如何实现 Kafka 序列化器和反序列化器?

当您的应用程序将一个记录写入 Kafka 主题或从 Kafka 主题读取一个记录时,会发生序列化和反序列化机制。序列化过程将您要发送到 Kafka 的业务对象转换为字节。反序列化过程则相反。它接收来自 Kafka 的字节并重新创建业务对象。
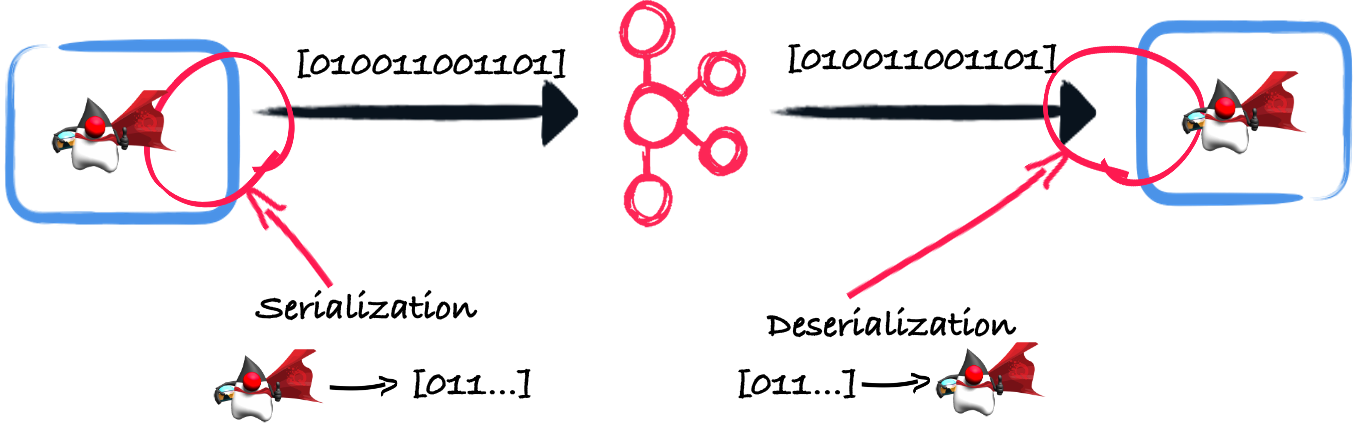
这篇博文探讨了序列化和反序列化的不同方法,并解释了如何实现自定义序列化器和反序列化器。它还重点介绍了 Quarkus 的 Kafka 连接器提供的功能。
为什么我需要自定义序列化器和反序列化器?
Kafka 为常见类型提供了serializers 和 deserializers:String、Double、Integer、Bytes…… 但这对于业务对象来说几乎是不够的,即使是像这样的简单对象
package me.escoffier.quarkus;
public record Hero(String name, String picture) {
}幸运的是,Kafka 允许我们实现自己的。要实现这一点,您需要实现以下接口:
public interface Serializer<T> extends Closeable {
default void configure(Map<String, ?> configs, boolean isKey) { }
byte[] serialize(String topic, T data);
default byte[] serialize(String topic, Headers headers, T data) {
return serialize(topic, data);
}
@Override
default void close() { }
}public interface Deserializer<T> extends Closeable {
default void configure(Map<String, ?> configs, boolean isKey) { }
T deserialize(String topic, byte[] data);
default T deserialize(String topic, Headers headers, byte[] data) {
return deserialize(topic, data);
}
@Override
default void close() { }实现后,您需要配置 Kafka 生产者和消费者的 key 和 value 序列化器和反序列化器。如果您使用的是 Quarkus 的 Kafka 连接器,它看起来会是这样:
mp.messaging.incoming.heroes.value.deserializer=me.escoffier.MyHeroDeserializer
mp.messaging.outgoing.heroes.value.serializer=me.escoffier.MyHeroSerializer但是,不用担心,Quarkus 为您准备了一些神奇的技巧。
在这篇博文的其余部分,我们将使用以下应用程序:
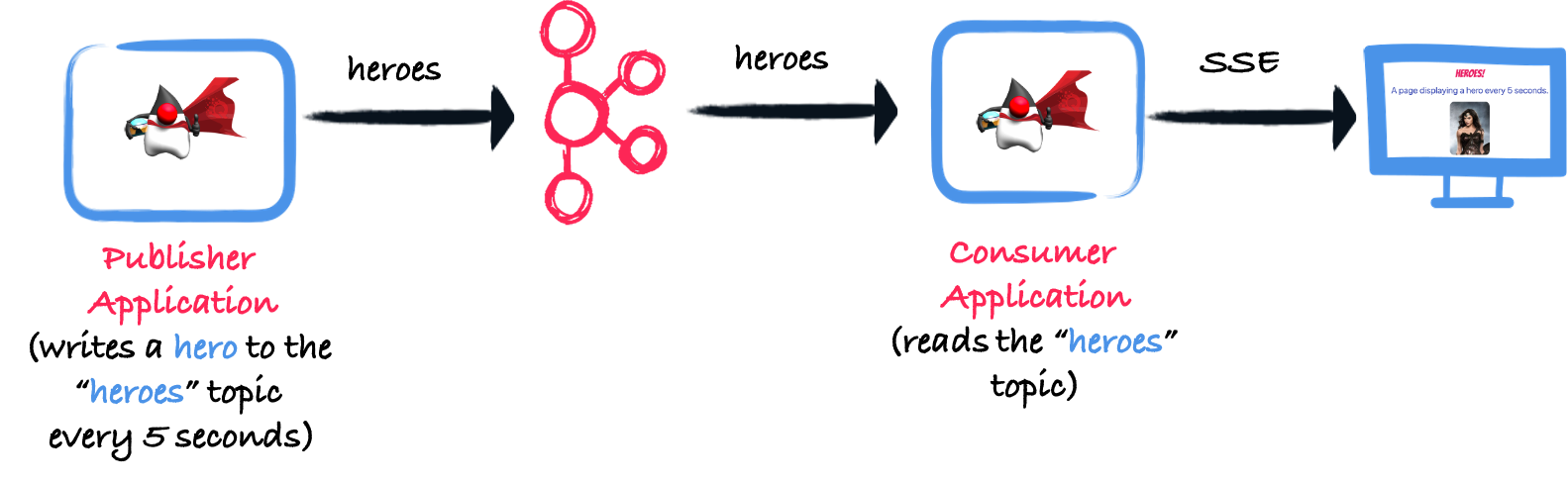
代码可以在 https://github.com/cescoffier/quarkus-kafka-serde-demo 找到。我们将开发三个变体:
-
第一个版本使用 JSON。
-
第二个版本使用 Avro。
-
第三个版本使用自定义(并且是愚蠢的)序列化器和反序列化器。
使用 JSON
在 Kafka 中使用 JSON 非常流行。由于大多数 Web 应用程序都使用 JSON 来交换消息,因此将其与 Kafka 一起使用似乎是一个自然的延伸。
