利用 Quarkus 的编译时元编程能力提高 Jackson 的序列化性能

Quarkus 设计者所做的关键架构决策之一是将尽可能多的工作从启动时转移到构建时。这一选择意味着将每个扩展的部署(也称为构建时)部分和运行时部分清晰地分离,并允许一次性完成大部分工作,从而使典型的 Quarkus 应用程序具有更小的占地面积和更快的加载时间。
这种架构的一个结果是能够广泛利用元编程,识别和分析实现给定应用程序领域模型的 Java 类,并生成其他代码,以适时高效地操作这些类。特别是,本文讨论的改进目标是使用在构建时生成的代码替换基于反射的标准 Jackson 序列化机制。
反射被许多 Java 框架和库用来支持动态行为(并且常常被滥用)。如果构建时完成的工作更多,那么这种动态性就不再需要了。将反射减少到最低限度可以提高性能。它还使应用程序更适合编译为原生二进制文件(GraalVM 闭世界假设)。
对象到 JSON 序列化领域也已经通过Qson实现了类似的想法,Qson 是一个 Quarkus 扩展,通过 Gizmo 生成反序列化器(解析器)和序列化器(写入器)类的字节码。然而,这是对 Jackson 的全面替代,并带来了一些相当显著的限制。
如果您决定坚持最常见的选择,并在调用 REST 端点时保留使用 Jackson 进行对象 JSON 序列化,那么您仍然需要为该库开箱即用的、高度基于反射的实现付出代价。在本文中,我将阐述我如何填补这一空白,更重要的是,我学到了如何编写 Quarkus 扩展,或者在我的情况下改进现有扩展,特别是如何使用 Jandex 和 Gizmo 等工具。
开箱即用的 Jackson 基于反射的序列化
在尝试从 Jackson 的序列化中移除反射使用之前,让我们先看看当前的情况。为此,我向我和 Francesco Nigro 编写的基准测试套件添加了一个新的 REST 端点,该套件也用于我们的Devoxx Belgium 性能分析研讨会。此基准测试的目标是压力测试 JSON 序列化,因此此端点除了返回并随后将一个固定对象序列化为 JSON 之外,什么也不做,本质上是写入并返回类似以下内容的 JSON。
{
"address": {
"street": "viale Michelangelo",
"town": "Mondragone"
},
"children": [
{
"age": 12,
"firstName": "Sofia",
"lastName": "Fusco"
},
{
"age": 9,
"firstName": "Marilena",
"lastName": "Fusco"
}
],
"creditCards": [
{
"limit": 100,
"name": "Visa"
},
{
"limit": 150,
"name": "Amex"
}
],
"age": 50,
"firstName": "Mario",
"lastName": "Fusco"
}针对该端点运行基准测试套件,我得到了以下结果。
Profiling for 20 seconds
Done
Thread Stats Avg Stdev Max +/- Stdev
Latency 115.82μs 77.29μs 14.88ms 93.27%
Req/Sec 79104.05 14774.96 101709.00 87.80
