使用 NativeJDB 调试原生编译的 Java 代码


联合撰写:Ansu Varghese,IBM 研究软件工程师
合作者
Max Andersen, Dimitris Andreadis, Andrew Dinn, Stuart Douglas, Jason Greene, David Grove, David Lloyd, Thomas Qvarnstrom, Foivos Zakkak, Galder Zamarreno (IBM Research and Red Hat)
Quarkus 是一个云原生 Java 开发框架,它允许将 Java 代码映射到 Kubernetes 容器并进行原生编译。 原生编译对于无服务器计算非常有用,它避免了在容器中运行 JVM 的开销,并允许我们直接执行无服务器代码。调试原生编译的代码并非易事。由于广泛的代码优化,以及原生编译与非原生编译代码中使用的库的差异,它可能与原始 Java 源代码大相径庭。在某些情况下,有必要同时查看源代码和汇编代码以更好地理解程序,这进一步加剧了调试的复杂性。
可以使用 GDB(一款 C/C++ 调试器)结合像 Emacs 这样的工具来调试原生可执行文件,从而单步执行源代码。然而,Java 开发人员可能不熟悉这些工具。最近,已开发出适用于 VSCode 和 IntelliJ 的扩展来缓解此问题。这两种工具都特定于它们扩展的 IDE,并且由于 Java 原生编译器的当前限制,需要在使用 Linux 环境中。
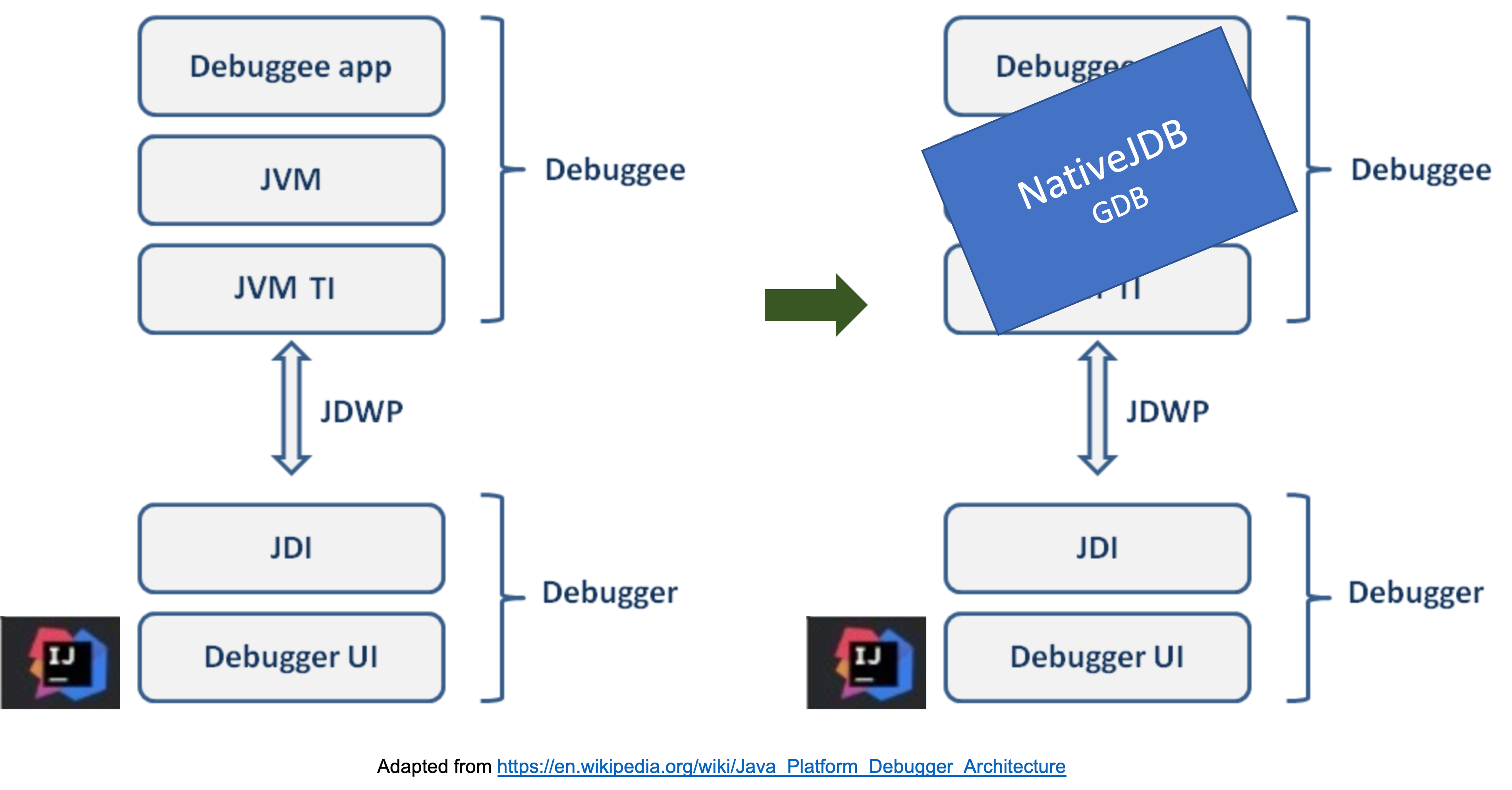
NativeJDB 是一个**开源**工具,支持原生编译 Java 代码的**远程调试**。原则上,这允许从任何支持 Java 平台调试器架构 (JPDA) 的 IDE(如 IntelliJ、Eclipse 或 VSCode)进行调试。远程附加意味着用户可以在**任何操作系统**上启动调试会话,而 NativeJDB 进程本身在 Linux 容器中运行。我们的挑战在于弥合 JPDA 和 GDB 之间的差距,这两种堆栈通常不相互通信!为了实现这一点,我们基本上是在教 GDB 能够理解 Java 调试线协议 (JDWP),该协议由 IDE 用于与 Java 调试器进行通信。
