Quarkus 的 Agentic AI - 第 3 部分

本博客系列的第一部分简要介绍了Agentic AI并讨论了工作流模式。随后,第二部分探讨了合适的Agentic模式,展示了如何使用Quarkus及其LangChain4j扩展来实现它们。
本文旨在阐明这两种方法的区别,讨论它们的优缺点,并通过实际示例演示如何将使用工作流模式的AI服务迁移到纯粹的Agentic实现。
本质上,两者最相关的区别在于,工作流模式是通过手动编写的代码路径以编程方式编排的,而Agent则自主决定自己的流程和工具使用,从而控制任务的执行方式。这使得它们在各种场景下更具灵活性和适应性,但也使得它们更不可预测,在某些情况下,更容易出现幻觉。
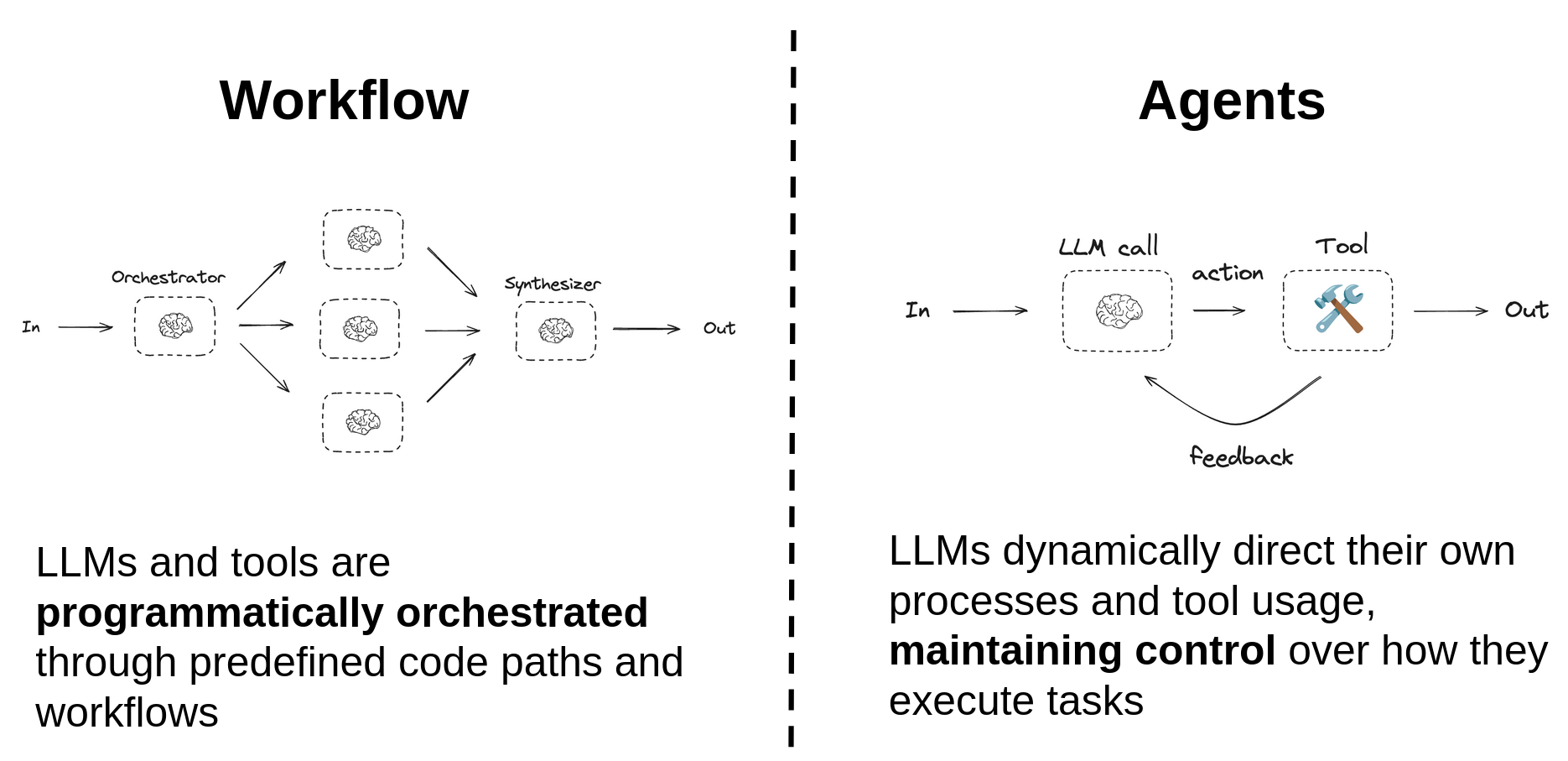
从工作流到Agent
本系列第一篇文章中介绍的工作流模式之一是路由。在那里,我们使用第一个LLM服务来分类用户请求,然后使用该类别以编程方式将请求路由到三个其他LLM之一,它们分别充当医疗、法律或技术专家。
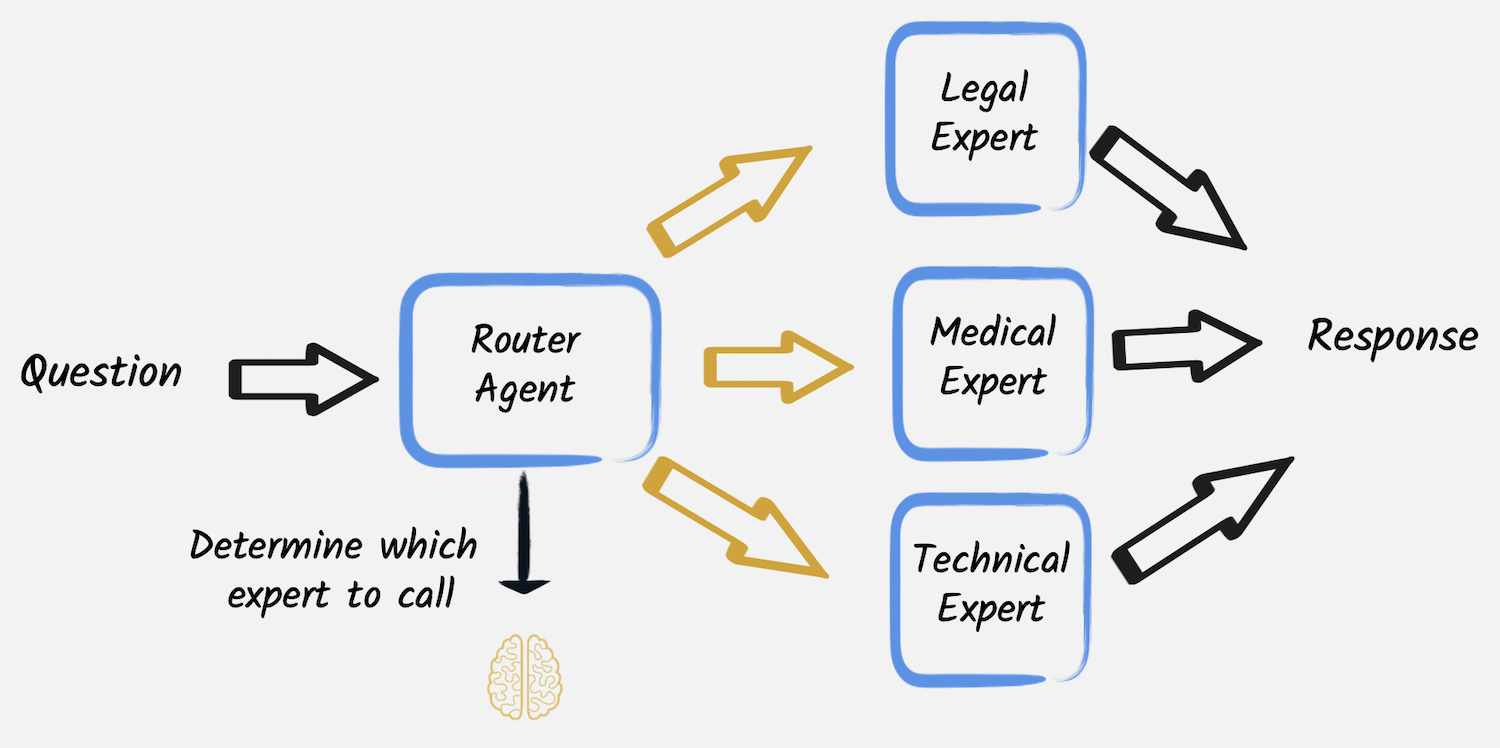
在该示例中,每个专家都被实现为一个独立的服务,并且路由到其中一个专家是通过应用程序代码以编程方式执行的。跟踪类似请求的执行
