使用 Mutiny 处理分页 API

在 Mutiny 的早期,我的朋友 Alex 向我提出了一个有趣的问题。Alex 想以响应式的方式从 REST 服务中检索数据。到目前为止,这都不是问题,我们的工具箱里有这一切。但是,该服务和许多服务一样,正在使用分页。啊!这让事情变得更棘手了。Alex 想检索所有项目并将它们作为流消费,但你无法一次性检索所有项目。你需要为每一页调用服务,提取项目并将它们馈入流。
那么,如何在响应式的方式下实现这一点并构建一个合适的项目流而不至于精神错乱?让我们来看看!
Punk API
首先,我们需要一个 API。Alex 向我介绍了 Punk API,这是一个检索啤酒的 REST API。这很有趣,而且更好的是,它使用了分页。我们得到了我们的 API!
如果你调用 https://api.punkapi.com/v2/beers?page=1,你会得到一个 JSON 数组,如下所示:
[
{
first beer
},
{
second beer
},
// ...
]我将不讨论每个对象的具体内容,文档页面对此做了很好的介绍。让我们专注于分页方面。首先,我们传递了 page 查询参数,表明我们想要哪一页。通常,当你检索一页时,API 会提供一种方式来知道下一页是否存在(JSON 文档中的特殊字段或 HTTP 标头),但 Punk API 没有提供任何提示。因此,要检索所有啤酒,我们需要依次调用第 1 页、第 2 页、第 3 页…… 的服务,直到返回的 JSON 数组为空。
在命令式世界中,要检索所有啤酒,你会这样做:
List<Beer> beers = ...;
int page = 1;
List<Beer> batch = ...
do {
batch= getBeersFromPage(page);
beers.addAll(batch);
page = page + 1;
} while (! batch.isEmpty());我们如何在响应式的方式下实现同样的目标并构建一个啤酒流呢?
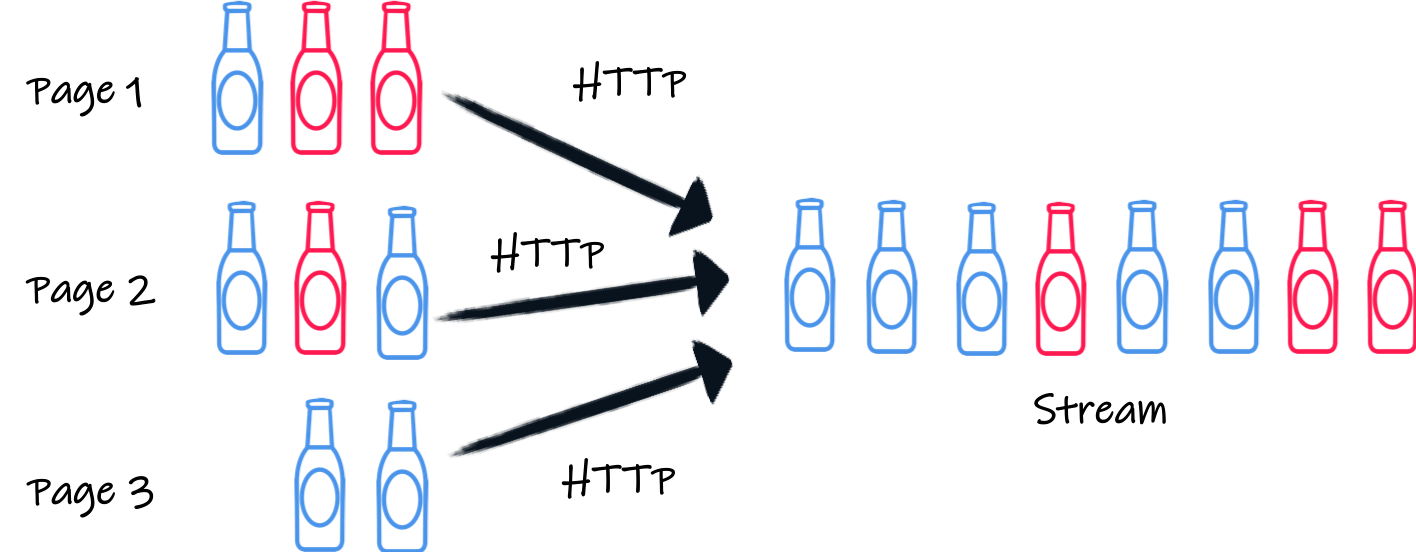
让我们一步一步来。
检索单页
首先,我们需要看看如何检索单页。我将使用 Vert.x Web Client,但你可以使用任何提供 Mutiny API 的响应式 HTTP 客户端。
// Create the client
WebClient client = WebClient.create(vertx, new WebClientOptions()
.setDefaultHost("api.punkapi.com")
.setDefaultPort(443)
.setSsl(true)
);
// Retrieve the first page
Uni<List<Beer>> uni = client.get("/v2/beers?page=1")
.send()
.onItem().transform(Pagination::toListOfBeer);这段代码创建了 Web Client。然后,我们使用该客户端检索第一页。
当我们收到结果 (onItem) 时,我们将 JSON 数组转换为一个啤酒列表。
让我们将这段代码提取到一个方法中,并将页码作为参数
private static Uni<List<Beer>> getPage(WebClient client, int page) {
return client.get("/v2/beers?page=" + page)
.send()
.onItem().transform(Pagination::toListOfBeer);
}到目前为止,一切顺利。
检索多页
所以,现在我们知道如何检索单页并从中提取项目了。我们只需要为每一页重复这个操作,并提供一个流。
