使用 Quarkus 的 Agentic AI - 第 1 部分

尽管对于 AI 代理没有普遍认可的定义,但一些新兴模式展示了如何协调和组合多个 AI 服务的各种能力,以创建能够完成更复杂任务的 AI 增强型应用程序。
根据 Antropic 研究人员最近发表的一篇文章,这些 *Agentic 系统架构* 可以分为两个主要类别
-
工作流:LLM 和工具通过预定义的代码路径进行编排,
-
代理:LLM 动态地指导其流程和工具的使用,保持对其执行任务方式的控制。
本系列文章的目标是讨论最常见的工作流和 agentic AI 模式和架构,并借助 此项目 的实际例子,演示如何通过 Quarkus 及其 LangChain4j 集成来实现它们。 当然,实际应用可能会以多种方式使用和组合这些模式,以实现复杂的行为。
第一篇文章侧重于工作流模式。 第二篇文章将介绍代理模式。
该项目中的所有演示都通过 ollama 服务器在本地运行 LLM 推理。 特别是,工作流部分中的演示使用 llama3.2 模型,而纯代理演示使用 qwen2.5,因为最后一个模型经验证在需要多次工具调用时效果更好。
提示链
毫无疑问,提示链是 agentic AI 工作流中最简单但功能强大且有效的技术。 在此技术中,一个提示的输出(来自 LLM 的响应)成为下一个提示的输入,从而实现复杂的多步骤推理或任务执行。 它非常适合将复杂任务分解为更小且界定更好的步骤的情况,从而降低了幻觉或其他 LLM 行为不端的可能性。
理解每次协调的 LLM 调用可能依赖于不同的模型和系统消息至关重要。 因此,可以使用更专业的模型和系统消息来实现每个步骤。
@RegisterAiService(chatMemoryProviderSupplier = RegisterAiService.NoChatMemoryProviderSupplier.class)
public interface CreativeWriter {
@UserMessage("""
You are a creative writer.
Generate a draft of a short novel around the given topic.
Return only the novel and nothing else.
The topic is {topic}.
""")
String generateNovel(String topic);
}它生成用户提供的主题的故事草稿。 相比之下,另外两个服务(实现方式与此类似)随后修改第一个服务的结果。 特别是,第二个服务 重写草稿以使其与确定的风格更加一致,而 第三个服务 执行最终编辑,使其非常适合所需受众。