3243266 requests in 40.001s, 1.30GB read
Requests/sec: 81079.62
Transfer/sec: 33.33MB换句话说,我的笔记本电脑在服务该端点时每秒只能处理略多于 81K 的请求。我们将看到,摆脱反射将带来 12% 的性能提升,使其能够每秒处理超过 92K 的请求,特别是产生以下结果。
Profiling for 20 seconds
Done
Thread Stats Avg Stdev Max +/- Stdev
Latency 102.25μs 70.14μs 19.66ms 92.95%
Req/Sec 90045.27 15073.98 103537.00 97.56
3691856 requests in 40.001s, 1.48GB read
Requests/sec: 92294.09
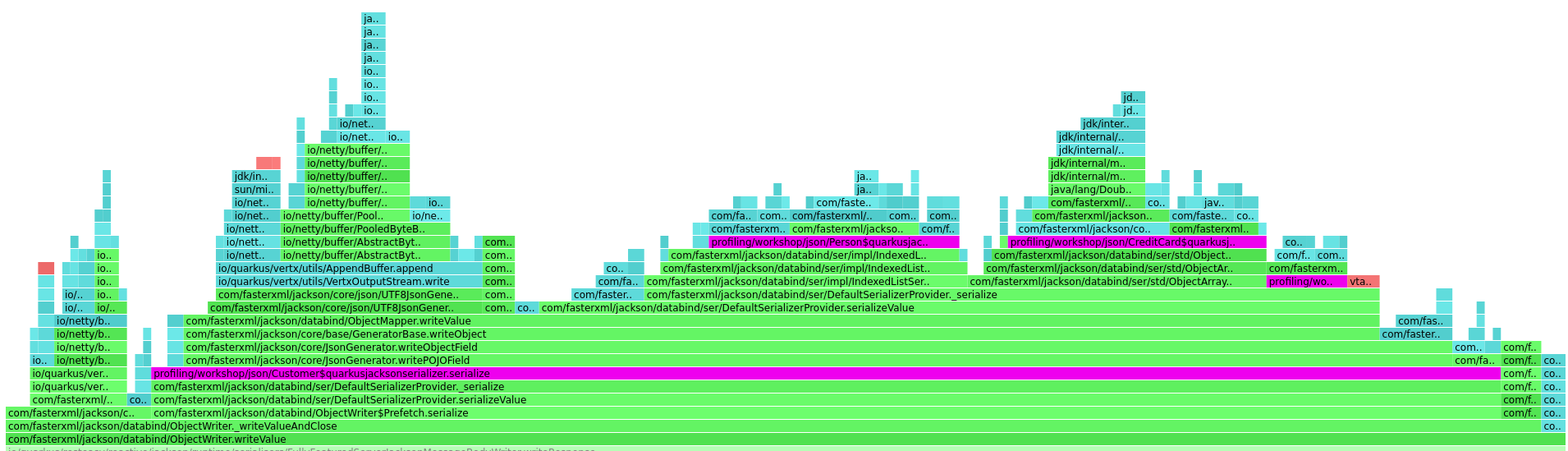
Transfer/sec: 37.94MB由于我们的基准测试套件旨在用于性能分析,因此它还自动生成了正在研究的基准测试的火焰图。在触发 JSON 序列化的 rest-jackson 扩展方法上放大火焰图,我们会发现以下情况,其中我们可以看到将对象转换为其 JSON 表示形式的 Jackson 方法 `ObjectWriter::writeValue` 在基准测试执行期间的 252 个样本的堆栈中被找到。
进一步放大到 Jackson 的 `BeanPropertyWriter::serializeAsField` 方法的火焰图,并搜索“reflect”一词,可以看到 Jackson 需要在多少不同的地方(在此火焰图中以紫色显示)使用 Java 反射来读取要序列化的对象的状态并将其写入 JSON 字符串。

正如预期的那样,这个用例需要大量使用反射,而这正是我们想要避免的。我们已经发现 JSON 序列化是由 rest-jackson 扩展执行的,所以让我们看看如何修改它来实现这个目标。
覆盖 Jackson 序列化
Jackson 以一种相当简单的方式使其标准基于反射的序列化行为可以被覆盖。只需实现一个扩展 `StdSerializer` 的类,从而定义给定 POJO 的实例应如何渲染为 JSON,大致如下:
public class PersonSerializer extends StdSerializer {
public PersonSerializer() {
super(Person.class);
}
public void serialize(Object obj, JsonGenerator jsonGen, SerializerProvider serProv) throws IOException {
Person person = (Person)obj;
jsonGen.writeStartObject();
jsonGen.writeNumberField("age", person.getAge());
jsonGen.writeStringField("name", person.getName());
jsonGen.writeEndObject();
}
}然后将此序列化器添加到模块中,并将其注册到 Jackson 用于执行 JSON 序列化的 `ObjectMapper` 上。