在编写 Quarkus 代码时,开发人员有机会在原生编译之前使用常规 Java 调试器查找错误。当原生可执行文件的行为与在 JVM 上执行程序时的行为不同时,NativeJDB 非常有用。它可以用于探索优化和库差异,这些差异可能导致行为异常。NativeJDB 不特定于 Quarkus,可用于调试任何原生编译的 Java 代码。
架构和实现
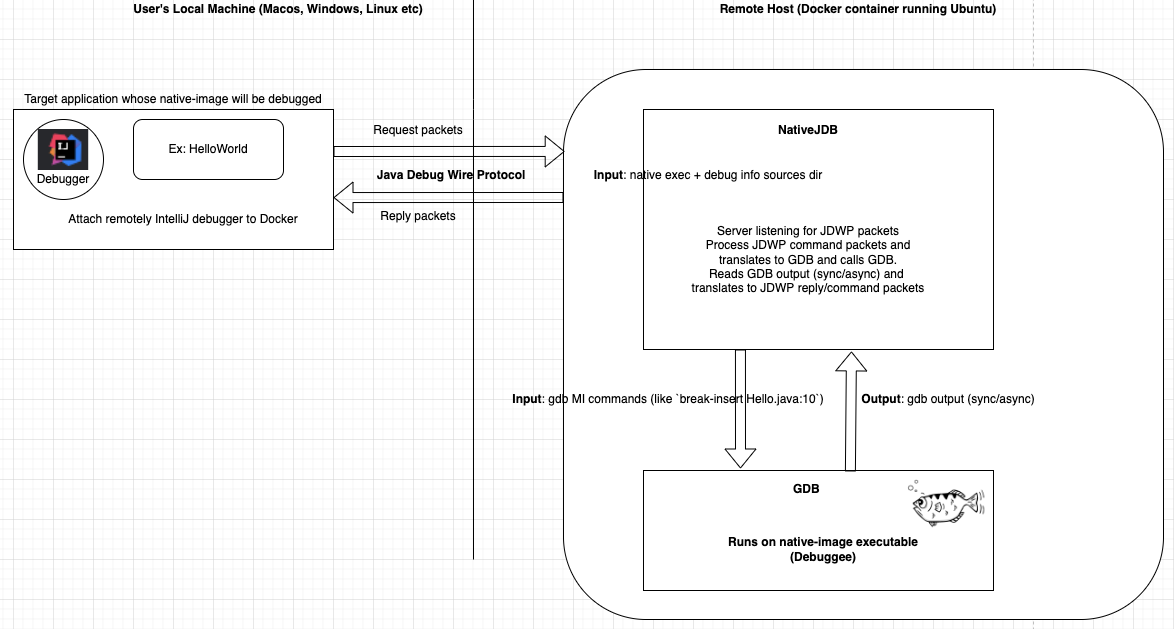
NativeJDB 是一个包装 GDB 的 Java 进程,GDB 本身包装了原生可执行文件,它充当一个理解 JDWP 协议的服务器。它类似于用于控制和调试正在运行的 Java 进程的 JDWP 代理。在这种情况下,用户可以附加到该进程并开始调试它。NativeJDB 的使用方式类似:启动后,用户使用 IDE 的远程调试配置附加到它。
然后,IDE 使用 JDWP 与 NativeJDB 通信。在初始握手和问候(如功能和可用类集)之后,该协议允许用户操作 IDE 的界面,从而触发将适当的 JDWP 数据包发送到 NativeJDB。这些数据包由 NativeJDB 解析,并转换为 GDB-MI 命令。我们使用 MI 接口与 GDB 通信,因为它是构建 GDB 之上工具的推荐接口。然后,GDB 对这些命令做出响应,并将响应转换回 JDWP 数据包并发送回 IDE。
IDE 和 GDB 之间的通信可以是同步和异步的,包括错误消息。在某些情况下,来自 IDE 的命令可能导致同步和异步响应。例如,设置断点会得到同步响应,但相应的断点命中是 NativeJDB 发送给 IDE 的异步事件。原则上,NativeJDB 可与任何具有 JDWP 实现的 IDE 一起使用,但它主要在 IntelliJ 上进行了测试并有效。它也不需要对现有 IDE 进行任何更改或扩展,并且可与 IntelliJ 的**社区版和商业版**一起使用。
