使用 Quarkus 构建本地 RAG 应用程序

这篇博文演示了如何使用 Quarkus、LangChain4j、Infinispan 和 Granite LLM 构建一个注入 AI 的聊天机器人应用程序。在这篇文章中,我们将创建一个**完全**本地的解决方案,无需任何云服务,包括 LLM。
我们的聊天机器人利用 Granite LLM,这是一种根据用户提示生成上下文相关文本的语言模型。要在本地运行 Granite,我们将使用 InstructLab,尽管 Podman AI Lab 也是一个可行的选择。
我们应用程序的核心基于 RAG(检索增强生成)模式。这种方法通过在生成响应之前从向量数据库(在本例中为 Infinispan)检索相关信息来增强聊天机器人的响应。
架构
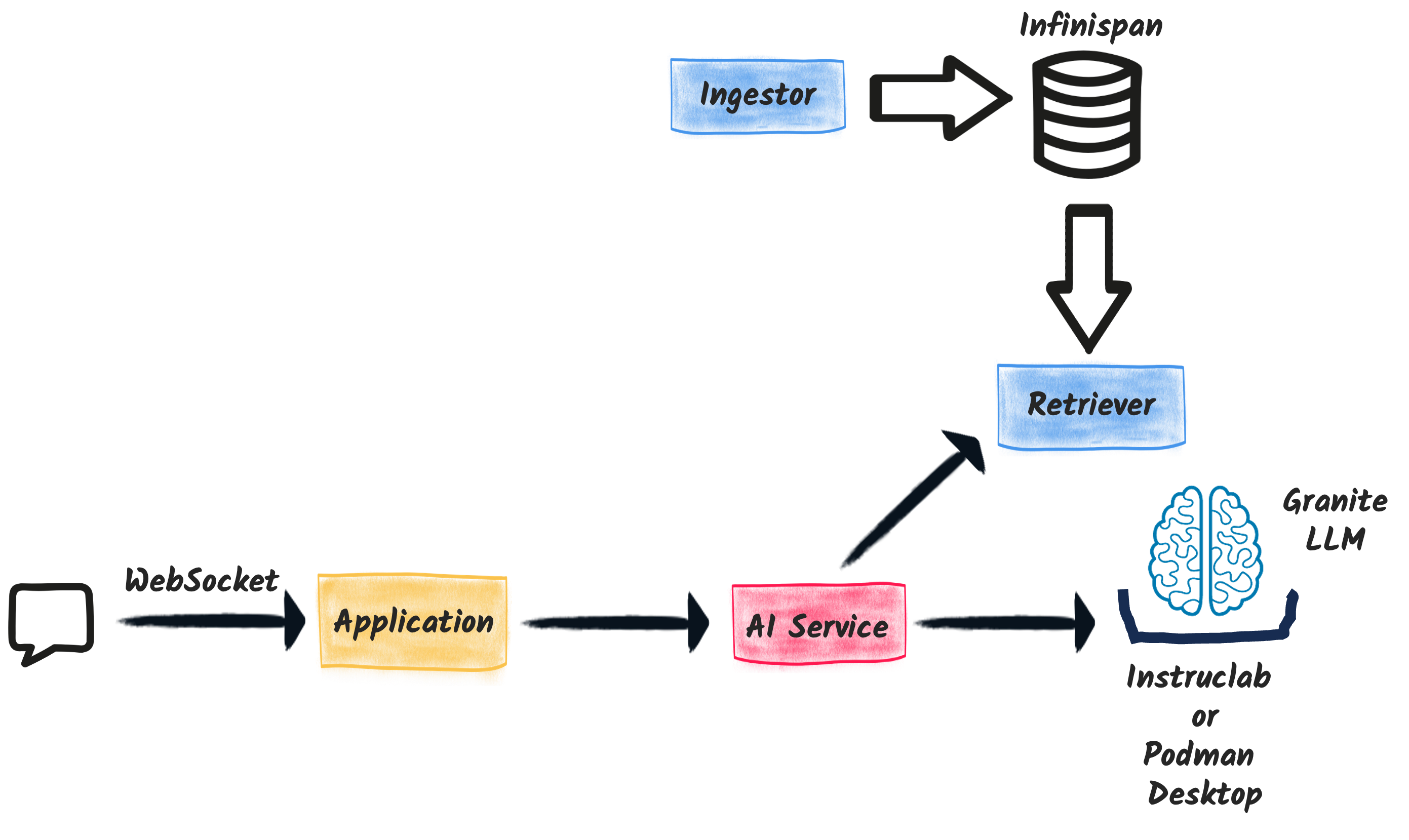
我们的聊天机器人应用程序由四个主要组件组成
-
WebSocket 端点:此组件充当聊天机器人后端与前端界面之间的通信桥梁。此组件使用新的 Quarkus WebSocket-Next 扩展来高效处理 WebSocket 连接。它依赖于 AI 服务与 LLM 进行交互。
-
Ingestor:Ingestor 负责用相关数据填充数据库。它处理一组本地文档,将它们分割成文本片段,计算它们的向量表示,并将它们存储到 Infinispan 中。
-
Retriever:Retriever 允许在 Infinispan 中查找相关的文本片段。当用户输入查询时,Retriever 会搜索向量数据库以查找最相关的信息片段。
-
AI 服务:这是聊天机器人的核心组件,结合了 Retriever 和 Granite LLM 的功能。AI 服务接收 Retriever 获取的相关信息,并使用 Granite LLM 生成适当的响应。
下图说明了高层架构
RAG 模式的简单解释
RAG(检索增强生成)模式是最受欢迎的 AI 模式之一,它结合了检索机制和生成机制,以提供更准确、更相关的响应。
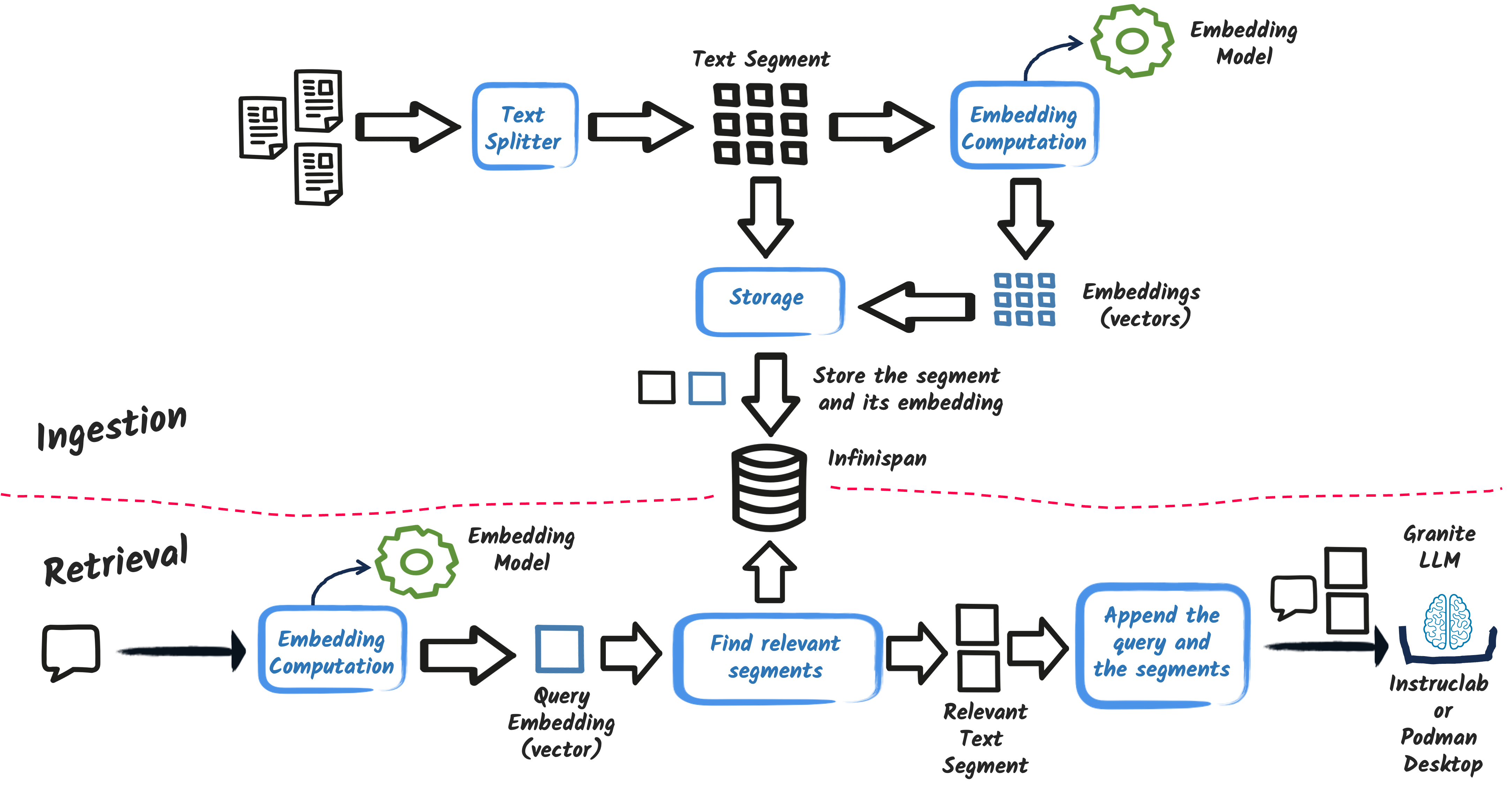
RAG 模式主要分两个步骤进行
-
Ingestion:应用程序摄取一组文档,处理它们,并将它们存储在向量数据库中。
-
Retrieval:当用户输入查询时,应用程序从向量数据库中检索最相关的信息。
下图概述了传统 RAG 模式
RAG 模式有更高级的版本,但在此应用程序中,我们将坚持基本原理。
Ingestion
让我们先看看 ingestion 步骤。ingestion 过程包括读取一组文档,将它们分割成文本片段,计算它们的向量表示,并将它们存储在 Infinispan 中。
有效的 RAG 实现的秘诀在于文本片段的计算方式。在我们的应用程序中,我们将遵循一种直接的方法,但有更高级的技术可用,并且通常是必需的。根据文档,您可以使用多种技术将文本分割成片段,例如段落分割、句子分割或更高级的技术,如recursive 分割器。此外,如果文档具有特定结构,您可以使用该结构将文本分割成片段(如节、章等)。
嵌入模型负责将文本转换为向量表示。为简单起见,我们使用了一个进程内嵌入模型(BGE-small)。也有其他选项,例如 Universal Angle Embedding,但为了简单起见,我们将坚持使用 BGE-small。
实现聊天机器人
理论讲够了——让我们深入了解实现。您可以在 GitHub 上找到最终版本。
使用的扩展和依赖项
为了实现我们的聊天机器人,我们依赖以下 Quarkus 扩展
-