SimpleModule module = new SimpleModule();
module.addSerializer(Person.class, new PersonSerializer());
ObjectMapper mapper = new ObjectMapper();
mapper.registerModule(module);通过此设置,每次 Jackson 需要将 `Person` 类的实例转换为其 JSON 表示时,它将通过此自定义序列化器完成,而不是通过反射访问 person 的字段。
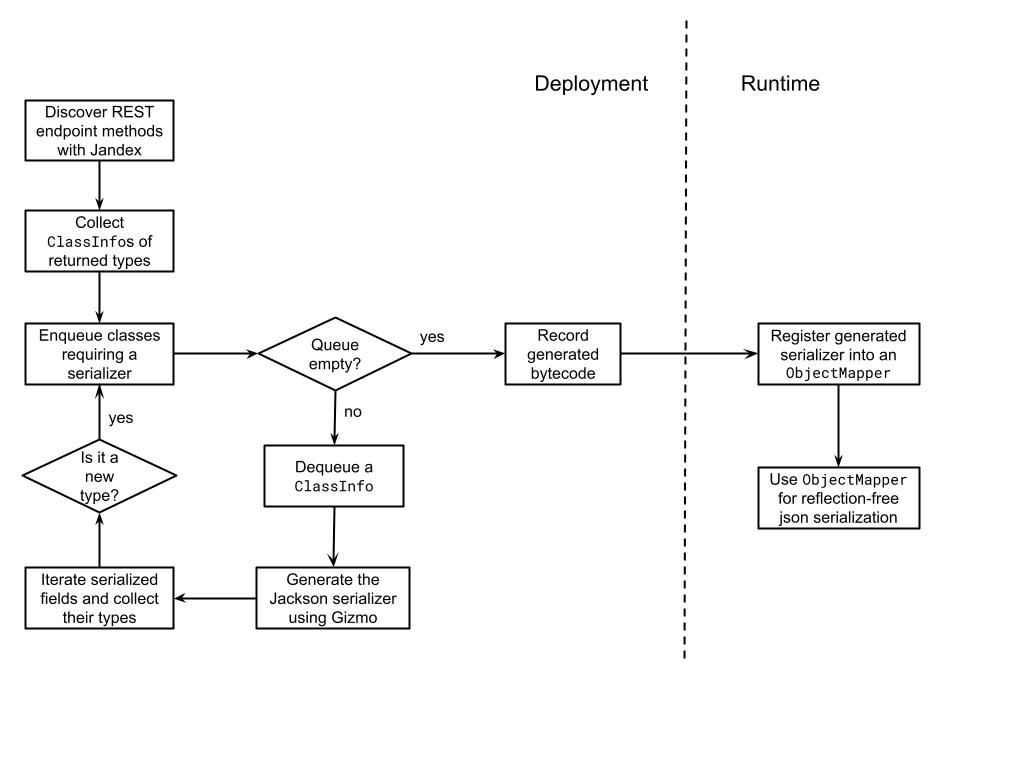
实现无反射 JSON 序列化的策略就非常直接了,但当然,如果 Quarkus 扩展能够自动且轻松地生成和注册这些序列化器,那就太好了。实现这一目标的第一步是在部署时发现我们需要为哪些类生成这些序列化器。在我们的例子中,它们是应用程序中所有 REST 端点返回的类,但当然,相同的方法可以扩展到更广泛的范围。
使用 Jandex 发现和索引要序列化的类
一般来说,Bean 发现由 Quarkus 执行,它通过Jandex索引所有属于 CDI 进程的 Bean。由于它查找所有具有Bean 定义注解的 Bean 类,因此这已经包括了所有公开一个或多个 REST 端点的服务,这些服务必须具有此类注解。这意味着所有端点默认都已发现。更好的是,quarkus-rest 扩展已经收集了 `ResteasyReactiveResourceMethodEntriesBuildItem` 中的每个 REST 方法的条目。
这里,这些条目中的每一个都包含一个 Jandex `MethodInfo` 实例,该实例携带了关于实现特定 REST 端点的 Java 方法签名的所有必需的离线反射信息。正如预期的那样,我们对这些方法返回的类型感兴趣,因为这些是将在响应 REST 端点调用时需要转换为 JSON 的对象的类。
现在我们有了开始开发一个`BuildStep`的所有构建块,该 `BuildStep` 收集(无重复)所有这些返回类型(表示为 Jandex `ClassInfo`)并将它们传递给另一个负责为每个类型生成 Jackson 序列化器的字节码的服务。
@BuildStep
public void handleEndpointParams(ResteasyReactiveResourceMethodEntriesBuildItem resourceMethodEntries, JaxRsResourceIndexBuildItem jaxRsIndex) {
IndexView indexView = jaxRsIndex.getIndexView();
Map<String, ClassInfo> jsonClasses = new HashMap<>();
for (ResteasyReactiveResourceMethodEntriesBuildItem.Entry entry : resourceMethodEntries.getEntries()) {
MethodInfo methodInfo = entry.getMethodInfo();