如今,GraalVM 和 qbicc 中的原生映像构建器在 Linux 环境中生成调试信息,并将源映射到原始 Java 源代码(其他平台的支持也正在进行中)。NativeJDB 的架构允许用户在运行于任何操作系统的 IDE 中启动调试会话,并附加到运行于 Linux 容器中的 NativeJDB 进程。因此,它一开始就不需要 Linux。它也适用于 GraalVM 的**社区版和商业版**。
NativeJDB 由几个不同的组件组成。我们使用 Docker 来构建原生可执行文件,并为被调试的 Java 应用程序生成调试信息。我们的 Docker 设置使用 Ubuntu 操作系统。NativeJDB 的前端是一组类,用于解析和构建 JDI 数据结构。其后端解析和构建对应于与 GDB 通信的数据结构。
NativeJDB 一直在使用一个脚手架 JVM 来帮助它获取某些静态信息并加速开发。因此,目前 NativeJDB 除了运行原生可执行文件外,还以 Java 进程的形式启动程序。它附加到该进程并暂停它以获取有关程序的通用静态信息。将来,我们将删除这个脚手架,并用来自 GDB 的信息替换它,尽管它在快速原型设计中非常有用。
NativeJDB 实战!
要开始,您需要以下仓库,并遵循每个仓库中的说明
观看以下视频,了解 NativeJDB 的实战!
观看此视频,了解 NativeJDB 在 Quarkus 入门应用程序上的运行情况
特性
-
能够在编辑器中显示 Java 源代码并单步执行代码
-
适用于 IntelliJ 和 Java11
-
适用于 GraalVM 的原生编译映像
-
适用于 Qbicc 的原生编译映像(开发中)
-
使用 IDE 的调试控制台本身的调试功能
-
暂停 / 继续
-
设置断点(插入/启用)
-
清除断点(删除/禁用)
-
单步执行 / 进入 / 返回(开发中)
-
IDE 调试器窗格中的堆栈帧信息
-
变量(局部+静态)值(开发中)
-
堆栈帧中的汇编代码视图(开发中)
-
多线程和线程信息
-
NativeJDB 不支持热代码替换。此外,目前运行时间很短的程序需要 Thread.sleep()。这是因为 NativeJDB 目前使用脚手架 VM,并且需要一些时间来附加和暂停它。当我们将来摆脱脚手架时,这个问题将消失。此外,还有一个已知问题,即在某些情况下,循环中的断点只能工作一次(与此 graalvm 问题有关),并且单步操作有时会继续。