在我们的例子中,这意味着将 Hero 的实例转换为 JSON 文档,然后使用 String serializer。对于反序列化过程,我们将进行相反的操作。要通过 Quarkus 完成此操作,您 **无需** 做任何事情:Quarkus 会为您生成自定义 JSON 序列化器和反序列化器。
在 json-serde 目录 中,您可以找到一个使用 JSON 来序列化和反序列化记录的应用程序版本。它不包含任何自定义代码或配置。Quarkus 会自动检测到您需要写入和消耗 Hero,并为您生成序列化器和反序列化器。它还会为您配置通道。当然,您可以覆盖配置,但这通常是您想要的。
要运行此应用程序,请打开两个终端。在第一个终端中,导航到 json-serde/json-serde-publisher,然后运行 mvn quarkus:dev。在第二个终端中,导航到 json-serde/json-serde-consumer,然后运行 mvn quarkus:dev。然后,在浏览器中打开 https://:8080。每 5 秒钟,就会显示一张新的英雄图片。

使用 Avro
第二种方法使用 Avro。Avro 比(纯)JSON 有几个优点:
-
它是一种二进制的紧凑协议。有效负载会比 JSON 小很多。
-
序列化和反序列化过程要快得多(避免了反射)。
-
消息的格式使用存储在模式注册表中的模式来定义,这支持版本控制并强制执行结构。
最后一点至关重要。要使用 Avro,您需要一个模式注册表。在这篇文章中,我们使用的是 Apicurio,但您也可以使用 Confluent Schema Registry 或 Karapace。Quarkus 为 Apicurio 提供了开发服务,所以您无需做任何事情(只要您可以在机器上运行容器)。
要使用 Avro,我们需要一个模式。在 hero.avsc 中,您可以找到代表我们英雄的模式。
{
"namespace": "me.escoffier.quarkus.avro",
"type": "record",
"name": "Hero",
"fields": [
{
"name": "name",
"type": "string"
},
{
"name": "picture",
"type": "string"
}
]
}Avro 依赖于代码生成。它处理模式以生成具有定义字段和序列化/反序列化方法的 Java 类。
虽然通常使用代码生成是一个额外的步骤,但借助 Quarkus,它是内置的!一旦您在 src/main/avro 中有一个模式,它就会为您生成代码,您就可以开始使用生成的类了。
在 AvroPublisherApp 和 AvroConsumerResource 中,我们使用了从模式生成的 Hero 类。例如,消费者应用程序看起来像这样:
package me.escoffier.quarkus;
import io.smallrye.mutiny.Multi;
import me.escoffier.quarkus.avro.Hero; // Generated class
import org.eclipse.microprofile.reactive.messaging.Channel;
import org.jboss.resteasy.reactive.RestStreamElementType;
import javax.ws.rs.GET;
import javax.ws.rs.Path;
import javax.ws.rs.Produces;
import javax.ws.rs.core.MediaType;
@Path("/heroes")