ClassInfo returnClassInfo = indexView.getClassByName(methodInfo.returnType().name());
if (returnClassInfo != null) {
jsonClasses.put(returnClassInfo.name().toString(), returnClassInfo);
}
}
if (!jsonClasses.isEmpty()) {
// TODO: generate serializers for each returned type
}
}其中 `JaxRsResourceIndexBuildItem` 提供了 Jandex `IndexView`,它允许访问 Jandex 收集和索引的所有反射信息。由于我们已经知道 JSON 序列化将由 rest-jackson 扩展触发,因此方便地将这个新的 `BuildStep` 添加到该扩展中已有的 BuildStepsProcessor中。
使用 Gizmo 生成 Jackson 序列化器
此时,我们知道需要自动生成实现 Jackson 序列化器的字节码的类,这与在讨论如何自定义 Jackson 序列化时所描绘的类似。
Quarkus 在许多需要执行某些字节码生成的情况下大量使用Gizmo。字节码生成是一项相对低级的任务,因此使用 Gizmo 这样的库,它提供了一个方便的高级 API,抽象了许多底层复杂性,在实际执行这项困难的任务时,以合理的生产力水平并保持代码的可读性和可维护性,几乎是强制性的。
这次我们也不例外,因此对于上一步中收集的每个 Jandex `ClassInfo`,Gizmo 都用于生成一个扩展 Jackson 的 `StdSerializer` 的类的字节码,其名称等于要序列化的 Bean 的名称加上 `$quarkusjacksonserializer` 后缀。
public void generate(ClassInfo classInfo) {
String pojoClassName = classInfo.name().toString();
String generatedClassName = pojoClassName + "$quarkusjacksonserializer";
try (ClassCreator classCreator = new ClassCreator(
new GeneratedClassGizmoAdaptor(generatedClassBuildItemBuildProducer, true), generatedClassName, null,
StdSerializer.class.getName())) {
// TODO: generate the serialize method for the given pojo
}
}不深入细节,这个序列化器的核心逻辑包含在 `serialize` 方法中,该方法可以如下生成:
String JSON_GEN_CLASS_NAME = JsonGenerator.class.getName();
// public void serialize(Object var1, JsonGenerator var2, SerializerProvider var3) throws IOException { ...
