VCStream:为 DECATHLON 价值链构建的基于 Quarkus 的新型消息传递平台。

迪卡侬是一家法国零售商,致力于运动产品,在全球拥有超过 1800 家门店。在迪卡侬,我们坚信运动是幸福的源泉。
VCStream 是一个在迪卡侬价值链中流式传输数据的新平台。它允许数据流入和流出价值链,我们称之为入站(从外部系统到价值链)和出站(从价值链到外部系统)流程。
VCStream 的口号:“一个平台连接一切”。
VCStream 提供连接器,可以轻松地将传入的 Kafka 主题中的数据流式传输到现有的价值链 ERP 模块,以及从这些 ERP 模块流式传输到传出的 Kafka 主题和对象存储。
VCStream 利用 Quarkus 框架和 Kubernetes,提供一个弹性且高性能的平台,满足迪卡侬价值链的安全性和可靠性要求。
Age Of Access Accelerator (AoAA) 是 VCStream 平台背后的团队。我们是一个由三名开发人员、一名 DevOps、一名产品负责人和一名企业架构师组成的小团队;当然,别忘了我们的团队负责人(他在有时间的时候也会参与开发)。
挑战
价值链 IT 部门面临着一个主要问题,即迪卡侬其他部门的数据暴露和消费。业务稳步增长,导致资源消耗、容量需求和实时事件数据显著增加。我们意识到我们的系统无法跟上。
目前对专用服务器的使用导致资源浪费增加。该部门对遗留工作流程和 ERP 生态系统的依赖导致了严重的生产力瓶颈。如今,将数据视为流是一种流行的方法。在许多情况下,它允许以比经典的“数据即状态”方式更有效的方式构建数据工程架构。但是,为了支持流式数据范例,我们需要使用其他技术。用于处理流式数据最流行的工具之一是 Apache Kafka,迪卡侬决定对其进行大量投资。
对于我们来说,VCStream 生成的数据质量非常重要,特别是考虑到我们在大规模运行 VCStream。一个团队生成的数据可以并且将被迪卡侬内的许多不同应用程序使用。数据质量的缺乏会对下游消费者产生巨大影响。
在VCStream 平台之前,价值链面临以下挑战:
-
数据标准化:数据以不统一的方式暴露,并且没有标准。
-
上市时间:暴露新数据需要时间,因为我们依赖于通过遗留工具进行手动调度。
-
实时消费数据:与当前批处理模式使用相反。
-
可扩展性和弹性:处理大量数据,并且遗留系统很脆弱。
我们知道我们的价值链需要一个平台来使我们的数据交换现代化:一种可以实现数据访问、高效数据集成、容器采用和开发人员大规模快速开发的产品。
“几乎每个周末都是我们在价值链中经历过的最大的周末!我们的系统变得不稳定。我们无法以旧的方式处理应用程序部署。” - 这是我们许多人的观察。
为什么选择 Quarkus?
为了实施 VCStream,我们的团队评估了 Spring Boot、Micronaut 和 Quarkus。由于没有人真正有使用 Micronaut 的经验,我们很快就将其排除在外。
我们基于以下标准选择了 Quarkus:
-
团队有兴趣学习一种新的框架
-
Microprofile reactive messaging 看起来非常有趣,并且是一个简洁的 API,可以实现我们主要需要的仅消息微服务。
-
性能是 Quarkus 的核心,更重要的是,低资源消耗(CPU 和内存),这很重要,因为我们计划部署到云,并且团队对生态环境有一定的敏感性。
-
我们正确地在 GKE 上实施弹性应用程序所需的所有容器、Kubernetes 和云就绪功能都在那里。
最后,我们团队中有一位 Quarkus 贡献者,这使我们能够深入了解该框架,并在社区内拥有独特的联系。
说到社区,Quarkus 社区非常活跃和热情。这是我们最重要的标准之一。
当然,我们与所有团队成员进行了一些概念验证,比较了实现方式,并共同决定了在我们的上下文中最好的选择是什么。