Mutiny 提供了一个方法,通过多次重复一个 Uni 来创建一个 Multi。在底层,它调用一个返回 Uni 的方法并对其进行订阅。但我们需要实现进度,并传递当前页码。Mutiny 提供了存储状态的可能性,以便让创建 Uni 的方法递增页码。
Multi.createBy().repeating().uni(AtomicInteger::new, page ->
getPage(client, page.incrementAndGet())
)上面的代码创建了一个流,其中包含 getPage 方法返回的 Unis 发出的项目。每次我们都会递增页码(存储在 AtomicInteger 中)。因此,它会检索第 1、2、3 页……,并且每次都会将收到的 List<Beer> 发送到下游。
然而,在某个时候,我们必须停止。正如我们之前所说,当返回的列表为空时,我们可以停止。
Multi<List<Beer>> multi = Multi.createBy().repeating().uni(AtomicInteger::new, page ->
getPage(client, page.incrementAndGet())
)
.until(List::isEmpty);until 子句指示何时必须停止迭代。它接收检索到的列表(由 getPage 生成),当这个列表为空时,它会停止重复。如果列表仍然包含啤酒,它会检索下一页。
解包啤酒
我们现在有一个列表流,每个列表都包含一组啤酒。我们快完成了,但 Alex 想要一个啤酒流。所以我们需要解包啤酒。
实现这一目标的第一种方法是使用 transformToMultiAndConcatenate,即为每个列表创建一个包含这些啤酒的新 multi,并将这些 multis 连接起来。
Multi<Beer> multi = Multi.createBy().repeating().uni(AtomicInteger::new, page ->
getPage(client, page.incrementAndGet())
)
.until(List::isEmpty)
.onItem().transformToMultiAndConcatenate(l -> Multi.createFrom().iterable(l));想了解 concatenate?请查看这篇 另一篇博客文章。 |
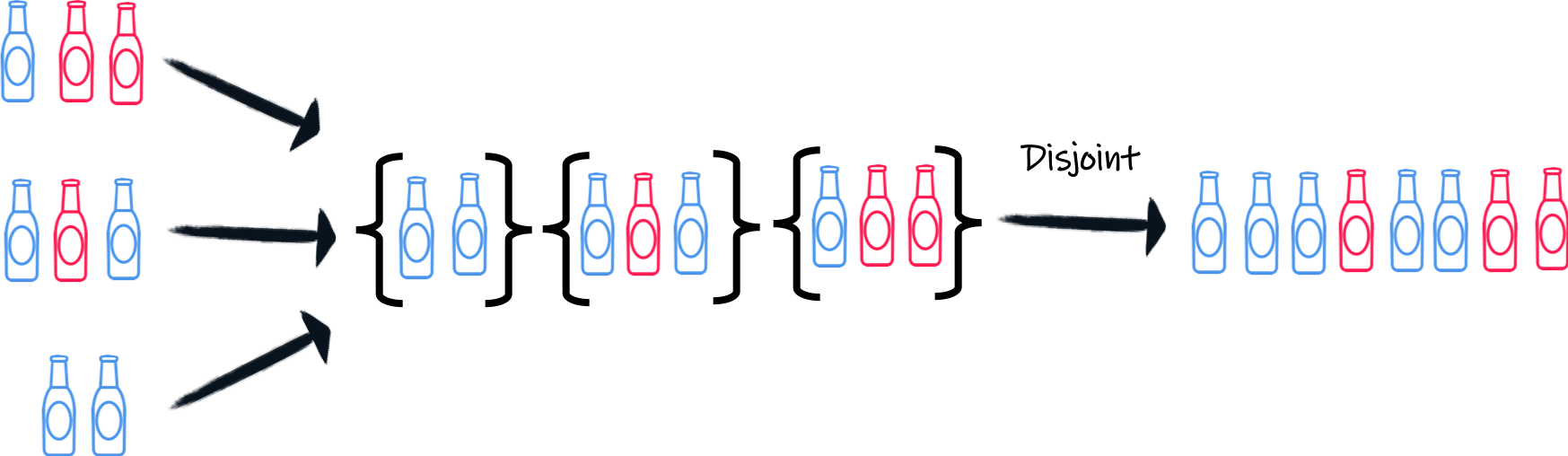
由于这是一个常见操作,Mutiny 提供了 disjoint 方法,它能做完全相同的事情。
Multi<Beer> multi = Multi.createBy().repeating().uni(AtomicInteger::new, page ->
getPage(client, page.incrementAndGet())
)
.until(List::isEmpty)
.onItem().disjoint();这样我们就完成了!
响应式的优势
我们有了流,是时候使用它了!例如,让我们检索描述中包含 "IPA"(我们来赶时髦)的前 10 种啤酒。
multi
.transform().byFilteringItemsWith(beer -> beer.description.contains("IPA"))
.transform().byTakingFirstItems(10);我们流的优势在于我们不会检索每一页。一旦我们获得了足够的啤酒,我们就会停止重复。如何做到?因为它会通知上游它不再需要更多项目(取消),从而停止重复。因此,通过这种方式从分页 API 检索项目可以减少请求数量,从而降低远程服务的负载。
口渴了吗?
想试试这段代码,请查看这个 gist。你可以立即使用 jbang 运行它。
jbang https://gist.github.com/cescoffier/18a326a5c057392bec54d95ec5a06ca6