MethodCreator serialize = classCreator.getMethodCreator("serialize", "void", "java.lang.Object", JSON_GEN_CLASS_NAME, "com.fasterxml.jackson.databind.SerializerProvider");
serialize.setModifiers(ACC_PUBLIC);
serialize.addException(IOException.class);
// jsonGenerator.writeStartObject();
MethodDescriptor writeStartObject = MethodDescriptor.ofMethod(JSON_GEN_CLASS_NAME, "writeStartObject", "void");
serialize.invokeVirtualMethod(writeStartObject, jsonGenerator);
// TODO: generate fields serialization
// jsonGenerator.writeEndObject();
MethodDescriptor writeEndObject = MethodDescriptor.ofMethod(JSON_GEN_CLASS_NAME, "writeEndObject", "void");
serialize.invokeVirtualMethod(writeEndObject, jsonGenerator);
serialize.returnVoid();通过查询 `ClassInfo`,可以迭代所有要序列化的字段及其访问器方法,以便生成将每个字段序列化为 JSON 的代码。例如,如果 `valueHandle` 是要序列化的对象的句柄,它是 `serialize` 方法签名的一个参数,而 `getterMethod` 是返回数字字段的 `MethodInfo`,则用于生成该字段序列化的相应代码可能如下所示:
// int number = value.getNumber()
ResultHandle fieldValueHandle = serialize.invokeVirtualMethod(MethodDescriptor.of(getterMethod), valueHandle);
// jsonGen.writeNumberField("number", number);
MethodDescriptor writerMethod = MethodDescriptor.ofMethod(JSON_GEN_CLASS_NAME, "writeNumberField", "void", "java.lang.String", "java.lang.Integer");
serialize.invokeVirtualMethod(writerMethod, jsonGenerator, serialize.load(fieldName), fieldValueHandle);请注意,这样做时,决定一个字段是否应该被序列化以及如何序列化的逻辑完全绕过了 Jackson 中实现的逻辑,并且有时可能与其不同。特别是,用户可以通过一些特定的 Jackson 注解显式修改此行为。为了安全起见,当序列化器生成器遇到任何这些注解时,它只会放弃为包含它的特定类生成序列化器。在这种情况下,该类的序列化将使用 Jackson 正常使用的基于反射的机制来执行。
