用场了。它 最近被包含为 Quarkus 核心扩展之一。此映射器允许使用 Hibernate Search 注释来注释领域实体,然后利用 Search DSL 的强大功能来执行搜索操作等。
随着 Quarkus 3.10 的发布,我们已将支持 quarkus.io/guides/ 的 Quarkus 应用程序迁移到了 Standalone 映射器,并希望与您分享如何使用此映射器来索引来自文件的数据,并且无需知道要索引的记录总数。有关如何配置和使用此映射器的更深入的介绍,请参阅 指南。
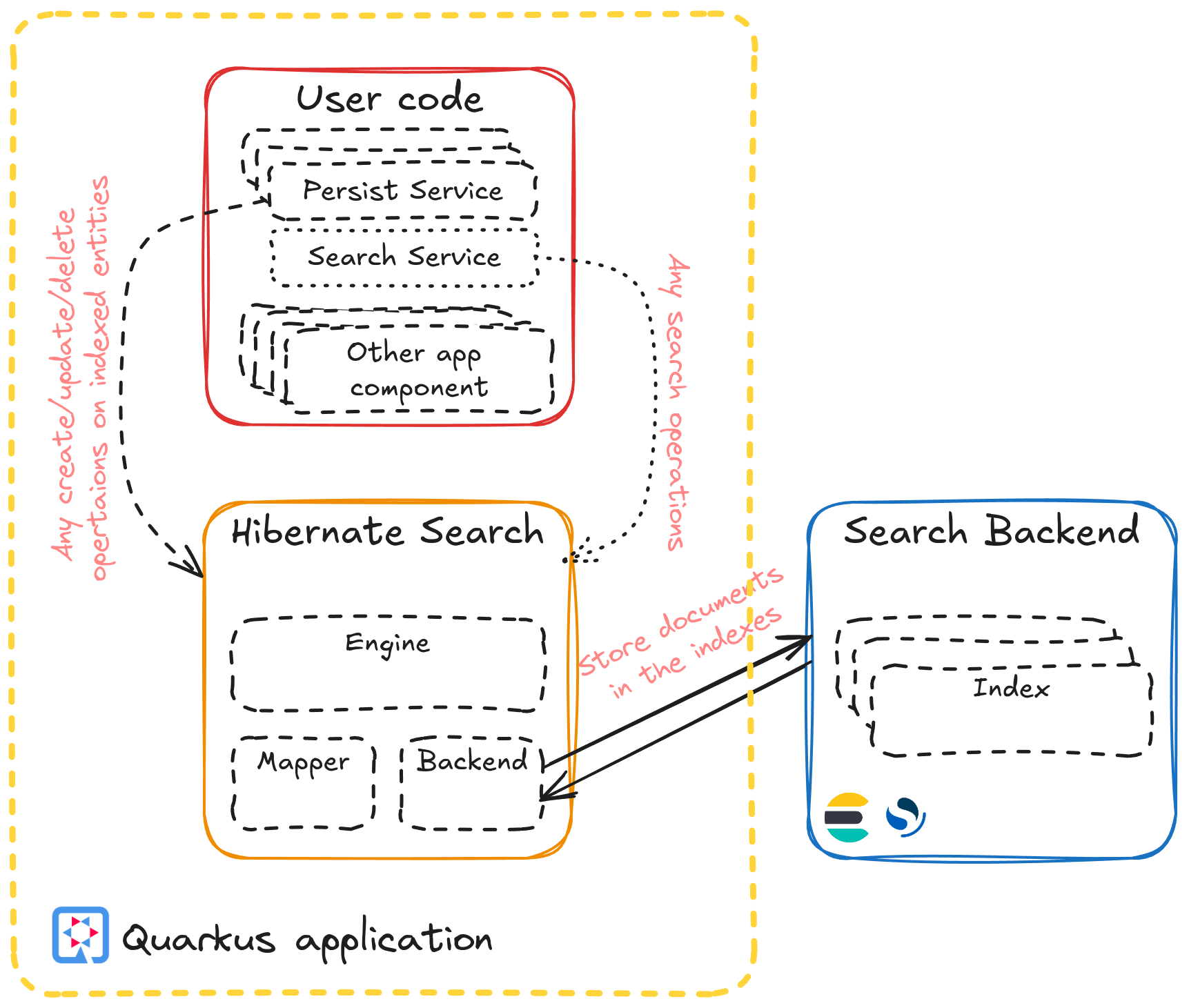
让我们开始描述此搜索应用程序需要执行的任务。该应用程序的主要目标是为文档指南提供搜索功能。它通过读取多个文件来获取有关这些指南的必要信息。我们希望只读取数据一次,尽快开始索引,并且只将必要数量的记录保留在内存中。我们还希望监视进度并报告在索引过程中可能发生的任何异常。因此,我们将创建一个有限的数据流,并将其馈送到 mass indexer,它将在搜索索引中创建文档,之后我们将使用这些文档执行搜索操作。
总的来说,批量索引可以很简单:
@Inject
SearchMapping searchMapping; (1)
// ...