quarkus-langchain4j-openai:使用 OpenAI API 集成 LLM 提供程序,适用于 InstructLab 和 Podman AI Lab。 -
quarkus-websockets-next:提供 WebSocket 通信支持。 -
quarkus-langchain4j-infinispan:将 Infinispan 与 LangChain4j 集成,允许我们存储和检索文本片段的向量表示。 -
quarkus-web-bundler:将前端资源与 Quarkus 应用程序打包。
我们还需要一个特定的依赖项来使用 BGE-small 嵌入模型
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-embeddings-bge-small-en-q</artifactId>
</dependency>配置
我们需要一些配置来确保我们的应用程序使用 Granite 并正确设置 Infinispan 数据库
# Configure the Infinispan vectors:
quarkus.langchain4j.infinispan.dimension=384 (1)
# Configure the OpenAI service to use instruct lab:
quarkus.langchain4j.openai.base-url=https://:8000/v1 (2)
quarkus.langchain4j.openai.timeout=60s
quarkus.langchain4j.embedding-model.provider=dev.langchain4j.model.embedding.BgeSmallEnQuantizedEmbeddingModel (3)| 1 | 配置存储在 Infinispan 中的向量的维度,这取决于嵌入模型(在本例中为 BGE-small)。 |
| 2 | 配置 OpenAI 服务以使用 InstructLab。如果您愿意,可以将基础 URL 替换为 Podman AI Lab 的 URL。实际上,InstructLab 和 Podman AI Lab 都暴露了一个与 OpenAI 兼容的 API。 |
| 3 | 将默认嵌入模型设置为 BGE-small。 |
Ingestor
配置完成后,让我们来实现 ingestion 部分(Ingestion.java)。Ingestor 从 `documents` 目录读取文档,将它们分割成文本片段,计算它们的向量表示,并将它们存储在 Infinispan 中。
@Singleton
@Startup (1)
public class Ingestion {
public Ingestion(EmbeddingStore<TextSegment> store, EmbeddingModel embedding) { (2)
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingStore(store)
.embeddingModel(embedding)
.documentSplitter(recursive(1024, 0)) (3)
.build();
Path dir = Path.of("documents");
List<Document> documents = FileSystemDocumentLoader.loadDocuments(dir);