实际上,我认为这是一个缺陷,我尝试过看看是否可以在某种程度上也为这些序列化器生成重用 Jackson 的逻辑。如此处所讨论的,主要问题是像 Jackson 这样的库,以及绝大多数 Java 框架,并没有像 Quarkus 那样清晰地分离部署和运行时。但这同时也展示了 Quarkus 中实现的这种分离的明显优势,它允许开发其他工具无法实现的功能和优化。
最后,我们还需要考虑到在遍历类的字段时,序列化器生成器也很可能会遇到属于应用程序业务域的其他类型。在我们最初的示例中,`Customer` 有一个 `Address`,一个 `List<Person>`(她的孩子)和一个 `CreditCard[]`。当这种情况发生时,这些新类型会被添加到要生成另一个序列化器的 `ClassInfo` 队列中。整个字节码生成过程仅在队列为空时终止。
在此过程结束时,所有新创建的类都将被传递回 `BuildStep`,然后由 `BuildStep` 在 `ResteasyReactiveServerJacksonRecorder` 中记录它们,从而在运行时也可以使用它们。
@BuildStep
@Record(ExecutionTime.STATIC_INIT)
public void handleEndpointParams(CombinedIndexBuildItem index,
ResteasyReactiveServerJacksonRecorder recorder,
BuildProducer<GeneratedClassBuildItem> generatedClassBuildItemBuildProducer) {
Map<String, ClassInfo> jsonClasses = new HashMap<>();
// ... classes to be serialized discovery [omitted]
if (!jsonClasses.isEmpty()) {
JacksonSerializerFactory factory = new JacksonSerializerFactory(
generatedClassBuildItemBuildProducer, index.getComputingIndex());
factory.create(jsonClasses.values())
.forEach(recorder::recordGeneratedSerializer);
}
}因此,有必要向 `BuildStep` 添加 `@Record` 注解,以指示它也输出记录的字节码。这结束了对实现此新功能所需所有步骤的描述,这些步骤可以按如下方式进行可视化汇总。
使其可选
由于无法重用 Jackson 用于决定是否以及如何序列化特定字段的任何启发式方法,并且如前所述,仍然可能存在生成序列化器产生的结果与 Jackson 使用反射所产生的不同的一些边缘情况,我们决定暂时默认禁用此功能,并允许用户选择加入。考虑到实现此新功能的所有代码都包含在一个 `BuildStep` 中,通过条件步骤包含可以轻松实现这一点。
为此,只需使用 `@ConfigMapping` 注解将配置映射到接口即可:
@ConfigMapping(prefix = "quarkus.rest.jackson.optimization")
