探讨使用 Mandrel 23.0 生成的本机可执行文件为何比使用 Mandrel 22.3 生成的更大

从 Quarkus 3.2 开始,默认的 Mandrel 版本已从 22.3 更新到 23.0。
此更新带来了许多错误修复以及新功能,例如
- 使用
perf和gdb改进了对性能分析和调试的支持。 - 对本地可执行文件中包含的监控功能进行更精细控制。
- 支持更多 JFR 事件。
然而,它也带来了一个不受欢迎的副作用。使用 Mandrel 23.0 生成的本地可执行文件比使用 Mandrel 22.3 生成的要大。为了更好地理解原因,我们进行了彻底的分析,将大小增加归因于 Mandrel 代码库中的特定更改。
简而言之
根据我们的分析,二进制文件大小的增加归因于三个不同的更改,这些更改都有充分的理由。
- 跳过具有副作用的反射方法的常量折叠.
- 减少串行 GC 写屏障执行的存储操作数量,以通过减少缓存未命中来提高性能。.
- 启用代码对齐以补偿 Intel 的跳转条件代码(jump conditional code)的性能损失。.
更好地理解生成的本地可执行文件之间的差异
我们分析的第一步是了解二进制文件大小增加的来源。通常,这种增加归因于以下情况之一:
- 由于更多的代码变得可达,生成了更多的代码。
- 由于更积极的内联,生成了更多的代码。
- 由于更多的对象变得可达,在映像堆中存储了更多数据。
- 由于注册了更多的类型用于反射,需要在映像堆中存储更多数据,从而需要存储更多的代码元数据。
为了进行分析,我们使用了 Quarkus startstop 测试(特别是提交 a8bae846881607e376c7c8a96116b6b50ee50b70),它会生成、启动、测试和停止小型 Quarkus 应用程序,并测量各种与时间相关的指标(例如,首次请求响应时间)和内存使用情况。我们通过以下方式获取测试:
git clone https://github.com/quarkus-qe/quarkus-startstop
cd quarkus-startstop
git checkout a8bae846881607e376c7c8a96116b6b50ee50b70
并使用以下命令进行构建:
mvn clean package -Pnative -Dquarkus.version=3.2.6.Final\
-Dquarkus.native.builder-image=quay.io/quarkus/ubi-quarkus-mandrel-builder-image:jdk-17
将构建器镜像标签更改为 22.3-java17 以使用 Mandrel 22.3 进行构建。
查看构建输出(由 Quarkus 在 target/my-app-native-image-sources/my-app-build-output-stats.json 中生成),两次构建之间的主要差异在于以下指标:
| Mandrel 版本 | 22.3.3.1 | 23.0.1.2 | 增长百分比 |
|---|---|---|---|
| 映像堆大小 | 28807168 | 29499392 | 2.4 |
| 映像代码区 | 27680208 | 29625424 | 7 |
| 映像总大小 | 56826648 | 59467728 | 4.6 |
| 为反射注册的类 | 645 | 4317 | 570 |
表明上述原因 1-4 中的任何一个都有可能。
仪表板
GraalVM 和 Mandrel 提供了 -H:+DashboardAll 和 -H:+DashboardJson 标志,可用于生成包含更多关于生成的本地可执行文件信息的仪表板。生成的仪表板包含许多指标,看起来像这样:
{
"points-to": {
"type-flows": [
...
]
},
"code-breakdown": {
"code-size": [
{
"name": "io.smallrye.mutiny.CompositeException.getFirstOrFail(Throwable[]) Throwable",
"size": 575
},
...
]
},
"heap-breakdown": {
"heap-size": [
{
"name": "Lio/vertx/core/impl/VerticleManager$$Lambda$bf09d38f5d19578a0d041ffd0a524c1cbe1843df;",
"size": 24,
"count": 1
},
...