在这些概念验证期间,我们特别喜欢 Quarkus 的学习曲线非常快速且比我们最初想象的要容易。新手在一周之内就熟悉了 Quarkus,并且所有面向开发人员的功能(实时重新加载 FTW!)真正使他们能够在日常工作中提高效率。
我们的承诺
在迪卡侬内部,使用 Quarkus 的项目并不多,不像 Spring Boot,它已经被证明,并且有几位开发人员熟悉它。
Quarkus 在我们当前的 TechRadar(试验)中的地位并没有真正帮助我们权衡对它的使用。我们与就 Quarkus 的使用进行讨论的少数开发人员对该框架提出的性能概念表示了一些保留。
对我们的公司来说,在新框架上做出客观的选择(为了公司和对框架充满热情的开发人员)非常困难!我们不能仅仅依靠我们团队中的 Quarkus 专家的建议来做出选择。这就是我们开始进行 POC 的原因,目的是如果我们遇到不可能的情况,我们会毫不犹豫地回到 Spring Boot!知道这个 POC 仍然会在每个人都知道的困难经济环境下花费我们。
幸运的是,项目进展顺利,现在我们已经成功地将其部署到生产环境中,并通过 VCStream 将许多 ERP 模块与外部 IT 系统连接起来。
VCStream 架构
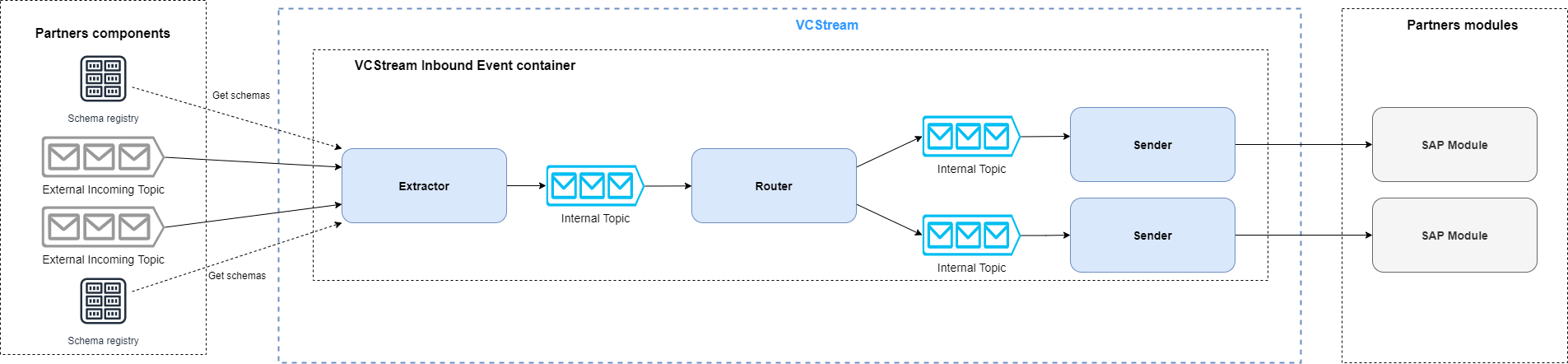
这是 VCStream 入站流程架构的简化视图:提取器连接到多个 Kafka 代理,并实时使用来自多个主题的消息。然后将这些消息转换为 JSON,路由并发送到多个 ERP 模块(一条消息可以发送到一个或多个 ERP 模块)。每个 ERP 模块都有一个发送者实例。
目前,我们从 6 个主题中提取并发送到 3 个 ERP 模块,但我们预计到 2022 年底将从多达 25 个不同的主题中消费。
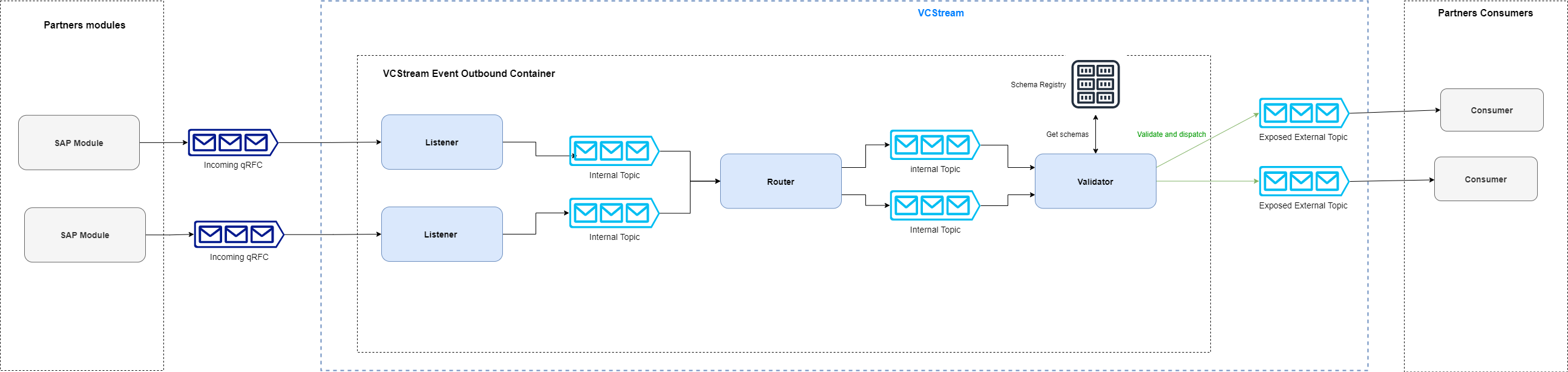
这是 VCStream 出站流程架构的简化视图:监听器监视来自 ERP 模块的 JSON 消息。这些消息被路由,然后发送到验证器进行验证,转换为 AVRO 格式,并在专用主题中公开。每个 ERP 模块都有一个监听器实例。
目前,我们从 4 个 ERP 模块接收消息并公开 6 个主题,但我们预计到 2022 年底将公开多达 25 个主题。
拥抱 Quarkus
以下是 VCStream 平台开发团队成员对使用 Quarkus 的评价。
Fawaz Paraïso - 团队负责人
作为开发人员和团队负责人,我必须对自己选择使用 Quarkus 来实施我们的平台做出自己的判断。我们的技术选择必须与迪卡侬的开发战略保持一致。
与已经建立起来的 Spring Boot 相比,Quarkus 是 Java 生态系统中的一个新框架。除了这些考虑(新的)之外,我们的团队应该对 Quarkus 可以提供什么给出具体的意见。对我来说,Quarkus 的入门很容易,这可能与我作为高级开发人员的经验有关。在使用 Quarkus 开发一周后,我能够恢复到与使用 Spring Boot 开发时相同的生产力水平。对于我们平台的实施,SmallRye Reactive Messaging 对我来说比较新,并且满足了我们平台的架构约束。我们的 POC 取得了成功,结果(简单性、性能、弹性)超出了我们的预期。尽管取得了积极的结果,但我并不想就此止步。我想从一位初级开发人员那里获得另一种观点,他和我一样,从未接触过 Quarkus。
一位不了解我们的项目,也不了解 Quarkus 的初级成员加入我们的团队,为我提供了关于如何开始使用 Quarkus 的其他答案。他在第一周就对我们的存储库做出了贡献。这位合作者使用 Quarkus 的经验绝对让我确信初级开发人员可以多么容易地开始使用 Quarkus。
Thomas Dangleterre - 初级开发人员