Log.info("Ingesting " + documents.size() + " documents");
ingestor.ingest(documents);
Log.info("Document ingested");
}
}| 1 | @Startup 注解确保 ingestion 过程在应用程序启动时开始。 |
| 2 | Ingestion 类使用(自动注入的)EmbeddingStore<TextSegment>(Infinispan)和 EmbeddingModel(BGE-small)。 |
| 3 | 我们使用简单的文档分割器(recursive(1024, 0))将文档分割成文本片段。可以使用更高级的技术来提高 RAG 模型的准确性。 |
Retriever
接下来,让我们来实现 retriever(Retriever.java)。Retriever 根据用户查询在 Infinispan 中查找最相关的文本片段。
@Singleton
public class Retriever implements Supplier<RetrievalAugmentor> {
private final DefaultRetrievalAugmentor augmentor;
Retriever(EmbeddingStore<TextSegment> store, EmbeddingModel model) {
EmbeddingStoreContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingModel(model)
.embeddingStore(store)
.maxResults(2) // Large segments
.build();
augmentor = DefaultRetrievalAugmentor
.builder()
.contentRetriever(contentRetriever)
.build();
}
@Override
public RetrievalAugmentor get() {
return augmentor;
}
}为了实现 retriever,公开一个实现 Supplier<RetrievalAugmentor> 接口的 bean。Retriever 类使用 EmbeddingStore<TextSegment>(Infinispan)和 EmbeddingModel(BGE-small)来构建 retriever。
EmbeddingStoreContentRetriever builder 中的 maxResults 方法指定要检索的文本片段数量。由于我们的片段很大,因此我们只检索两个片段。
AI 服务
AI 服务(ChatBot.java)是我们聊天机器人的核心组件,它结合了 retriever 和 Granite LLM 的功能来生成适当的响应。
使用 Quarkus,实现 AI 服务非常简单
@RegisterAiService(retrievalAugmentor = Retriever.class) (1)
@SystemMessage("You are Mona, a chatbot answering question about a museum. Be polite, concise and helpful.") (2)
@SessionScoped (3)
public interface ChatBot {
String chat(String question); (4)