还值得注意的是,所有这三个 AI 服务都旨在通过一次性调用以完全无状态的方式使用,因此它们被配置为没有任何 聊天记忆。 无论此配置如何,每个 AI 服务都有自己的聊天记忆,仅限于单个服务,这就是为什么有必要将前一个 LLM 在链中产生的输出显式传递给每个服务。
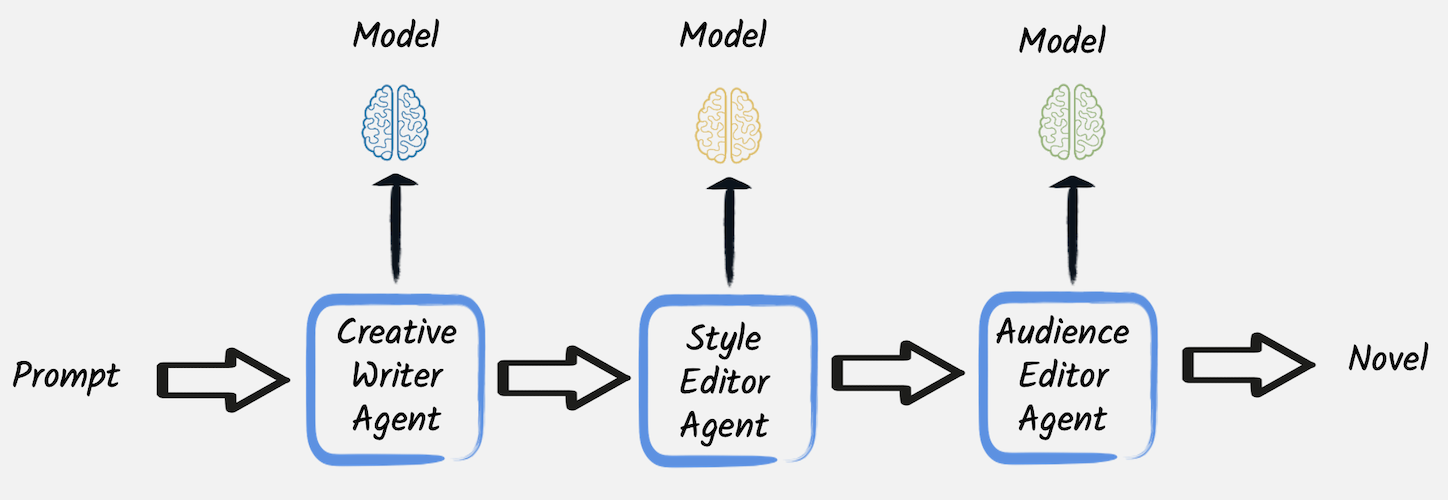
在这种情况下,通过 HTTP 端点 公开此服务非常简单,该端点一个接一个地调用这些 AI 服务,使编辑器重写或完善第一个创意作者生成的内容
// The createWriter, styleEditor, and audienceEditor fields are AI services injected by Quarkus, see full code for details
@GET
@Path("topic/{topic}/style/{style}/audience/{audience}")
public String hello(String topic, String style, String audience) {
// Call the first AI service:
String novel = creativeWriter.generateNovel(topic);
// Pass the outcome from the first call to the second AI service:
novel = styleEditor.editNovel(novel, style);
// Pass the outcome from the second call to the third AI service:
novel = audienceEditor.editNovel(novel, audience);
// Return the final result:
return novel;
}HTTP 端点允许我们定义要创作的小说的主题、风格和受众; 因此,例如,在本地运行项目,可以通过调用此 URL 来获得一个关于狗以儿童为目标受众的故事
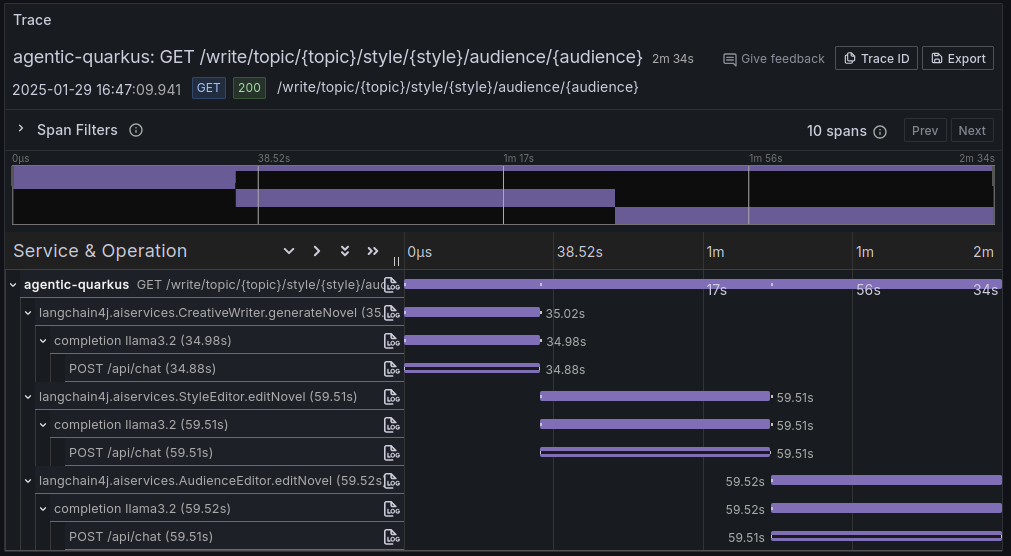
curl https://:8080/write/topic/dogs/style/drama/audience/kids例如,它生成了像 这样 的结果。 由于此项目集成了 Quarkus 开箱即用的可观察性功能,因此还可以查看执行的调用流的跟踪,以满足此请求,这当然突出了此模式的顺序性质。