我在项目开始 4 个月后加入了团队。我被招聘担任初级 Java 软件开发人员。这是我第一次处理微服务架构,我只有少量的云经验。我非常喜欢 Quarkus 上的热重载功能,这是我在之前在遗留应用程序上的任务中不习惯的功能。我喜欢通过 SmallRye Reactive Messaging 提供的抽象,可以很容易地与 Kafka 进行交互。
我很熟悉 Spring Boot,所以很容易适应 Quarkus,它们有很多相似之处。我还发现 Quarkus 的文档非常清晰,我真的很期待继续了解更多关于 Quarkus 的知识。
Victor Gallet - 高级开发人员和 Kafka 专家
当我加入团队时,已经用 Quarkus 部署了大约 10 个微服务。我还没有机会使用 Quarkus,我只是在一次聚会上看过演示,并且对该框架很感兴趣。自从我职业生涯开始以来,我一直在使用 Spring 框架,我想发现与 Quarkus 相比的巨大差异。尽管有实用程序类和不同的 CDI 注释,但我还是能够很快地开始使用 Quarkus。Quarkus 指南提供了巨大的帮助,因为它们专注于一个主题并直奔主题。例如,由于我们的微服务专门与 Apache Kafka 通信,Quarkus 与 Apache Kafka 的集成指南让我立即理解了这些概念和我们的不同组件。
与 Quarkus(ArC)提供的依赖注入和实现相比,我没有遇到任何问题。这些概念是标准的,我只需要发现一些新的注释,例如 @ApplicationScoped 和 @Singleton,仅举几个最常用的。
总而言之,以下是我真正喜欢使用 Quarkus 的几点:
统一配置和配置文件管理
使用这个简单的小配置
greeting.message=hello %dev.greeting.message=hey %test.greeting.message=hi
允许在本地启动应用程序时使用值“hey”和测试时使用值“hi”覆盖 greeting.message 属性。这非常方便,并且大大简化了测试的配置管理。
支持
我已经在上面提到了这一点,但文档非常清晰,并且该指南允许您以简单快捷的方式发现功能、Quarkus 的使用方法。我还对 Quarkus 社区在其 Zulip 聊天中的响应能力和支持感到惊喜。非常感谢 Clément Escoffier,他帮助我们改进了我们的应用程序,并亲自帮助我为 SmallRye Reactive Messaging 项目做出了我的第一个开源贡献。
作为 Spring 开发人员,我遇到的一个需要注意的问题是,Quarkus 在构建期间采取了许多操作来减少启动时间和内存占用。想要在我的应用程序中具有动态行为,我使用了注释 @IfBuildProperty 来选择适当的 Bean,但是,顾名思义,Bean 将在构建期间被选中,并且替代方法将在运行时不可用。
最后,为了结束我的反馈,我很遗憾没有面对本机映像的构建。但是我们的项目选择了在 Kubernetes 集群中部署容器,这正是 Quarkus 的设计目的。
Loïc Mathieu - 高级开发人员
我是一名 Quarkus 提交者,并且在加入团队之前非常了解 Quarkus。因此,我将给出一个非常狭隘的评价,关于我们使用的一个非常具体的功能,我非常喜欢。
反应式编程是 Quarkus 的核心,而反应式消息传递顾名思义,是一个反应式框架。
当您需要消费或生成消息时,您可以简单地使用有效负载作为方法参数或返回类型。但是当您需要在消息流上实现异步处理或复杂逻辑时,您需要使用 Mutiny 而不是直接使用您的有效负载类型。Mutiny 是一组反应式类型和运算符。它允许表达项目流上的一组转换,并遵循反应式流标准。
我们的需求之一是将传入的消息分组为批次,因为向 ERP 模块发送消息是有成本的,他们担心每天收到数百万条消息。因此,我们需要按类型分组,然后按 50 个一批分组,并至少每分钟发出一个批次,以避免过多地延迟消息传递。