]
}
}
使用上述标志,我们使用 Mandrel 22.3 和 23.0 生成仪表板并比较结果。
要使用 Mandrel 23.0 生成仪表板,我们使用以下命令:
mvn package -Pnative \
-Dquarkus.version=3.2.6.Final \
-Dquarkus.native.builder-image=quay.io/quarkus/ubi-quarkus-mandrel-builder-image:jdk-17 \
-Dquarkus.native.additional-build-args=-H:+DashboardAll,-H:+DashboardJson,-H:DashboardDump=path/to/23.0.dashboard.json
同样,要使用 Mandrel 22.3 生成仪表板,我们使用以下命令:
mvn package -Pnative \
-Dquarkus.version=3.2.6.Final \
-Dquarkus.native.builder-image=quay.io/quarkus/ubi-quarkus-mandrel-builder-image:22.3-java17 \
-Dquarkus.native.additional-build-args=-H:+DashboardAll,-H:+DashboardJson,-H:DashboardDump=path/to/22.3.dashboard.json
注意:请确保将 path/to/ 更改为您希望存储仪表板 JSON 文件的路径,每个文件大约为 370MB。
分析和可视化数据
为了处理来自仪表板的数据,我们使用了 Jupyter Notebook,就像我们创建本文时一样。要获取 Notebook,请遵循 此链接。
对于那些愿意使用电子表格的人,可以创建一个 CSV 文件以方便在电子表格中进行分析。例如,使用 jq:
jq -r -s '(["Name", "22.3 size", "23.0 size"], (map(."code-breakdown"."code-size") | flatten | group_by(.name) | map({name: .[0].name, size22: .[0].size, size23: .[1].size})[] | [.name, .size22, .size23])) | @csv' 22.3.dashboard.json 23.0.dashboard.json > analysis.csv
从 JSON 文件加载数据
import json
import pandas as pd
# load data from JSON file
with open('22.3.dashboard.json', 'r') as f:
data22_3 = json.load(f)
with open('23.0.dashboard.json', 'r') as f:
data23_0 = json.load(f)
# create dataframes from json data
df22_3 = pd.DataFrame(data22_3)
df23_0 = pd.DataFrame(data23_0)
关键观察
我们希望使用上述数据回答的关键问题是:
- 代码区是否由于编译了更多方法而变大了?
- 代码区是否由于每个方法生成了更多代码而变大了?
- 堆映像是否因为存储了更多对象而变大了?
- 堆映像是否因为存储了更多元数据而变大了?
代码区大小增加
我们首先回答与代码区相关的问题。
代码区是否由于编译了更多方法而变大了?
为了回答这个问题,我们获取了两个已编译方法的列表并比较了它们的大小。
# Get code-size lists from dataframes
code_size_22_3 = df22_3['code-breakdown']['code-size']
code_size_23_0 = df23_0['code-breakdown']['code-size']
print("Compiled methods with 22_3:", len(code_size_22_3))
print("Compiled methods with 23_0:", len(code_size_23_0))
Compiled methods with 22_3: 46298
Compiled methods with 23_0: 46299
结果表明答案是否定的。在这两种情况下,已编译方法的数量相同(相差 1)。因此,代码大小的增加不是因为更多的方法变得可达和被编译。
代码区是否由于每个方法生成了更多代码而变大了?