@ConfigRoot(phase = ConfigPhase.BUILD_TIME)
public interface JacksonOptimizationConfig {
@WithDefault("false")
boolean enableReflectionFreeSerializers();
}并且还要有一个实现 `BooleanSupplier` 来读取该配置:
class IsReflectionFreeSerializersEnabled implements BooleanSupplier {
JacksonOptimizationConfig config;
@Override public boolean getAsBoolean() {
return config.enableReflectionFreeSerializers();
}
}这样,`BuildStep` 仅在该供应商返回 true 时才会被启用。
@BuildStep(onlyIf = IsReflectionFreeSerializersEnabled.class)通过这种方式,此优化默认处于关闭状态(注意布尔方法上的 `@WithDefault("false")` 注解),可以通过简单地添加标志来启用:
quarkus.rest.jackson.optimization.enable-reflection-free-serializers=true到 `application.properties` 配置文件。通过最后这个更改,完整的 `BuildStep` 的最终代码可以在此处找到。
投入使用并衡量结果
现在所有开发工作都已完成,让我们尝试将其用于我们开始时的相同基准测试,并检查此更改是否能带来我们所期望的真实性能提升。首先,有必要通过在 Quarkus `application.properties` 文件中设置上述标志来启用此功能。此外,设置第二个标志以启用 Quarkus 转储部署时生成的反编译字节码也很有用:
quarkus.rest.jackson.optimization.enable-reflection-free-serializers=true
quarkus.package.decompiler.enabled=true事实上, thanks to this second flag, after having recompiled our application, it is possible to find the bytecode of the generated classes under the folder `target/decompiled/generated-bytecode`
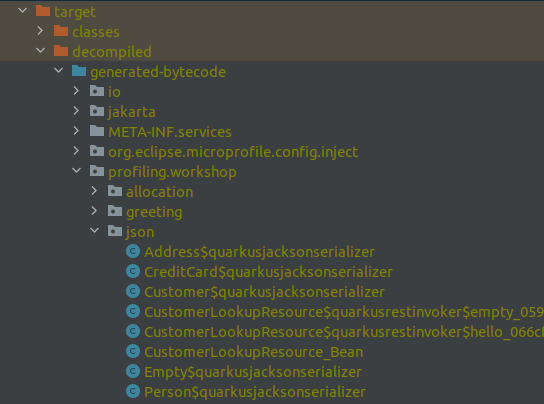
在这里,除了 Quarkus 为执行无反射的 REST 端点调用而生成的代码之外,您还可以看到所有类,它们以 `$quarkusjacksonserializer` 结尾,实现了我们领域中所有类的无反射 JSON 序列化。例如,对于 `Customer` 类,它会生成如下所示的 Jackson `StdSerializer` 实现。
public class Customer$quarkusjacksonserializer extends StdSerializer {
public Customer$quarkusjacksonserializer() {