public class AvroConsumerResource {
@Channel("heroes")
Multi<Hero> heroes; // The hero class is generated from the schema.
@GET
@Produces(MediaType.SERVER_SENT_EVENTS)
@RestStreamElementType(MediaType.APPLICATION_JSON)
public Multi<Hero> stream() {
return heroes;
}
}Quarkus 会自动查找序列化器和反序列化器并配置通道,所以同样:**无需配置**。但是,您仍然需要指示 Apicurio 注册模式。通常,这是一个手动操作,但对于开发,您可以使用以下属性:
kafka.apicurio.registry.auto-register=true要运行此应用程序,请打开两个终端。在第一个终端中,导航到 avro-serde/avro-serde-publisher,然后运行 mvn quarkus:dev。在第二个终端中,导航到 avro-serde/avro-serde-consumer,然后运行 mvn quarkus:dev。然后,在浏览器中打开 https://:8080。与 JSON 变体一样,每 5 秒钟,就会显示一张新的英雄图片。这次 Kafka 记录是使用 Avro 序列化的。
编写自定义序列化器和反序列化器
当然,您仍然可以编写自己的自定义序列化器和反序列化器。如上所述,您需要实现 Serializer 和 Deserializer 接口。
例如,HeroSerializer 类 包含了一种简单(但效率不高)的序列化英雄的方法:
package me.escoffier.quarkus.json.publisher;
import org.apache.kafka.common.serialization.Serializer;
import java.nio.charset.StandardCharsets;
public class HeroSerializer implements Serializer<Hero> {
@Override
public byte[] serialize(String topic, Hero data) {
return (data.name() + "," + data.picture())
.getBytes(StandardCharsets.UTF_8);
}
}HeroDeserializer 类 包含相应的反序列化部分。
和以前一样,Quarkus 会发现这些实现并为您配置通道。所以您无需配置任何内容。
自定义序列化器和反序列化器可以接收配置属性。它们会在 configure 方法中接收生产者/消费者的配置。
| 自定义序列化器和反序列化器不能是 CDI bean。Kafka 会直接使用反射来实例化它们。 |
结论
这篇博文探讨了使用 Kafka 序列化和反序列化消息的各种可能性,以及 Quarkus 如何减少您需要使用的样板代码和配置量。
那么,您应该使用什么呢?
-
JSON 被广泛使用,但默认情况下缺乏结构验证,如果格式快速演变,可能会很快成为一个问题。
-
Avro 提供了更好的性能,并处理验证和演进。但它需要一个模式注册表。如果您的系统与不断演变的结构交换大量消息,那么 Avro 应该更受青睐。此外,Avro 生成的有效负载更小。
-
如果您有 JSON 和 Avro 方法无法满足的严格要求,您可以开发自定义序列化器和反序列化器。
请注意,JSON 可以与 JSON-Schema 结合使用(模式存储在模式注册表中)。如果您更喜欢二进制格式,Protobuf 也是一个可能的替代方案。