并行化
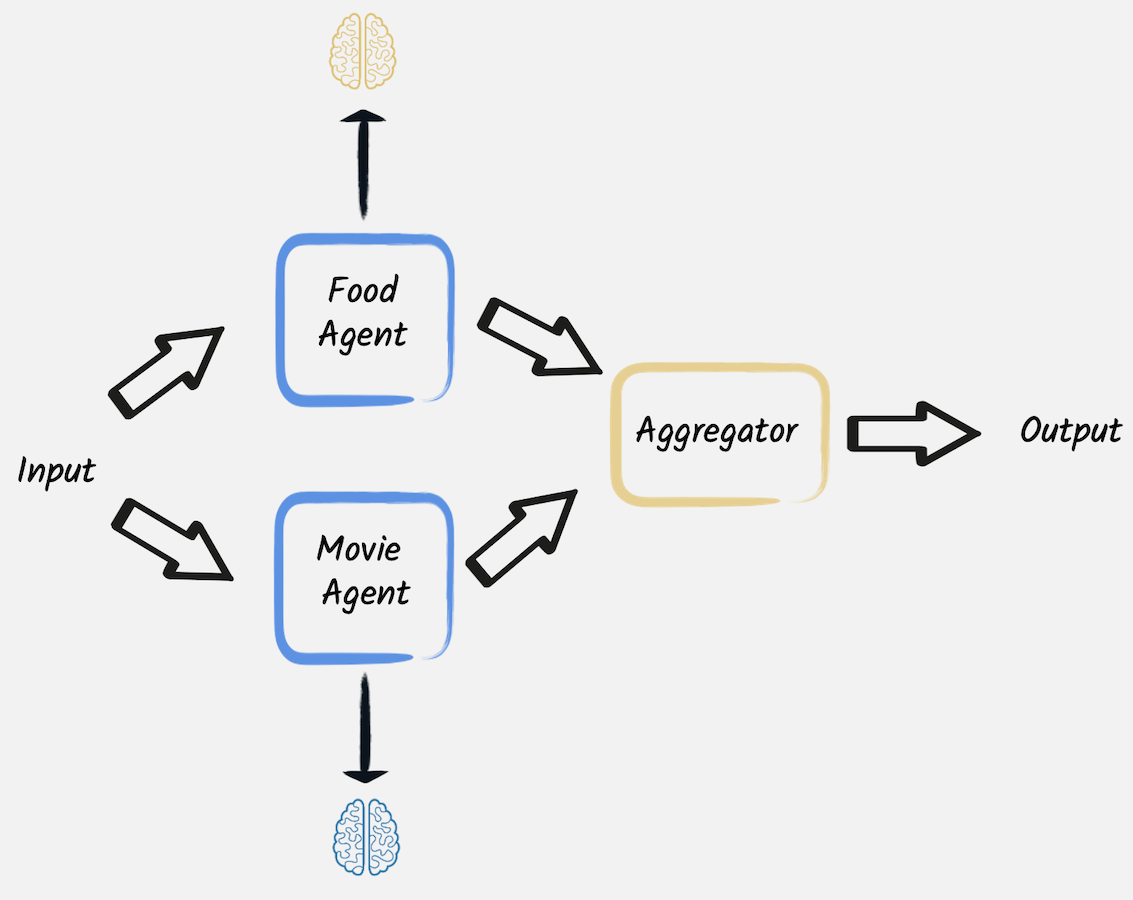
第二种模式也编排对 LLM 的多个调用。 但是,与提示链模式不同,这些调用是独立的,不需要一个调用的输出用作另一个调用的输入。 在这些情况下,可以并行执行这些调用,然后由聚合器组合其结果。
为了演示其工作原理,让我们考虑 第二个示例。 此代码推荐一个具有特定氛围的美好夜晚计划,结合了符合该氛围的电影和美食。 HTTP 端点 通过 并行 调用两个不同的 AI 服务,然后组合其结果来实现此目标,并将两个不同基于 LLM 的专家的三个不同建议放在一起。
import java.time.Duration;@GET
@Path("mood/{mood}")
public List<EveningPlan> plan(String mood) {
var movieSelection = Uni.createFrom().item(() -> movieExpert.findMovie(mood)).runSubscriptionOn(scheduler);
var mealSelection = Uni.createFrom().item(() -> foodExpert.findMeal(mood)).runSubscriptionOn(scheduler);
return Uni.combine().all()
.unis(movieSelection, mealSelection) // This invokes the two LLMs in parallel
.with((movies, meals) -> {
// Both calls have completed, let's combine the results
List<EveningPlan> moviesAndMeals = new ArrayList<>();
for (int i = 0; i < 3; i++) {
moviesAndMeals.add(new EveningPlan(movies.get(i), meals.get(i)));
}
return moviesAndMeals;
})
.await().atMost(Duration.ofSeconds(60));
}第一个 LLM 是一个 AI 服务,要求提供三个与给定氛围匹配的电影名称。
@RegisterAiService
public interface MovieExpert {
@UserMessage("""
You are a great evening planner.