为了回答这个问题,我们计算了已编译方法之间的百分比差异。
import matplotlib.pyplot as plt
# create dataframes from code_size lists
code_df22_3 = pd.DataFrame(code_size_22_3).rename(columns={'size': 'size-22.3'})
code_df23_0 = pd.DataFrame(code_size_23_0).rename(columns={'size': 'size-23.0'})
# merge dataframes
merged_df = pd.merge(code_df22_3, code_df23_0, on='name', how='outer').fillna(0)
# create column with size increase as percentage skipping entries with 0 size
percentage_increase = lambda row: (
((row['size-23.0'] - row['size-22.3']) / row['size-22.3']) * 100
if row['size-22.3'] > 0 and row['size-23.0'] > 0
else 0
)
merged_df['size-increase'] = merged_df.apply(percentage_increase, axis=1)
我们计算了方法的数量,未更改大小的方法数量,大小增加的方法数量,以及大小减少的方法数量。
total_compiled_methods = len(merged_df)
print(f"Total number of compiled methods: {total_compiled_methods}")
zero_increase_count = (merged_df['size-increase'] == 0).sum()
zero_increase_percent = (zero_increase_count / total_compiled_methods) * 100
print(f"Number of methods that their compiled size remains the same: {zero_increase_count} ({zero_increase_percent:.2f}%)")
positive_increase_count = (merged_df['size-increase'] > 0).sum()
positive_increase_percent = (positive_increase_count / total_compiled_methods) * 100
print(f"Number of methods that their compiled size increased: {positive_increase_count} ({positive_increase_percent:.2f}%)")
negative_increase_count = (merged_df['size-increase'] < 0).sum()
negative_increase_percent = (negative_increase_count / total_compiled_methods) * 100
print(f"Number of methods that their compiled size decreased: {negative_increase_count} ({negative_increase_percent:.2f}%)")
Total number of compiled methods: 48476
Number of methods that their compiled size remains the same: 13947 (28.77%)
Number of methods that their compiled size increased: 33351 (68.80%)
Number of methods that their compiled size decreased: 1178 (2.43%)
结果表明,与使用 Mandrel 22.3 编译相比,使用 23.0 编译的已编译方法中有 68.8% 更大。但大多少?为了回答这个问题,我们打印了大小增加的直方图。
# plot histogram
plt.hist(merged_df['size-increase'], bins="auto")
plt.xlabel('Percentage difference')
plt.ylabel('Frequency')
plt.title('Histogram of percentage difference in code size (full range)')
plt.show()
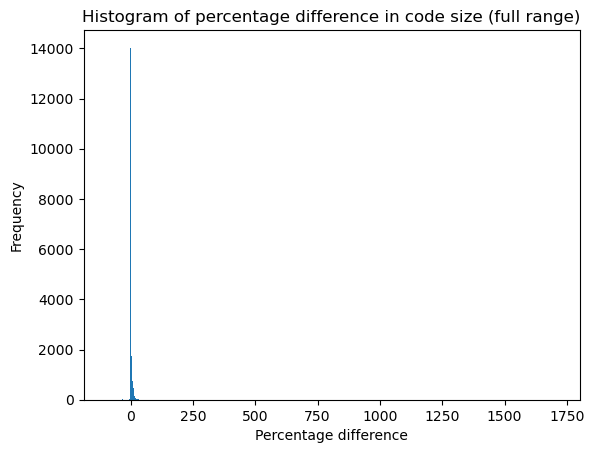
我们观察到,由于大量方法保持相同大小以及一些异常值,直方图难以阅读。因此,我们移除了大小没有变化的方法,并将焦点限制在 [-5, 25] 的范围内。
# create column with size increase as percentage skipping entries with 0 size
zero_filter = lambda row: row['size-increase'] if row['size-increase'] != 0 else None
merged_df['size-increase'] = merged_df.apply(zero_filter, axis=1)
# drop rows with None values
merged_df = merged_df.dropna()
# plot histogram
plt.hist(merged_df['size-increase'], bins="auto")
plt.xlim(-5, 25)
plt.xlabel('Percentage difference')
plt.ylabel('Frequency')
plt.title('Histogram of percentage difference in code size in the range [-5%, 25%] excluding 0%')
# show the plot
plt.show()
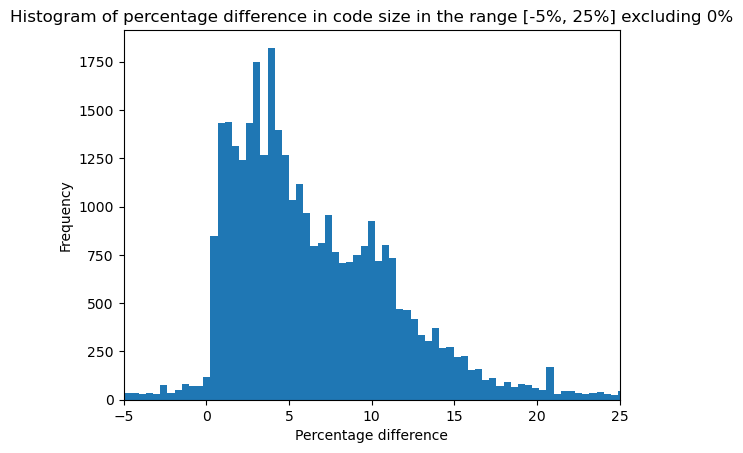
此图显示,大多数受影响的方法的代码大小增加了 0% 到 10%,这与我们在代码区域中观察到的总体大小增加一致。
为什么?