var future = searchMapping.scope(Object.class) (2)
.massIndexer() (3)
.start(); (4)-
在您的应用程序的某个地方注入
SearchMapping,以便可以使用它来访问 Hibernate Search 的功能。 -
创建针对我们计划重新索引的实体的作用域。在这种情况下,应该针对所有已索引的实体;因此,可以使用
Object.class来创建作用域。 -
使用默认配置创建批量索引器。
-
启动索引过程。启动过程会返回一个 Future;索引在后台进行。
为了让 Hibernate Search 执行此操作,我们必须告诉它如何加载已索引的实体。我们将使用 EntityLoadingBinder 来实现此目的。它是一个简单的接口,提供对绑定上下文的访问,我们可以在其中定义选择-加载策略(用于搜索)和批量加载策略(用于索引)。由于在我们的例子中,我们只对批量索引器感兴趣,因此仅定义批量加载策略就足够了。
public class GuideLoadingBinder implements EntityLoadingBinder {
@Override
public void bind(EntityLoadingBindingContext context) { (1)
context.massLoadingStrategy(Guide.class, new MassLoadingStrategy<Guide, Guide>() { (2)
// ...
});
}
}-
实现
EntityLoadingBinder的单个bind(..)方法。 -
为
Guide搜索实体指定批量加载策略。我们将在本文的后面讨论该策略的实现。
然后,定义了实体加载绑定器后,我们只需在 @SearchEntity 注释中引用它即可。
@SearchEntity(loadingBinder = @EntityLoadingBinderRef(type = GuideLoadingBinder.class)) (1)
@Indexed( ... )
public class Guide {
@DocumentId
public URI url;
// other fields annotated with various Hibernate Search annotations,
// e.g. @KeywordField/@FullTextField.
}-
通过类型引用加载绑定器实现。与许多其他 Hibernate Search 组件一样,这里也可以使用 CDI bean 引用,通过提供 bean 名称来实现,例如,如果加载绑定器需要访问某些 CDI bean 并且它本身就是一个 CDI bean。
这一切都已准备就绪。唯一悬而未决的问题是如何实现批量加载策略。让我们先从高层次上回顾一下批量索引器的工作原理。