为了实现这一点,我们原型化了 Kafka Stream 的用法,但这给我们的当前技术堆栈增加了一些复杂性,因为我们还没有使用它,并且它有一些分组限制(该框架未提供开箱即用的按大小分组)。
因此,我们决定简单地使用我们工具箱中已有的工具 Mutiny,我们实现的代码对于这样一个复杂的任务来说非常易读,而且我们从那时起一直对它非常满意。
@Incoming("in")
@Outgoing("group-out")
public Multi<Message<List<ErpMessage>>> group(Multi<KafkaRecord<String, RawMessage>> events) { (1)
return events
.group().by(record -> record.getPayload().type) (2)
.flatMap(group -> group.group().intoLists().of(size, duration)) (3)
.filter(group -> !group.isEmpty()) (4)
.flatMap(groupedMultis -> {
List<ErpMessage> erpMsg = groupedMultis.stream() (5)
.map(record -> toErpMessage(record))
.collect(Collectors.toList());
return Multi.createFrom().item(KafkaRecord.of((String) null, erpMsg)); (6)
});
}
-
该方法采用 Kafka 消息流。
-
首先,我们按有效负载类型分组。
-
然后,我们按大小消息批量分组,最大持续时间为持续时间。
-
然后,我们删除空批次。
-
然后,我们将每个消息批次映射到一种新格式。
-
然后,我们返回一条包含批次的 Kafka 消息。
非常简单,对吧?
展望未来
性能是 VCStream 设计和实施的核心,我们执行定期的负载测试,并运行定期的危机场景(我们通过操纵主题偏移来模拟跟上代理中等待的大量消息)。
每次遇到性能瓶颈或回归时,我们都会与 Quarkus 社区讨论它们,并获得非常及时的反馈。所有问题都得到了快速解决,我们平台的性能和弹性不断提高。
我们部署在云上,这意味着可以直接衡量的成本。即使今天我们的平台在生产中尚未被大量使用(目前只有一半已部署的主题被真正使用),但我们预计到 2022 年底需要扩展到每分钟最多 150 万条消息,并且连接到当前 ERP 模块数量的两倍以上。因此,达到性能所需的性能水平和资源非常重要。
好消息是:我们并不害怕这一点,因为该平台在其当前状态下已经可以维持每分钟的大量消息。我们在危机场景中对我们的平台进行基准测试,以 每分钟每实例高达 50 万条消息的速度进行基准测试,即使 Kafka 客户端优先考虑一致性
感谢 Quarkus,组件的单个实例使用的 CPU 至少为 0.5 个,内存至少为 512MB (堆大小约为 120MB),我们可以减少,因为所有 CPU 和内存未使用,但这已经很少了,因此我们更愿意在这方面保持保守。哦,是的,这是在 Java 16 上并使用 JVM。
换句话说,借助 Quarkus 和 MicroProfile 反应式消息传递,我们在真实的流式传输应用程序上实现了 每 CPU 每 GB 内存每分钟 100 万条消息的吞吐量 。这是一个令人印象深刻的吞吐量密度,我们对此非常满意。
最后几句话,我们要特别感谢 Quarkus 社区帮助我们,一次又一次地回答我们的问题,在每个版本中改进 Quarkus,以及他们用 Quarkus 和出色的 MicroProfile Reactive Messaging 框架所做的非常好的工作!谢谢大家,你们太棒了!
本文已由 Age of Access Accelerator 团队的所有成员撰写和校对。