为了了解为什么使用 Mandrel 23.0 编译的相同方法会生成更大的机器代码,我们首先检查了在每种情况下内联了多少方法。为此,我们启用了调试信息生成,使用 `-Dquarkus.native.debug.enabled=true` 参数来构建本地可执行文件。为了确保在使用 Mandrel 22.3 构建时包含内联 DIE,我们还传递了 `-Dquarkus.native.additional-build-args=-H:-OmitInlinedMethodDebugLineInfo` 选项,例如:
mvn clean package -Pnative -Dquarkus.version=3.2.6.Final\
-Dquarkus.native.builder-image=quay.io/quarkus/ubi-quarkus-mandrel-builder-image:jdk-17\
-Dquarkus.native.debug.enabled=true\
-Dquarkus.native.additional-build-args=-H:-OmitInlinedMethodDebugLineInfo
在映像构建完成后,我们使用以下命令计算内联调试信息条目 (DIE) 的数量:
readelf --debug-dump=info quarkus-runner | grep -i "DW_TAG_inlined_subroutine" | wc -l
结果如下表所示:
| Mandrel 版本 | 22.3 | 23.0 | 增长百分比 |
|---|---|---|---|
| 内联方法 | 2798414 | 2817686 | 0.69 % |
虽然它们表明 Mandrel 22.3 和 23.0 之间内联方法的数量略有增加,但这种增加非常小,与总体代码大小的增加不符。
下一步,我们手工挑选了在生成的本地可执行文件中具有不同代码大小的若干方法,并检查了它们的反汇编代码(使用 gdb)。
例如,使用以下命令检查 io.netty.buffer.UnpooledByteBufAllocator 中的 InstrumentedUnpooledUnsafeNoCleanerDirectByteBuf.allocateDirect(int):
(gdb) x/20i 'io.netty.buffer.UnpooledByteBufAllocator$InstrumentedUnpooledUnsafeNoCleanerDirectByteBuf::allocateDirect(int)'
我们发现一个额外的字节来自于两个调用之间的一个额外的 nop。
Mandrel 22.3
sub $0x18,%rsp
cmp 0x8(%r15),%rsp
jbe 0x96ad8f
mov %rdi,0x8(%rsp)
mov %esi,%edi
mov %esi,0x14(%rsp)
call 0xb7e870
nop
call 0x756e10
nop
Mandrel 23.0
sub $0x18,%rsp
cmp 0x8(%r15),%rsp
jbe 0x96ad8f
mov %rdi,0x8(%rsp)
mov %esi,%edi
mov %esi,0x14(%rsp)
call 0xb7e870
nop
nop // <==== extra nop
call 0x756e10
nop
我们在多种方法中观察到这种模式,这表明代码对齐发生了变化。然而,也有一些方法在没有增加 nop 的情况下编译代码大小增加,这暗示代码大小的增加并非由单一更改引起,正如我们在 将二进制大小增加归因于特定代码更改 中所确认的那样。
映像堆大小增加
初步检查后,注意到映像堆大小增加了约 650KB。因此,下一步我们选择回答是否:
- 堆映像是否因为存储了更多对象而变大了?
- 堆映像是否因为存储了更多元数据而变大了?
堆映像是否因为存储了更多对象而变大了?