super(Customer.class);
}
public void serialize(Object var1, JsonGenerator var2, SerializerProvider var3) throws IOException {
Customer var4 = (Customer)var1;
var2.writeStartObject();
Address var5 = var4.getAddress();
var2.writePOJOField("address", var5);
List var6 = var4.getChildren();
var2.writePOJOField("children", var6);
CreditCard[] var7 = var4.getCreditCards();
var2.writePOJOField("creditCards", var7);
double var9 = var4.getIncome();
String[] var8 = new String[]{"admin"};
if (JacksonMapperUtil.includeSecureField(var8)) {
var2.writeNumberField("income", var9);
}
int var11 = var4.getAge();
var2.writeNumberField("age", var11);
String var12 = ((Person)var4).getFirstName();
var2.writeStringField("firstName", var12);
String var13 = ((Person)var4).getLastName();
var2.writeStringField("lastName", var13);
var2.writeEndObject();
}
}正如之前预期的那样,在启用此优化后再次运行基准测试,我得到了以下结果:
Profiling for 20 seconds
Done
Thread Stats Avg Stdev Max +/- Stdev
Latency 102.25μs 70.14μs 19.66ms 92.95%
Req/Sec 90045.27 15073.98 103537.00 97.56
3691856 requests in 40.001s, 1.48GB read
Requests/sec: 92294.09
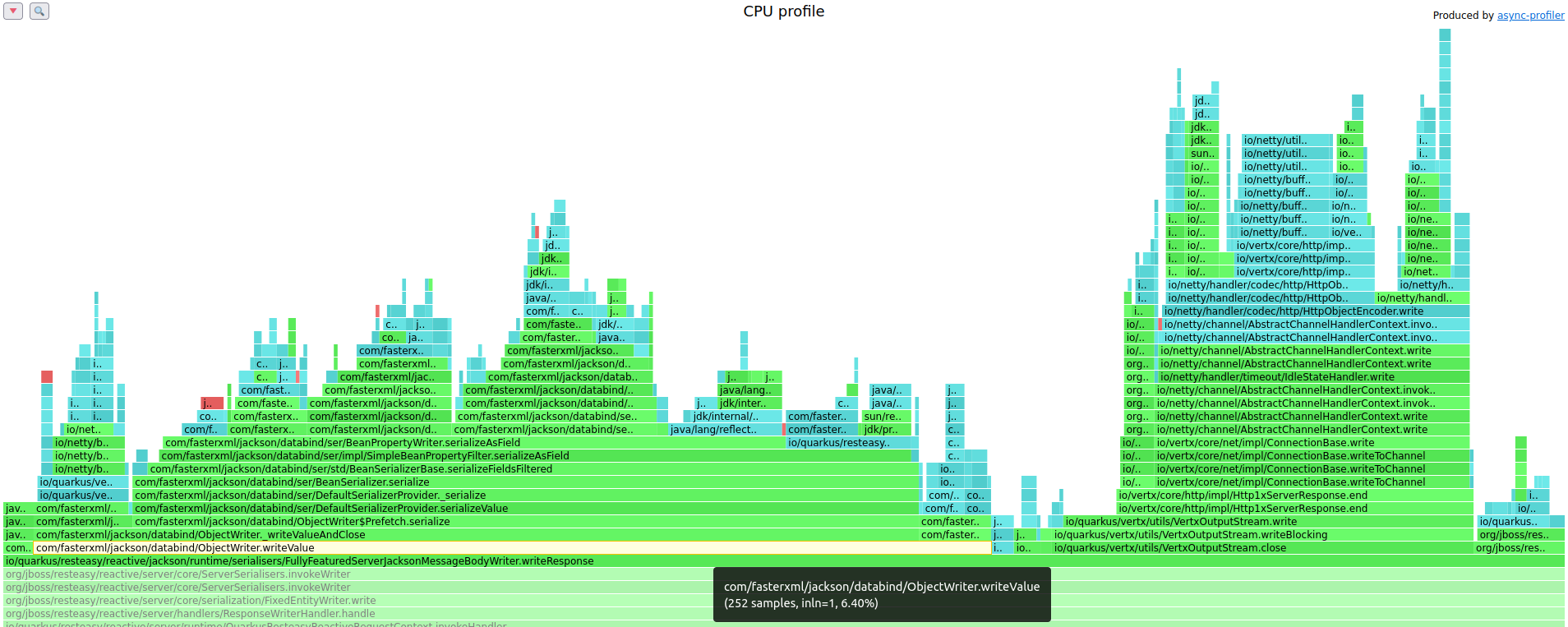
Transfer/sec: 37.94MB这次 Quarkus 每秒可以处理超过 92K 的请求,而之前是 81K,这是一个相当令人感兴趣的改进。最后,相应的火焰图也有助于理解这种改进:其中没有 Java 反射使用的痕迹,现在 `ObjectWriter::writeValue` Jackson 方法的采样次数仅为 193 次,而不是之前观察到的 252 次。
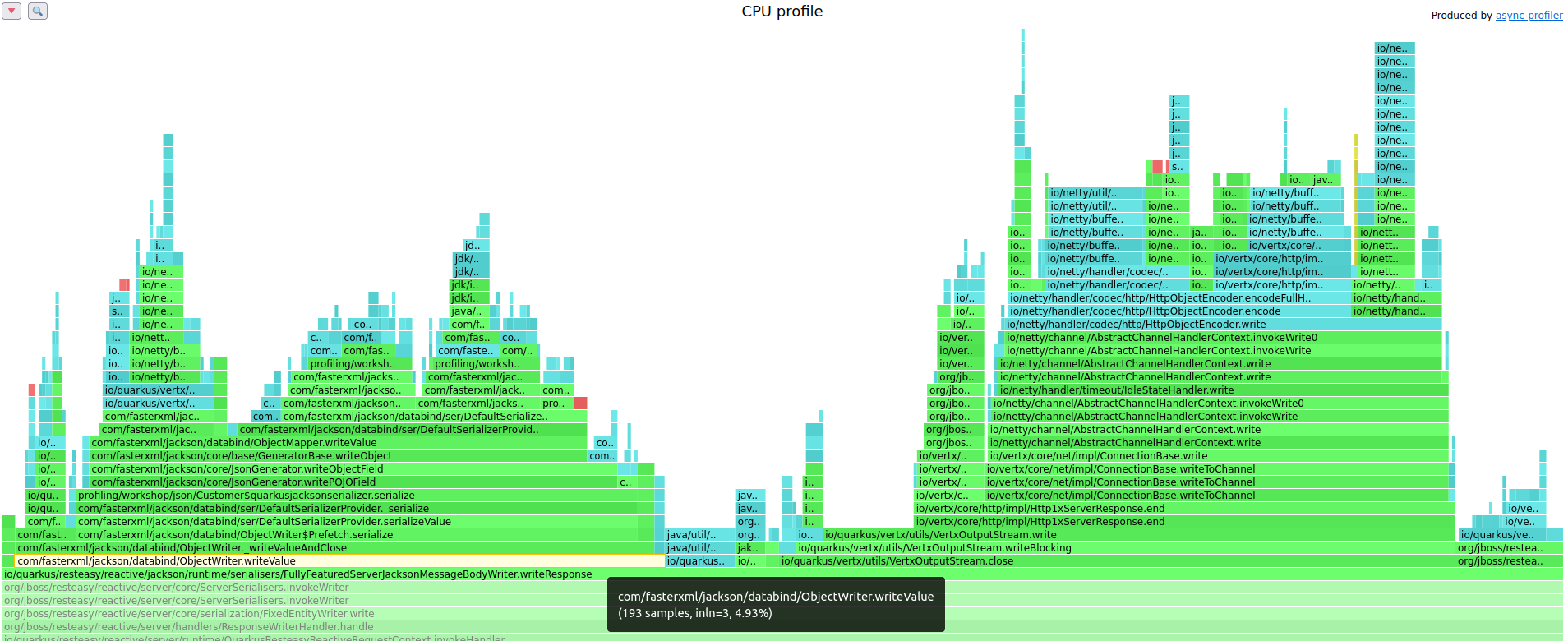
事实上,在这种情况下,所有对象的序列化,即 REST 端点返回的 `Customer` 实例的序列化以及它引用的所有其他对象的序列化,现在都由部署阶段生成的序列化器执行,这些序列化器的类名以 `$quarkusjacksonserializer` 结尾,并在最后一个火焰图中以紫色突出显示。