Propose a list of 3 movies matching the given mood.
The mood is {mood}.
Provide a list with the 3 items and nothing else.
""")
List<String> findMovie(String mood);
}第二个 LLM,具有非常相似的实现,被要求提供三道菜。 当这些 LLM 调用完成时,将聚合结果(3 个项目列表,每个列表 3 个项目),以创建 3 个美妙的夜晚计划列表,每个计划都包含建议的电影和美食。
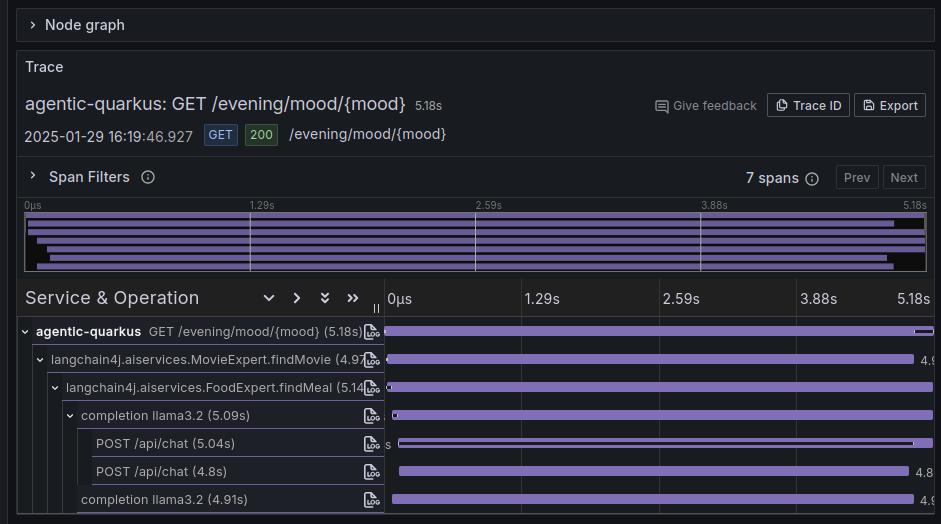
例如,要求该端点提供浪漫氛围的夜晚计划
curl https://:8080/evening/mood/romantic结果如下
[ EveningPlan[movie=1. The Notebook, meal=1. Candlelit Chicken Piccata], EveningPlan[movie=2. La La Land, meal=2. Rose Petal Risotto], EveningPlan[movie=3. Crazy, Stupid, Love., meal=3. Sunset Seared Scallops] ]
在这种情况下,执行的调用流的跟踪表明,两个 LLM 调用如预期的那样并行执行。
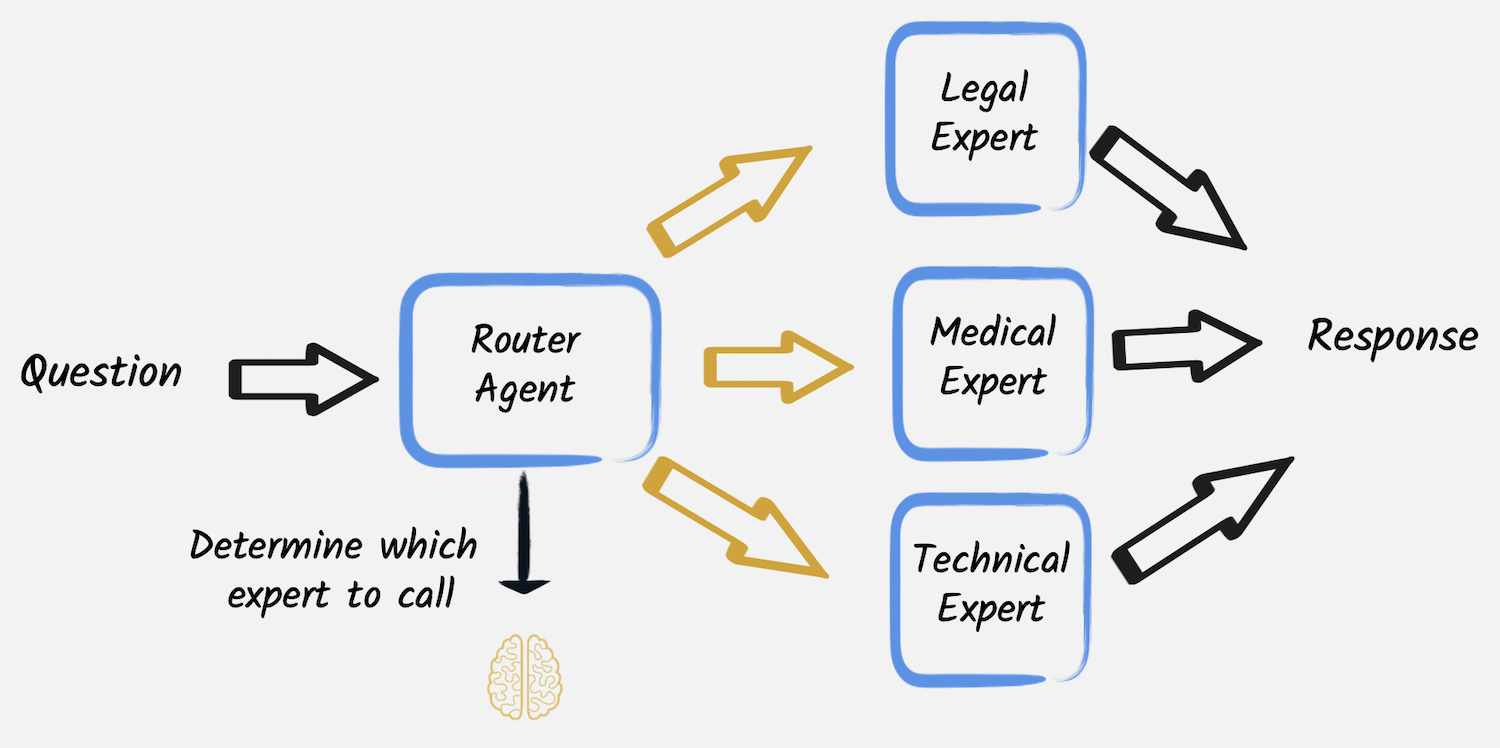
路由
另一种常见情况是需要根据确定的标准将需要特定处理的任务定向到专门的模型、工具或流程。 在这些情况下,路由工作流允许将任务动态分配给最合适的 AI 服务。
@RegisterAiService
public interface MedicalExpert {
@UserMessage("""
You are a medical expert.
Analyze the following user request under a medical point of view and provide the best possible answer.
The user request is {request}.
""")
String chat(String request);
}用户请求的分类由 另一个 LLM 服务 执行
@RegisterAiService
public interface CategoryRouter {
@UserMessage("""
Analyze the following user request and categorize it as 'legal', 'medical' or 'technical'.
Reply with only one of those words and nothing else.
The user request is {request}.
""")
RequestCategory classify(String request);
}该服务返回用户请求的可能类别之一,编码在此枚举中
public enum RequestCategory {
LEGAL, MEDICAL, TECHNICAL, UNKNOWN
}因此,路由器服务 可以将问题发送给正确的专家。
public UnaryOperator<String> findExpert(String request) {
var category = RequestType.decode(categoryRouter.classify(request));
return switch (category) {
case LEGAL -> legalExpert::chat;
case MEDICAL -> medicalExpert::chat;
case TECHNICAL -> technicalExpert::chat;
default -> ignore -> "I cannot find an appropriate category for this request.";
};
}
这样,当用户调用 HTTP 端点,编写类似内容时:“我摔断了腿,我应该怎么办”
curl https://:8080/expert/request/I%20broke%20my%20leg%20what%20should%20I%20do第一个 LLM 将此请求分类为医疗请求,路由器将其转发给医疗专家 LLM,从而生成像 这样 的结果。