curl https://:8080/expert/request/I%20broke%20my%20leg%20what%20should%20I%20do生成的跟踪显示了满足用户请求所执行的步骤序列:首先是相对较快(不到2秒)的由Router Agent进行的分类阶段,然后是更耗时的对所选专家服务的调用,该服务花了将近25秒来生成答案。
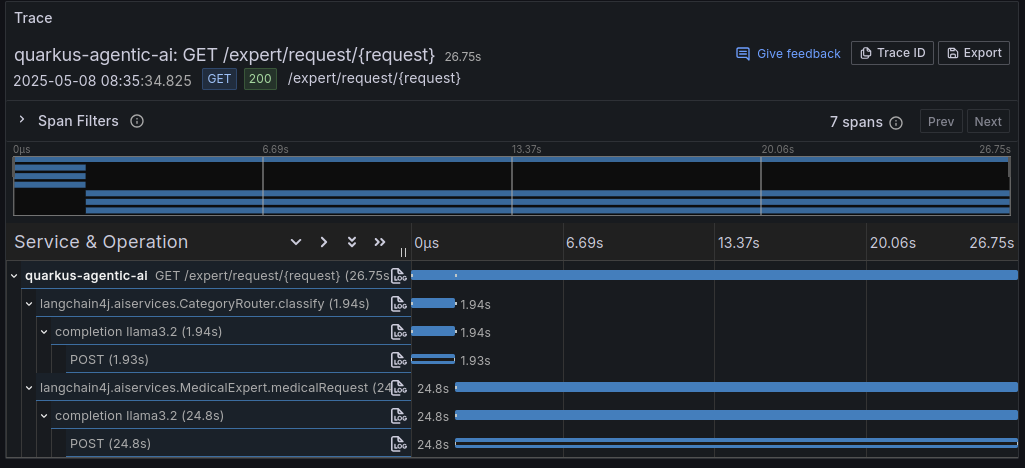
在此示例中,我们使用相同的模型进行分类和生成响应。但是,可以使用专门的模型进行分类和每个专家的处理。现在,让我们看看如何将这种工作流方法转化为更Agentic的方法。
Quarkus集成使得将这些AI“专家”服务转换为其他AI服务可以调用的工具变得非常简单。您只需使用@Tool注解AI服务方法,并使用@Toolbox配置调用者AI服务。这种方法保留了将单个专家直接作为独立LLM服务调用的可能性,以及为每个专家使用专用模型的可能性。请注意,此@Tool注解与任何MCP服务器的存在无关,其目的是将AI服务也公开为其他AI服务的工具。计划在下一篇博客文章中讨论MCP。
public interface MedicalExpert {
@UserMessage("""
You are a medical expert.
Analyze the following user request under a medical point of view and provide the best possible answer.
The user request is {request}.
""")
@Tool("A medical expert") // <-- Allows to use this LLM also as a tool for other LLMs
String medicalRequest(String request);
}这样,就可以提供该专家查询服务的第二个备选实现,这一次使用纯粹的Agentic方法。Router Agent被替换为单个LLM,将三个专家作为工具,它可以自主决定必须将问题委托给哪个专家。
@RegisterAiService(modelName = "tool-use")
@ApplicationScoped
public interface ExpertsSelectorAgent {
@UserMessage("""
Analyze the following user request and categorize it as 'legal', 'medical' or 'technical',
then forward the request as it is to the corresponding expert provided as a tool.
Finally return the answer that you received from the expert without any modification.
The user request is: '{request}'.