使用仪表板数据,我们首先检查了两个版本之间映像堆中的对象数量是否存在差异。
# Get heap-size lists from dataframes
heap_size_22_3 = df22_3['heap-breakdown']['heap-size']
heap_size_23_0 = df23_0['heap-breakdown']['heap-size']
# create dataframes from heap_size lists
heap_df22_3 = pd.DataFrame(heap_size_22_3).rename(columns={'size': 'size-22.3', 'count': 'count-22.3'})
heap_df23_0 = pd.DataFrame(heap_size_23_0).rename(columns={'size': 'size-23.0', 'count': 'count-23.0'})
print("Number of objects in image heap with 22.3: ", heap_df22_3['count-22.3'].sum())
print("Number of objects in image heap with 23.0: ", heap_df23_0['count-23.0'].sum())
Number of objects in image heap with 22.3: 340870
Number of objects in image heap with 23.0: 348063
我们观察到,使用 22.3 生成的映像在映像堆中多了约 7000 个(或约 2%)对象。然后我们检查这些额外的对象是否来自不同的已实例化类型。
print("Types in image heap with 22.3:", len(heap_size_22_3))
print("Types in image heap with 23.0:", len(heap_size_23_0))
Types in image heap with 22.3: 3681
Types in image heap with 23.0: 3679
结果表明,映像堆中的类型数量大致相同,这暗示 23.0 在映像堆中实例化了更多相同类型的对象。为了查看哪些类型在映像堆中显示出更大的(堆大小方面)增加,我们运行了:
# merge dataframes
merged_heap_df = pd.merge(heap_df22_3, heap_df23_0, on='name', how='outer').fillna(0)
merged_heap_df['count-diff'] = merged_heap_df['count-23.0'] - merged_heap_df['count-22.3']
merged_heap_df['size-diff'] = merged_heap_df['size-23.0'] - merged_heap_df['size-22.3']
# get top 10 types with the biggest difference in occupied heap size
merged_heap_df.sort_values(by=['size-diff'], ascending=False).head(10)[['name', 'count-diff', 'size-diff']]
| 名称 | 计数差异 | 大小差异 | |
|---|---|---|---|
| 1340 | [B | 2042.0 | 894704.0 |
| 2384 | Ljava/lang/invoke/DirectMethodHandle; | 1293.0 | 71920.0 |
| 2901 | Ljava/lang/String; | 2032.0 | 65024.0 |
| 3684 | Ljdk/internal/module/ServicesCatalog$ServicePr... | 1058.0 | 42320.0 |
| 2582 | [Ljava/lang/Object; | 246.0 | 36472.0 |
| 898 | [Ljava/lang/String; | 9.0 | 28024.0 |
| 1297 | Ljava/lang/invoke/MethodType; | 276.0 | 15456.0 |
| 3238 | Ljava/util/concurrent/ConcurrentHashMap$Node; | 274.0 | 13152.0 |
| 1065 | Ljava/util/HashMap; | 146.0 | 10512.0 |
| 3244 | [Ljava/lang/Class; | 261.0 | 9680.0 |
结果表明字节数组中的字节增加了约 870KB,这不幸地信息量不大,尤其考虑到其他类型的大小在两个版本之间存在显著差异(可能是由于 GraalVM 内部代码更改导致不同的分配模式)。
堆映像是否因为存储了更多元数据而变大了?
正如在 更好地理解生成的本地可执行文件之间的差异 中所示,用于反射的类型数量似乎显著增加(Mandrel 22.3 为 645,Mandrel 23.0 为 4317)。这,以及报告的(在 native-image 输出中)代码元数据增加,最初使我们认为 Mandrel 中存在某些更改导致注册了更多用于反射的类型。最终,正如在 将二进制大小增加归因于特定代码更改 中所讨论的那样,与我们的直觉相反,这种增加与报告的用于反射的类型数量的增加无关,后者是由于 用于度量报告的反射注册类型的方式的修复 有关。相反,映像堆中存储的代码元数据的增加是由于 跳过具有副作用的反射方法的常量折叠,这是 23.0 中引入的一项修复,以防止在折叠使用反射的调用时产生不良影响。
将二进制大小增加归因于特定代码更改
此时,我们对生成的本地可执行文件有哪些不同有了大致的了解,但仍然不知道原因。这种本地可执行文件大小的增加是否物有所值?