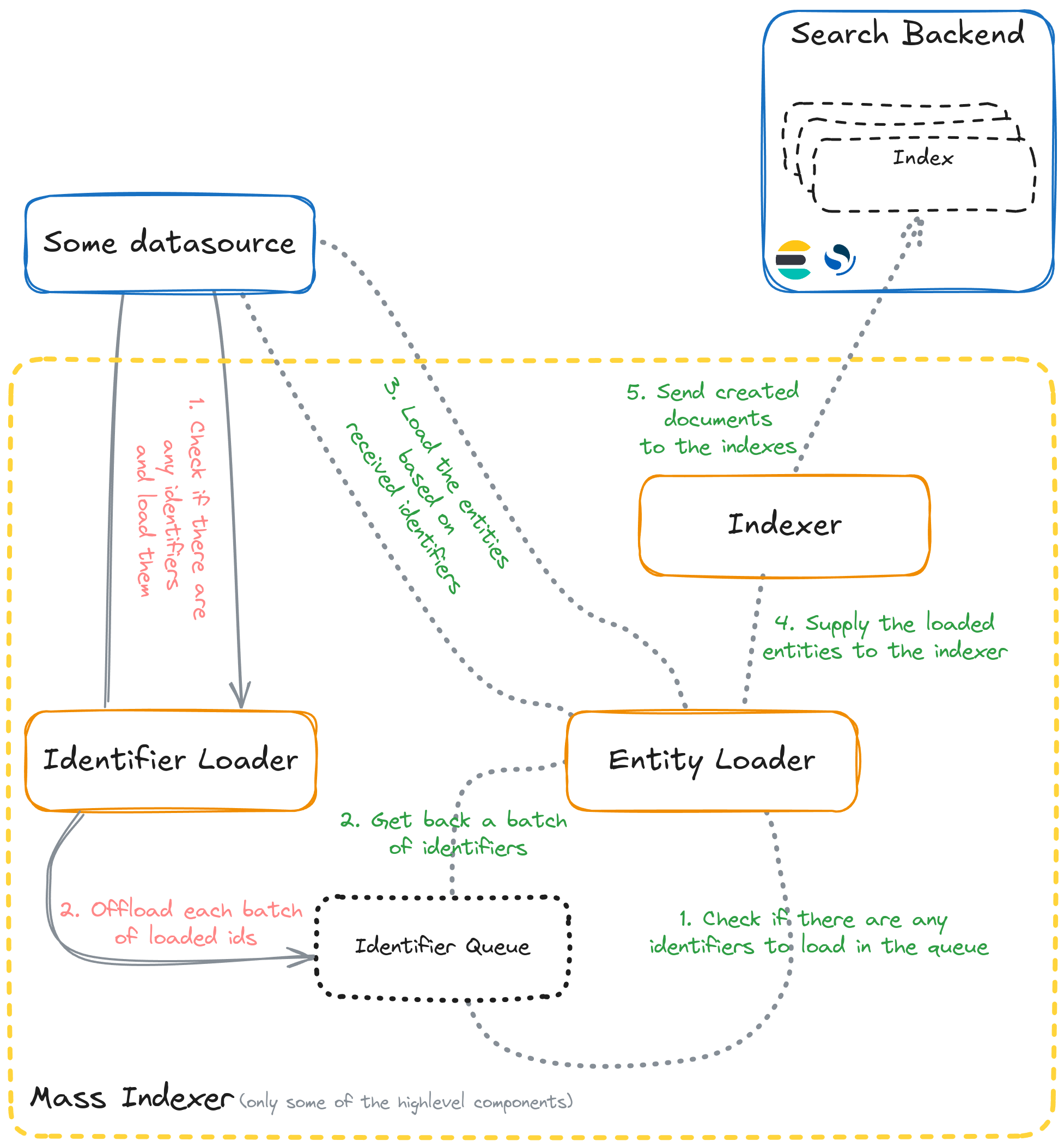
实现批量加载策略需要提供标识符和实体加载器。如前所述,在我们的例子中,我们想要一个从文件中读取信息的数据流,并且只读取一次。因此,我们希望避免解耦 ID/实体读取步骤。虽然标识符加载器的契约表明它应该向接收器提供标识符批次,但没有任何内容可以阻止我们传递实际实体实例的批次。在这种情况下是可以接受的,因为我们只对批量加载感兴趣;我们没有实现用于搜索的选中加载策略。现在,如果标识符加载器提供实际的实体实例,那么实体加载器所要做的就是将接收到的“标识符”批次(即实际实体)传递给实体接收器。
考虑到这一点,批量加载策略可以实现为:
new MassLoadingStrategy<Guide, Guide>() {
@Override
public MassIdentifierLoader createIdentifierLoader(LoadingTypeGroup<Guide> includedTypes,
MassIdentifierSink<Guide> sink, MassLoadingOptions options) {
// ... (1)
};
}
@Override
public MassEntityLoader<Guide> createEntityLoader(LoadingTypeGroup<Guide> includedTypes,
MassEntitySink<Guide> sink,
MassLoadingOptions options) {
return new MassEntityLoader<Guide>() { (2)
@Override
public void close() {
// noting to do
}
@Override
public void load(List<Guide> guides) throws InterruptedException {
sink.accept(guides); (3)
}
};
}
})-
我们将在以下代码片段中查看标识符加载器的实现,因为它比直通实体加载器稍微棘手一些。因此,我们想仔细研究一下。
-
直通实体加载器的实现。
-
如上所述,我们将搜索实体视为标识符,并将接收到的实体直接传递给接收器。
| 如果将实体作为标识符传递感觉像是一种 hack,那是因为它就是。Hibernate Search 将在某个时候提供替代 API 来更优雅地实现这一点:HSEARCH-5209 |
由于指南搜索实体是从文件中读取的信息构建的,因此我们必须以某种方式将这些指南流传递给标识符加载器。我们可以通过使用 MassLoadingOptions options 来实现。这些批量加载选项提供了对用户传递给批量索引器的上下文对象的访问。
@Inject
SearchMapping searchMapping; (1)
// ...