}| 1 | @RegisterAiService 注解指定要使用的 retrieval augmentor,在本例中是我们之前定义的 Retriever bean。 |
| 2 | @SystemMessage 注解为 AI 模型提供了主要的指令。 |
| 3 | @SessionScoped 注解确保 AI 服务是有状态的,在用户交互之间保持上下文,以获得更具吸引力的对话。 |
| 4 | ChatBot 接口定义了一个名为 chat 的单个方法,该方法接受用户问题作为输入并返回聊天机器人的响应。 |
WebSocket 端点
最后一块是 WebSocket 端点(ChatWebSocket.java),它充当聊天机器人后端与前端界面之间的通信桥梁。
@WebSocket(path = "/chat") (1)
public class ChatWebSocket {
@Inject ChatBot bot; // Inject the AI service
@OnOpen (2)
String welcome() {
return "Welcome, my name is Mona, how can I help you today?";
}
@OnTextMessage (3)
String onMessage(String message) {
return bot.chat(message);
}
}| 1 | @WebSocket 注解指定 WebSocket 路径。 |
| 2 | @OnOpen 方法在用户连接到WebSocket 时发送欢迎消息。 |
| 3 | @OnTextMessage 方法使用注入的 AI 服务处理用户的消息并返回聊天机器人的响应。 |
就是这样!我们的聊天机器人现在已准备好与用户聊天,根据 RAG 模式提供上下文相关的响应。
运行应用程序
让我们运行应用程序,看看我们的聊天机器人在起作用。首先,克隆 repository 并运行以下命令
./mvnw quarkus:dev此命令以开发模式启动 Quarkus 应用程序。请确保您正在运行 InstructLab 或 Podman AI Lab 以使用 Granite LLM。您还需要 Docker 或 Podman 来自动启动 Infinispan。
|
Podman AI Lab 还是 InstructLab?
您可以使用 Podman AI Lab 或 InstructLab 在本地运行 Granite LLM。根据操作系统,Podman 可能没有 GPU 支持。因此,响应时间可能很高。在这种情况下,InstructLab 是更好的选择,以获得更快的响应时间。通常,在 Mac 上,您会使用 InstructLab,而在 Linux 上,Podman AI Lab 会显示出出色的性能。 |
应用程序启动并运行后,打开您的浏览器并导航到 https://:8080。您应该会看到聊天机器人界面,您可以在其中开始与 Mona 聊天。

总结
就是这样!只需几行代码,我们就使用 RAG 模式实现了一个聊天机器人,它结合了 Granite LLM、Infinispan 和 Quarkus 的功能。此应用程序完全在本地运行,无需任何云服务,并解决了隐私问题。
这只是使用 Quarkus LangChain4j 扩展可以实现的一个示例。您可以轻松地通过添加更高级的功能来扩展此应用程序,例如复杂的文档分割器、嵌入模型或检索机制。Quarkus LangChain4J 还支持高级 RAG、许多其他 LLM 和嵌入模型以及向量存储。在 Quarkus LangChain4J 上查找更多信息。