为了回答这个问题,我们决定检测导致观察到的行为的代码库更改。为此,我们使用了 git bisect,将 22.3 版本的提交标记为“好”,将 23.0 版本的提交标记为“坏”。对于每个提交,我们都构建了一个 Mandrel 实例并编译了我们的测试应用程序,以查看代码区和堆区的大小。如果大小与 22.3 的大小匹配,我们将提交标记为“好”,否则标记为“坏”。在此过程中,我们注意到有些提交导致的二进制文件大小大于使用 22.3 生成的大小,但小于 23.0。这证实了我们的预期,即二进制文件大小的增加是代码库中不止一项更改的结果。为了减少 git bisect 的成本,我们记下了每个测试提交哈希的代码区和堆区大小。然后,使用这些信息,我们通过重放 git bisect log 的输出来多次重复了 bisect 过程,并更改了我们考虑为“好”的提交,一旦我们确定了导致二进制文件大小增加的第一个、第二个等等更改。
已识别的代码大小增加的原因
上述过程使我们得出结论,二进制文件大小的增加主要是以下三个更改的结果:
-
跳过具有副作用的反射方法的常量折叠:23.0 中引入的一项修复,旨在防止在折叠使用反射的调用时产生不良影响(例如,触发应在运行时初始化的类的编译时初始化)。此更改负责映像堆大小的增加。
-
减少串行 GC 写屏障执行的存储操作数量,以通过减少缓存未命中来提高性能:此更改本质上为每个内联的串行 GC 写屏障实例添加了两个额外的指令,分别是
cmpb $0x0,0x30(%rcx,%rax,1)和je。此更改的目的是避免 GC 写屏障中的不必要存储,以减少缓存行失效并提高性能。根据我们的测量,此更改的总影响在我们的测试案例中增加了约 1MB 的代码区,在使用 Mandrel 22.3 时内联写屏障 90697 次,在使用 Mandrel 23.0 时内联 93686 次。为了测量屏障内联的次数,我们检查了在运行b CardTable.java:91时在gdb中设置的断点位置数量,即在com.oracle.svm.core.genscavenge.remset.CardTable#setDirty中设置断点时。例如:(gdb) b CardTable.java:91 Breakpoint 1 at 0x407574: CardTable.java:91. (93686 locations) -
启用代码对齐以补偿 Intel 的跳转条件代码(Jump Conditional Code)的性能损失:根据 Intel 关于“跳转条件代码(Jump Conditional Code)勘误的缓解措施”的白皮书
软件可以通过优化来补偿此勘误的解决方法对性能的影响,这些优化使代码对齐,使得跳转指令(以及宏融合的跳转指令)不跨越 32 字节边界或结束在 32 字节边界上。这种对齐可以减少或消除由于执行从已解码 ICache 到旧解码管道的转换而导致的性能损失。
因此,此更改导致生成的代码中
nop指令的数量增加,但根据同一份文件,可以带来高达 4% 的性能提升。Intel 观察到,在许多行业标准基准测试中,解决方法对性能的影响范围为 0-4%。在这些基准测试的子组件中,Intel 观察到异常值高于 0-4% 的范围。Intel 未观察到的其他工作负载可能表现不同。Intel 已开发了基于软件的工具来最大程度地减少对可能受影响的应用程序和工作负载的影响。
根据我们的测量,此更改在我们的测试案例中总共影响了约 900KB。
结论
总之,使用 Mandrel 23.0 生成的本地可执行文件与 Mandrel 22.3 相比,大小增加可归因于上述 Mandrel 代码库中的三个特定更改。
尽管这些更改确实导致了本地可执行文件大小的增加,但它们也带来了性能和正确性方面的优势。因此,更大的可执行文件是一种权衡,以确保更好的应用程序性能并避免不良的副作用。