var future = searchMapping.scope(Object.class) (2)
.context(GuideLoadingContext.class, guideLoadingContext) (3)
// ... (4)
.massIndexer() (5)
.start(); (6)-
在您的应用程序的某个地方注入
SearchMapping。 -
照常创建作用域。
-
将上下文对象传递给知道如何读取文件并且能够提供
Guide搜索实体批次的批量索引器。有关如何实现此类上下文的示例,请参见以下代码片段。 -
根据需要设置任何其他批量索引器配置选项。
-
创建一个批量索引器。
-
启动索引过程。
public class GuideLoadingContext {
private final Iterator<Guide> guides;
GuideLoadingContext(Stream<Guide> guides) {
this.guides = guides.iterator(); (1)
}
public List<Guide> nextBatch(int batchSize) {
List<Guide> list = new ArrayList<>();
for (int i = 0; guides.hasNext() && i < batchSize; i++) {
list.add(guides.next()); (2)
}
return list;
}
}-
从指南的有限数据流中获取迭代器。
-
从迭代器中读取下一批指南。我们使用的是我们将从批量加载选项中检索到的批次大小限制,并检查迭代器以查看是否还有更多实体可以拉取。
现在,有了从流中分批读取实体的方法,并且知道如何将其传递给批量索引器,实现标识符加载器可以像以下一样简单:
@Override
public MassIdentifierLoader createIdentifierLoader(LoadingTypeGroup<Guide> includedTypes,
MassIdentifierSink<Guide> sink, MassLoadingOptions options) {
var context = options.context(GuideLoadingContext.class); (1)
return new MassIdentifierLoader() {
@Override
public void close() {
// nothing to do
}
@Override
public long totalCount() {
return 0; (2)
}
@Override
public void loadNext() throws InterruptedException {
List<Guide> batch = context.nextBatch(options.batchSize()); (3)
if (batch.isEmpty()) {
sink.complete(); (4)
} else {
sink.accept(batch); (5)
}
}
};
}-
检索预期传递给批量索引器的指南加载上下文。(例如,
.context(GuideLoadingContext.class, guideLoadingContext)) -
在完成读取所有文件并完成索引之前,我们不知道会有多少指南,所以我们在这里只传递
0。这些信息并不关键:它仅用于监视进度。
这是我们计划改进的领域之一;请参阅 我们目前正在进行的一项改进。 -
请求下一批指南。
options.batchSize()将为我们提供当前批量索引器配置的值。 -
如果批次为空,则表示流迭代器不再返回指南。因此,我们可以通过调用
.complete()来通知批量索引接收器不再提供项目。 -
如果加载的批次中有任何指南,我们将把它们传递给接收器进行处理。
总而言之,以下是处理从未依赖标识符查找的情况下,从数据源索引未知数量的搜索实体,同时每个实体只读取一次的步骤总结:
-
首先创建一个加载器绑定器,并通过
@SearchEntity注释告知 Hibernate Search。 -
实现一个批量加载策略(
MassLoadingStrategy),其中包括-
一个标识符加载器,它执行所有繁重的工作并实际构建完整的实体。
-
一个实体加载器,它将标识符加载器加载的实体直接传递给索引接收器。
-
-
通过批量索引器上下文提供用于加载数据的任何有用的服务、资源、助手等。并通过
options.context(..);在加载器中访问它们。 -
一切就绪后,像往常一样运行批量索引。
有关此方法的完整工作示例,请查看 GitHub 上的 search.quarkus.io。
请注意,本文讨论的某些功能仍处于孵化阶段,未来可能会发生变化。特别是,我们已经确定并正在对批量索引有限数据流(事先未知实体总数)的可能 改进 进行工作。如果您觉得本文所述方法很有趣,并且有类似的用例,我们鼓励您尝试一下。如果您有任何想法和改进建议,欢迎随时与我们联系。
请继续关注,因为我们将在接下来的几周内发布更多博文,探讨此应用程序其他有趣的实现方面。祝您搜索和批量索引愉快!