""")
@ToolBox({MedicalExpert.class, LegalExpert.class, TechnicalExpert.class})
String askToExpert(String request);
}@ToolBox注解用于指定Agent可以使用的工具列表,在本例中是三个专家。请注意,与本系列上一篇文章中为其他Agentic示例所做的工作类似,此AI服务已配置为使用能够进行推理和请求工具调用的模型。在我们的示例中,模型在application.properties文件中配置,并使用70亿参数的qwen2.5。此外,temperature设置为0,以使分类更可预测并最大限度地减少幻觉的可能性。
quarkus.langchain4j.ollama.tool-use.chat-model.model-id=qwen2.5:7b
quarkus.langchain4j.ollama.tool-use.chat-model.temperature=0
quarkus.langchain4j.ollama.tool-use.timeout=180s此时,该专家查询服务的Agentic实现也已准备就绪,并且可以使用不同的REST端点公开,从而可以同时使用和比较这两种解决方案。
@GET
@Produces(MediaType.TEXT_PLAIN)
@Path("request-agentic/{request}")
public String requestAgentic(String request) {
Log.infof("User request is: %s", request);
return expertsSelectorAgent.askToExpert(request);
}比较工作流和Agentic方法
这两种方法在功能上是等效的,但在实现方式以及它们提供的控制和灵活性级别上有所不同。特别是,纯粹的Agentic解决方案更简单、更优雅,因为它不需要额外的代码来将请求路由到正确的专家。Agent可以自己完成。如果需要,它还可以为单个查询使用多个专家,这在工作流方法中是不可能的,因为路由是硬编码在应用程序代码中的。
另一方面,工作流方法更具可预测性且更易于调试,因为路由逻辑是显式的,并且可以轻松跟踪。它也可以单独测试和控制。例如,Router Agent本身的行为可以通过输出护栏进行控制和更正。此外,它还允许更复杂的工作流,其中路由决策可以依赖于多个因素,而不仅仅是用户的请求。
最后,正如Agentic执行跟踪所示,其当前实现有一个明显的缺点:满足用户请求的总时间显着增加。
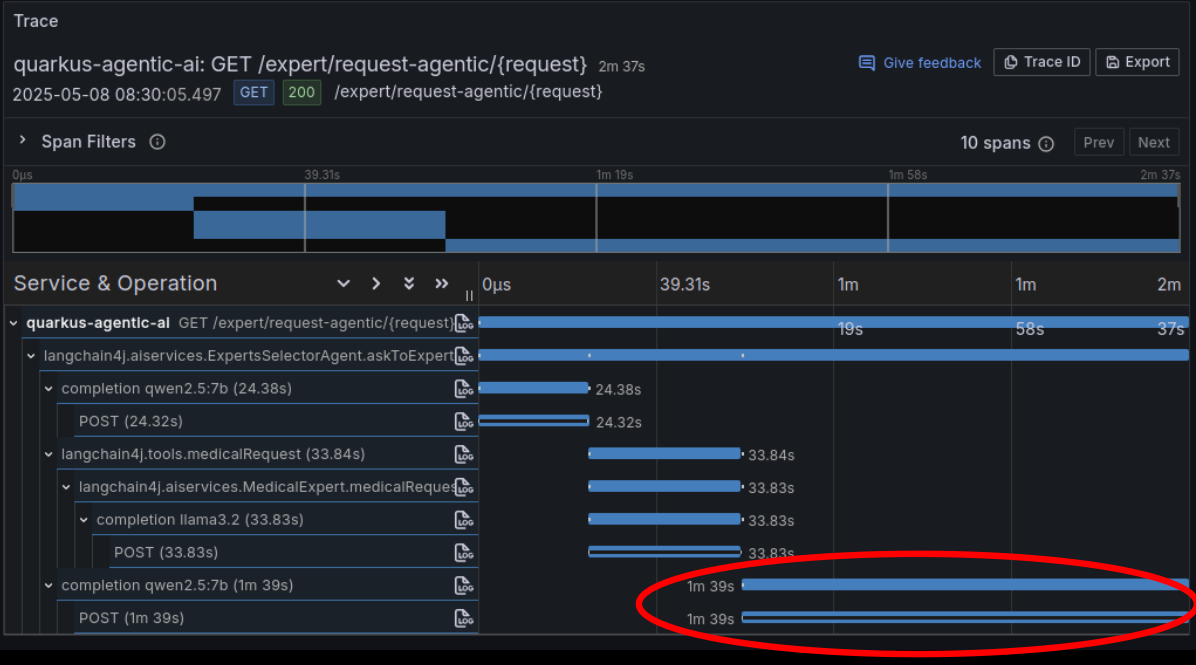
这取决于Agent如何将LLM专家用作工具:即使它被明确要求原封不动地转发专家的响应而不做任何修改,它似乎也忽略了这一指示。在将其返回之前,它无法避免花费大量时间重新处理专家的答案。换句话说,这是Agent完全控制执行这一事实的副作用,并且在这种情况下,无法将控制权转移给不同的LLM。
